I modify diagonal-ordering to adapt to arbitrary dimension last post and have conclusion
“modified code need extra comparisons in boundary condtion, so it is slower than original code.”
Now I need to correct this statement since I found the way to speedup diagonal-ordering of general form.
the ideas have two parts:
part 1: fixedpoint modulo operation
The original code (below) in SDK/transposeNew use operator % to do modulo operation, this is slow.
[codebox] // do diagonal reordering
if (width == height) {
blockIdx_y = blockIdx.x;
blockIdx_x = (blockIdx.x+blockIdx.y)%gridDim.x;
} else {
int bid = blockIdx.x + gridDim.x*blockIdx.y;
blockIdx_y = bid%gridDim.y;
blockIdx_x = ((bid/gridDim.y)+blockIdx_y)%gridDim.x;
} [/codebox]
I use technique discussing in thread http://forums.nvidia.com/index.php?showtopic=106232
(technique is provided by SPWorley and call it as “fixed-point multiply method” by Sylvain Collange.
later I will call this modulo operation as “fixedpoint method” )
one needs to compute one_over_gx = 2^32/gridDim.x and one_over_gy = 2^32/gridDim.y in host code, then
pass one_over_gx and one_over_gy into kernel function to use integer multiplication to do modulo operation.
The code segment in the kernel function is
[codebox] unsigned int tmp1, tmp2 ;
// do diagonal reordering
if (width == height) {
blockIdx_y = blockIdx.x;
tmp1 = blockIdx.x + blockIdx.y ;
tmp2 = __umulhi( tmp1, one_over_gx );
blockIdx_x = tmp1 - gridDim_x * tmp2 ;
} else {
unsigned int bid = blockIdx.x + gridDim.x*blockIdx.y;
blockIdx_x = __umulhi( bid, one_over_gy );
blockIdx_y = bid - blockIdx_x * gridDim_y ;
bid = blockIdx_x + blockIdx_y ;
tmp1 = __umulhi( bid, one_over_gx );
blockIdx_x = bid - tmp1 * gridDim_x ;
} [/codebox]
and it C-wrapper computes one_over_gx and one_over_gy as
[codebox] dim3 threads(TILE_DIM,BLOCK_ROWS);
dim3 grid( (width+TILE_DIM-1)/TILE_DIM, (height+TILE_DIM-1)/TILE_DIM) ;
double max_int ;
max_int = 4.294967296000000e+009 ; // 2^(32)
unsigned int one_over_gx = (unsigned int) ceil( max_int/((double)grid.x)) ;
unsigned int one_over_gy = (unsigned int) ceil( max_int/((double)grid.y)) ;[/codebox]
part 2: loop unrolling
recall the code method 2 of last post,
method 2: modified diagonal-ordering method, valid for arbitrary N
[codebox] int xIndex = blockIdx_x * TILE_DIM + threadIdx.x;
int yIndex = blockIdx_y * TILE_DIM + threadIdx.y;
int index_in = xIndex + (yIndex)*width;
for (int i=0; i<TILE_DIM; i+=BLOCK_ROWS) {
if( (xIndex < width) && ( (yIndex+i) < height) ){
tile[threadIdx.y+i][threadIdx.x] = idata[index_in+i*width];
}
}
__syncthreads();
xIndex = blockIdx_y * TILE_DIM + threadIdx.x;
yIndex = blockIdx_x * TILE_DIM + threadIdx.y;
int index_out = xIndex + (yIndex)*height;
for (int i=0; i<TILE_DIM; i+=BLOCK_ROWS) {
if( (xIndex < height) && ( (yIndex+i) < width)){
odata[index_out+i*height] = tile[threadIdx.x][threadIdx.y+i];
}
}[/codebox]
My idea is
(1) move condition (xIndex < height) outside for-loop and then
(2) unroll the for-loop manually
for read-operation, the unrolling code is
[codebox] int xIndex = blockIdx_x * TILE_DIM + threadIdx.x;
int yIndex = blockIdx_y * TILE_DIM + threadIdx.y;
int index_in = xIndex + (yIndex)*width;
if( xIndex < width){
int B_mul_w = BLOCK_ROWS*width ;
if ( (yIndex+3*BLOCK_ROWS) < height ){
tile[threadIdx.y ][threadIdx.x] = idata[index_in ];
tile[threadIdx.y + BLOCK_ROWS][threadIdx.x] = idata[index_in + B_mul_w];
tile[threadIdx.y + 2*BLOCK_ROWS][threadIdx.x] = idata[index_in + 2*B_mul_w];
tile[threadIdx.y + 3*BLOCK_ROWS][threadIdx.x] = idata[index_in + 3*B_mul_w];
}else if ( (yIndex+2*BLOCK_ROWS) < height ){
tile[threadIdx.y ][threadIdx.x] = idata[index_in ];
tile[threadIdx.y + BLOCK_ROWS][threadIdx.x] = idata[index_in + B_mul_w];
tile[threadIdx.y + 2*BLOCK_ROWS][threadIdx.x] = idata[index_in + 2*B_mul_w];
}else if ( (yIndex+BLOCK_ROWS) < height ){
tile[threadIdx.y ][threadIdx.x] = idata[index_in ];
tile[threadIdx.y + BLOCK_ROWS][threadIdx.x] = idata[index_in + B_mul_w];
}else if ( yIndex < height ){
tile[threadIdx.y][threadIdx.x] = idata[index_in];
}
}// if (xIndex < weight)
__syncthreads();[/codebox]
for write-operation, the unrolling code is
[codebox] xIndex = blockIdx_y * TILE_DIM + threadIdx.x;
yIndex = blockIdx_x * TILE_DIM + threadIdx.y;
int index_out = xIndex + (yIndex)*height;
if( xIndex < height){
int B_mul_h = BLOCK_ROWS*height ;
if ( (yIndex+3*BLOCK_ROWS) < width ){
odata[index_out ] = tile[threadIdx.x][threadIdx.y ];
odata[index_out + B_mul_h ] = tile[threadIdx.x][threadIdx.y + BLOCK_ROWS];
odata[index_out + 2*B_mul_h ] = tile[threadIdx.x][threadIdx.y + 2*BLOCK_ROWS];
odata[index_out + 3*B_mul_h ] = tile[threadIdx.x][threadIdx.y + 3*BLOCK_ROWS];
}else if ( (yIndex+2*BLOCK_ROWS) < width ){
odata[index_out ] = tile[threadIdx.x][threadIdx.y ];
odata[index_out + B_mul_h ] = tile[threadIdx.x][threadIdx.y + BLOCK_ROWS];
odata[index_out + 2*B_mul_h ] = tile[threadIdx.x][threadIdx.y + 2*BLOCK_ROWS];
}else if ( (yIndex+ BLOCK_ROWS) < width ){
odata[index_out ] = tile[threadIdx.x][threadIdx.y ];
odata[index_out + B_mul_h ] = tile[threadIdx.x][threadIdx.y + BLOCK_ROWS];
}else if ( yIndex < width ){
odata[index_out] = tile[threadIdx.x][threadIdx.y];
}
}// if (xIndex < height)[/codebox]
now I call “diagonal-ordering + fixedpoint + loop-unrolling” as method 3.
Remark: one may wonder why not using “#pragma unroll” and let compiler to do optimization,
however experiment shows no benefit. (I don’t know why, maybe we need to check it PTX code,
so far I don’t want to go such deep further)
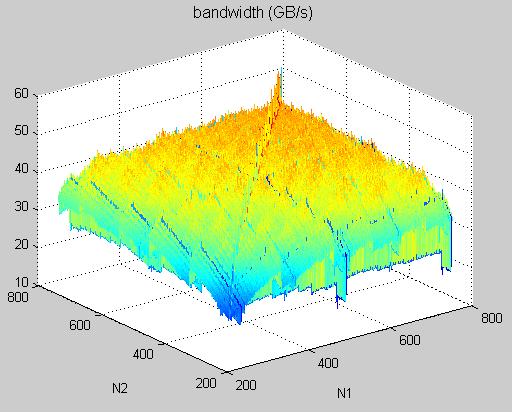
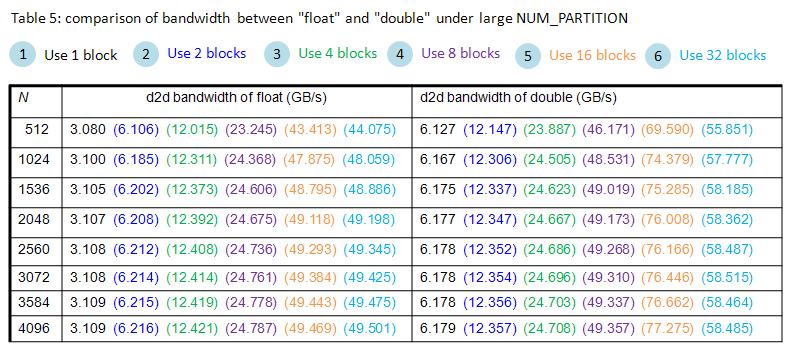
To sum up, we have three methods and do experiment on Tesla C1060 (data of method 1 and method 2
are the same as last post, we just calibrate method 3)
method 1: orignal diagonal-ordering method, only valid for N = multiple of 32
method 2: modified diagonal-ordering method, valid for arbitrary N
method 3: diagonal-ordering + fixedpoint + loop-unrolling
experimental result on Tesla C1060, data type = double
[codebox]-----------±----------------------±----------------------±----------------------+
n1,n2 | GPU method 1 | GPU method 2 | GPU method 3 |
| (time, bandwidth) | (time, bandwidth) | (time, bandwidth) |
-----------±----------------------±----------------------±----------------------+
32, 32 | 0.009 ms, 1.79 GB/s | 0.012 ms, 1.22 GB/s | 0.009 ms, 1.79 GB/s |
-----------±----------------------±----------------------±----------------------+
64,64 | 0.009 ms, 7.09 GB/s | 0.012 ms, 4.93 GB/s | 0.009 ms, 7.07 GB/s |
-----------±----------------------±----------------------±----------------------+
128,128 | 0.011 ms, 22.76 GB/s | 0.013 ms, 19.32 GB/s | 0.011 ms, 22.75 GB/s |
-----------±----------------------±----------------------±----------------------+
256,256 | 0.024 ms, 40.48 GB/s | 0.030 ms, 32.98 GB/s | 0.024 ms, 40.98 GB/s |
-----------±----------------------±----------------------±----------------------+
512,512 | 0.067 ms, 58.62 GB/s | 0.079 ms, 49.31 GB/s | 0.066 ms, 58.75 GB/s |
-----------±----------------------±----------------------±----------------------+
1024,1024 | 0.241 ms, 64.73 GB/s | 0.289 ms, 54.10 GB/s | 0.241 ms, 64.92 GB/s |
-----------±----------------------±----------------------±----------------------+
2048,2048 | 0.941 ms, 66.41 GB/s | 1.122 ms, 55.72 GB/s | 0.940 ms, 66.49 GB/s |
-----------±----------------------±----------------------±----------------------+
4096,4096 | 3.709 ms, 67.41 GB/s | 4.475 ms, 55.87 GB/s | 3.710 ms, 67.38 GB/s |
-----------±----------------------±----------------------±----------------------+
8192,8192 | 14.543 ms, 68.76 GB/s | 17.963 ms, 55.67 GB/s | 14.550 ms, 68.73 GB/s |
-----------±----------------------±----------------------±----------------------+ [/codebox]
now method 3 is almost the same as method 1 (remember method 1 only works for N = multiple of 32).
second, we answer question “why does performance degradation of “diagonal ordering†occur at N+1 = multiple of 256?”
last post. In fact, diagonal-ordering has two slow curves, one is (N+1) = multiple of 256, the other is
(N-128+1) is multiple of 256. Also coalesced method has two slow curves, one is N = multiple of 256,
the other is (N-128) is multiple of 256, we show them in figure 15
figure 15
We only use a simple example to show slowest curve in diagonal-ordering method on last post,
we will describe second slow curve later.
now we can propose a hybridized method which combines method 1 and method 3.
the criterion of hybridized method is
if (N+1) = multiple of 256 or (N-128+1) is multiple of 256, then use “Coalesced method”,
otherwise use “diagonal-ordering + fixedpoint + loop-unrolling”
figure 16 shows experiment results
Question: what is optimal result of hybridized method?
Ans: we can choose maximum bandwidth among Coalesced and diagonal-ordering (see figure 17),
however it is difficult to achieve since index leading to optimal is not regular
figure 17

third I want to depict what happens when (N+1) = multiple of 256 and (N-128+1) is multiple of 256, since
diagonal-ordering has two slow curves, one is (N+1) = multiple of 256, the other is
(N-128+1) is multiple of 256.
I try to use cartoon figures to describe what I want to express and hope that everyone can understand.
first let us focus on the case (N+1) = multiple of 256, here I take N = 255.
remember that global memory has 8 partitions of 32-double width. given a 255 x 255 matrix A,
each matrix element corresponds to one partition, we use 8 colors to represent 8 partitions respectively
and draw each matrix element with one color in figure 18.
figure 18
note that each row of matrix A has only 255 doubles, so A(2,1) is labeled as partition 7.
in the kernel function, tile has dimension 32 x 32, but only use 32 x 8 = 256 threads to handle one tile.
we group 32 x 32 data elements as one tile in figure 19.
figure 19
then we fill each blocks with proper index, in figure 20, we use Cartesian coordinate
to label index.
figure 20
it is not difficult to find that each block has the same configuration, then we can consider
one set of active blocks to estimate performance of bandwidth.
moreover under Cartesian coordinate, block 0 ~ 7 (active) occupy 8 partitions, so bandwith is high.
























































{kind=link}