Hi @AastaLLL
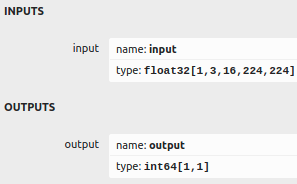
The input of the model is 1x3x16x224x224. Yes, Your understanding is correct; We do concatenate 16 images that have 3 channels and the resolution is 224x224. This is similar to the action recognition 3d sample app’s 3d model’s input.
I have run the model with trtexec to get the input/output shape which you can find below,
$ /usr/src/tensorrt/bin/trtexec --onnx=bs1_march22_fd.onnx --dumpOutput
&&&& RUNNING TensorRT.trtexec [TensorRT v8001] # /usr/src/tensorrt/bin/trtexec --onnx=bs1_march22_fd.onnx --dumpOutput
...
[03/25/2022-11:45:07] [I] Engine built in 29.1877 sec.
[03/25/2022-11:45:07] [I] [TRT] [MemUsageSnapshot] ExecutionContext creation begin: CPU 1362 MiB, GPU 24932 MiB
[03/25/2022-11:45:07] [I] [TRT] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +7, now: CPU 1362, GPU 24939 (MiB)
[03/25/2022-11:45:07] [I] [TRT] [MemUsageChange] Init cuDNN: CPU +0, GPU +10, now: CPU 1362, GPU 24949 (MiB)
[03/25/2022-11:45:07] [I] [TRT] [MemUsageSnapshot] ExecutionContext creation end: CPU 1364 MiB, GPU 25060 MiB
[03/25/2022-11:45:07] [I] Created input binding for input with dimensions 1x3x16x224x224
[03/25/2022-11:45:07] [I] Created output binding for output with dimensions 1
[03/25/2022-11:45:07] [I] Starting inference
[03/25/2022-11:45:11] [I] Warmup completed 3 queries over 200 ms
[03/25/2022-11:45:11] [I] Timing trace has 37 queries over 3.20196 s
[03/25/2022-11:45:11] [I]
[03/25/2022-11:45:11] [I] === Trace details ===
[03/25/2022-11:45:11] [I] Trace averages of 10 runs:
[03/25/2022-11:45:11] [I] Average on 10 runs - GPU latency: 86.5952 ms - Host latency: 86.9179 ms (end to end 87.02 ms, enqueue 35.0739 ms)
[03/25/2022-11:45:11] [I] Average on 10 runs - GPU latency: 84.4766 ms - Host latency: 84.802 ms (end to end 84.8117 ms, enqueue 34.946 ms)
[03/25/2022-11:45:11] [I] Average on 10 runs - GPU latency: 85.9088 ms - Host latency: 86.2366 ms (end to end 86.2853 ms, enqueue 35.4646 ms)
[03/25/2022-11:45:11] [I]
[03/25/2022-11:45:11] [I] === Performance summary ===
[03/25/2022-11:45:11] [I] Throughput: 11.5554 qps
[03/25/2022-11:45:11] [I] Latency: min = 80.5767 ms, max = 91.0549 ms, mean = 86.4912 ms, median = 88.2876 ms, percentile(99%) = 91.0549 ms
[03/25/2022-11:45:11] [I] End-to-End Host Latency: min = 80.5886 ms, max = 91.0654 ms, mean = 86.5394 ms, median = 88.3589 ms, percentile(99%) = 91.0654 ms
[03/25/2022-11:45:11] [I] Enqueue Time: min = 19.5367 ms, max = 52.9646 ms, mean = 35.77 ms, median = 44.0358 ms, percentile(99%) = 52.9646 ms
[03/25/2022-11:45:11] [I] H2D Latency: min = 0.260986 ms, max = 0.385742 ms, mean = 0.325974 ms, median = 0.374298 ms, percentile(99%) = 0.385742 ms
[03/25/2022-11:45:11] [I] GPU Compute Time: min = 80.1975 ms, max = 90.7883 ms, mean = 86.164 ms, median = 88.0197 ms, percentile(99%) = 90.7883 ms
[03/25/2022-11:45:11] [I] D2H Latency: min = 0.000976562 ms, max = 0.0032959 ms, mean = 0.00118194 ms, median = 0.00109863 ms, percentile(99%) = 0.0032959 ms
[03/25/2022-11:45:11] [I] Total Host Walltime: 3.20196 s
[03/25/2022-11:45:11] [I] Total GPU Compute Time: 3.18807 s
[03/25/2022-11:45:11] [I] Explanations of the performance metrics are printed in the verbose logs.
[03/25/2022-11:45:11] [I]
[03/25/2022-11:45:11] [I] Output Tensors:
[03/25/2022-11:45:11] [I] output: (1)
[03/25/2022-11:45:11] [I] 0
&&&& PASSED TensorRT.trtexec [TensorRT v8001] # /usr/src/tensorrt/bin/trtexec --onnx=bs1_march22_fd.onnx --dumpOutput
[03/25/2022-11:45:11] [I] [TRT] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +0, now: CPU 1362, GPU 24981 (MiB)
As you can see the input output shape,
Created input binding for input with dimensions 1x3x16x224x224
Created output binding for output with dimensions 1
This trtexec provides correct i/o shape unlike the .engine model shape in Deepstream pipeline.
I hope this gives you better sense of the issue.
How do i resolve this?
Inline to above approach, I had saved the engine using trtexec which has the correct input output shape. However, when i load the same engine file in Deepstream pipeline It gives the same error as earlier.
$ sudo deepstream-3d-action-recognition -c deepstream_action_recognition_config.txt
num-sources = 1
Now playing: file:///test.mp4,
Using winsys: x11
0:00:03.249616116 16276 0x558fd2a810 INFO nvinfer gstnvinfer.cpp:638:gst_nvinfer_logger:<primary-nvinference-engine> NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::deserializeEngineAndBackend() <nvdsinfer_context_impl.cpp:1900> [UID = 1]: deserialized trt engine from :/opt/nvidia/deepstream/deepstream-6.0/sources/apps/sample_apps/h_work_deepstream-3d-action-recognition/try.engine
INFO: [Implicit Engine Info]: layers num: 2
0 INPUT kFLOAT input 3x16x224x224
1 OUTPUT kINT32 output 0
0:00:03.249795388 16276 0x558fd2a810 INFO nvinfer gstnvinfer.cpp:638:gst_nvinfer_logger:<primary-nvinference-engine> NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::generateBackendContext() <nvdsinfer_context_impl.cpp:2004> [UID = 1]: Use deserialized engine model: /opt/nvidia/deepstream/deepstream-6.0/sources/apps/sample_apps/h_work_deepstream-3d-action-recognition/try.engine
0:00:03.253819158 16276 0x558fd2a810 ERROR nvinfer gstnvinfer.cpp:632:gst_nvinfer_logger:<primary-nvinference-engine> NvDsInferContext[UID 1]: Error in NvDsInferContextImpl::allocateBuffers() <nvdsinfer_context_impl.cpp:1430> [UID = 1]: Failed to allocate cuda output buffer during context initialization
0:00:03.253901626 16276 0x558fd2a810 ERROR nvinfer gstnvinfer.cpp:632:gst_nvinfer_logger:<primary-nvinference-engine> NvDsInferContext[UID 1]: Error in NvDsInferContextImpl::initialize() <nvdsinfer_context_impl.cpp:1280> [UID = 1]: Failed to allocate buffers
0:00:03.268127274 16276 0x558fd2a810 WARN nvinfer gstnvinfer.cpp:841:gst_nvinfer_start:<primary-nvinference-engine> error: Failed to create NvDsInferContext instance
0:00:03.268186509 16276 0x558fd2a810 WARN nvinfer gstnvinfer.cpp:841:gst_nvinfer_start:<primary-nvinference-engine> error: Config file path: config_infer_primary_3d_action.txt, NvDsInfer Error: NVDSINFER_CUDA_ERROR
Running...
ERROR from element primary-nvinference-engine: Failed to create NvDsInferContext instance
Error details: /dvs/git/dirty/git-master_linux/deepstream/sdk/src/gst-plugins/gst-nvinfer/gstnvinfer.cpp(841): gst_nvinfer_start (): /GstPipeline:preprocess-test-pipeline/GstNvInfer:primary-nvinference-engine:
Config file path: config_infer_primary_3d_action.txt, NvDsInfer Error: NVDSINFER_CUDA_ERROR
Returned, stopping playback
Deleting pipeline
Please help me out with the same.
Thanks & Regards,
Hemang Jethava