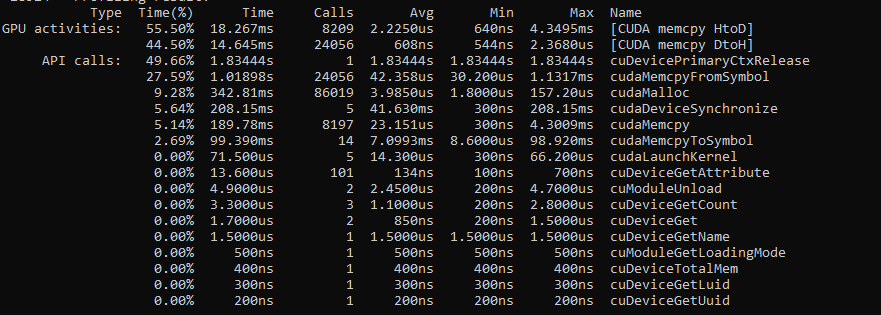
Hello:
I have a doubt regarding performance on a CUDA code I’m working on.
So, I have a function calc that triggers an external kernel function kernel.
This kernel function expects three data array, and then it makes calculation on each paired item.
After calling that function, I want to perform some checks on the results, so for now the only way I have is to copy the memory from device to host, and then perform the checks on CPU.
I was wondering if it’s worth to somehow wrap all with a kernel function and then perform the checks there, as the kernel function is part of an external source and I don’t have direct access to freely modify it.
As an example, I created a very simillar situation with a minimal code to reproduce my case:
#include "stdio.h"
#include "stdlib.h"
#include "conio.h"
#include "time.h"
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
//memory setting
void h2d(void** device, void* host, int quantity, int type);
void d2h(void* host, void* device, int quantity);
//calculation
void operate(int* a, int* b, char* o, int x, int y, int count);
//CUDA calc
__global__ void kernel(int* a, int* b, char* o, int count);
int main(){
//dimension
int x = 16;
int y = 16;
int k = 4;
int i = 0;
int t = 0;
//host
int* a = (int*)malloc(sizeof(int) * k * k);
int* b = (int*)malloc(sizeof(int) * k * k);
char* o = (char*)malloc(sizeof(char) * k * k);
//device
int* da = NULL;
int* db = NULL;
char* dop = NULL;
//random init
srand(time(NULL));
printf("Loading ints...\n");
//memory check
if (a == NULL || b == NULL || o == NULL) {
printf("Memory error!\n");
return -1;
}
for (i = 0; i < k * k; i++) {
//a and b are [2, 1000]
a[i] = rand() % (1000 - 2 + 1) + 2;
b[i] = rand() % (1000 - 2 + 1) + 2;
//t is [0, 3]
t = rand() % 4;
if (t == 0)
o[i] = '+';
else if (t == 1)
o[i] = '-';
else if (t == 2)
o[i] = '*';
else
o[i] = '/';
}
printf("#op\ta\tb\to\n");
for (i = 0; i < k * k; i++)
printf("%i\t%i\t%i\t%c\n", i, a[i], b[i], o[i]);
//move to device
h2d((void**)&da, a, k * k, 0);
h2d((void**)&db, b, k * k, 0);
h2d((void**)&dop, o, k * k, 1);
//call to CUDA
operate(da, db, dop, x, y, k * k);
//back to host
d2h(a, da, k * k);
//perform some additional operations
/*
for (i = 0; i < k * k; i++){
//some code
}
//calculate again
h2d(...)
operate(...)
d2h(...)
for (i = 0; i < k * k; i++){
//some code
}
//calculate again
h2d(...)
operate(...)
d2h(...)
...
*/
printf("#r\tr\n");
for (i = 0; i < k * k; i++)
printf("%i\t%i\n", i, a[i]);
return 0;
}
//copies host memory to device
void h2d(void** device, void* host, int quantity, int type) {
size_t sz;
if (quantity <= 0)
return;
if (type == 0)
sz = sizeof(int);
else if (type == 1)
sz = sizeof(char);
else
return;
cudaMalloc(device, sz * quantity);
cudaMemcpy(*device, host, sz * quantity, cudaMemcpyHostToDevice);
}
//copies device to host memory
void d2h(void* host, void* device, int quantity) {
if (quantity <= 0)
return;
cudaMemcpy(host, device, sizeof(int) * quantity, cudaMemcpyDeviceToHost);
}
//operates
void operate(int* a, int* b, char* o, int x, int y, int count) {
if (x <= 0 || y <= 0)
return;
if (count <= 0)
return;
kernel<<<x, y>>>(a, b, o, count);
//wait to sync
cudaDeviceSynchronize();
}
__global__ void kernel(int* a, int* b, char* o, int count) {
int i = 0;
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int inc = blockDim.x * gridDim.x;
//https://developer.nvidia.com/blog/even-easier-introduction-cuda/
for (i = idx;i < count;i += inc){
if (o[i] == '+')
a[i] += b[i];
else if (o[i] == '-')
a[i] -= b[i];
else if (o[i] == '*')
a[i] *= b[i];
else if (o[i] == '/')
a[i] /= b[i];
else
continue;
}
}
On my situation, I want to check and ammend a values after cudaDeviceSynchronize() then call again the kernel (this can repeat several times), so what I was wondering is if something like this would improve the performance for larger data quantities:
//operates
void operate(int* a, int* b, char* o, int x, int y, int count) {
if (x <= 0 || y <= 0)
return;
if (count <= 0)
return;
customKernel<<<1, 1>>>(a, b, o, x, y, count);
//wait to sync
cudaDeviceSynchronize();
}
__global__ customKernel(int* a, int* b, char* o, int x, int y, int count){
if(blockIdx.x == 0 && threadIdx.x == 0){
//only do it once
kernel<<<x, y>>>(a, b, o);
//wait to sync
cudaDeviceSynchronize();
//additional operations
/*
for (i = 0; i < count; i++){
//some code
}
kernel<<<x, y>>>(a, b, o);
//wait to sync
cudaDeviceSynchronize();
...
*/
}
}
So, as it does not need to syncronize memory back and forth and all the job is done on GPU, does it will improve the performance? or as it will be doing some kernel operations it won’t?
Thanks.