• Hardware Platform (Jetson / GPU): Jetson NX Dev Kit
• DeepStream Version: 6.0.1
• JetPack Version (valid for Jetson only): 4.6 GA
Hi Sir/Madam:
Background
This question starts from this old question: Does the Probe Function in Deepstream have to be blocking?. In my project, I was also confused with heavy calculation time within probe function. And like above question mentioned, and here, it is confirmed that probe() callbacks are synchronous and thus holds the buffer (info.get_buffer()) from traversing the pipeline until user return.
So, I tried three ways to see whether we could build a “new” thread and put all heavy codes inside. In this question, I will only explain the first way, by using tee, queue, Appsink. From my test results, I didn’t see the function of Appsink works as expected. I will first explain what I did, and then show all codes at the end, so that you could help to re-produce results.
I am wondering whether anyone could help to review my codes and results to see whether Appsink can help the block problem of Probe Function in Deepstream or not.
Logics behind
- First, we need to create a pipeline like below:
Core part of above image:
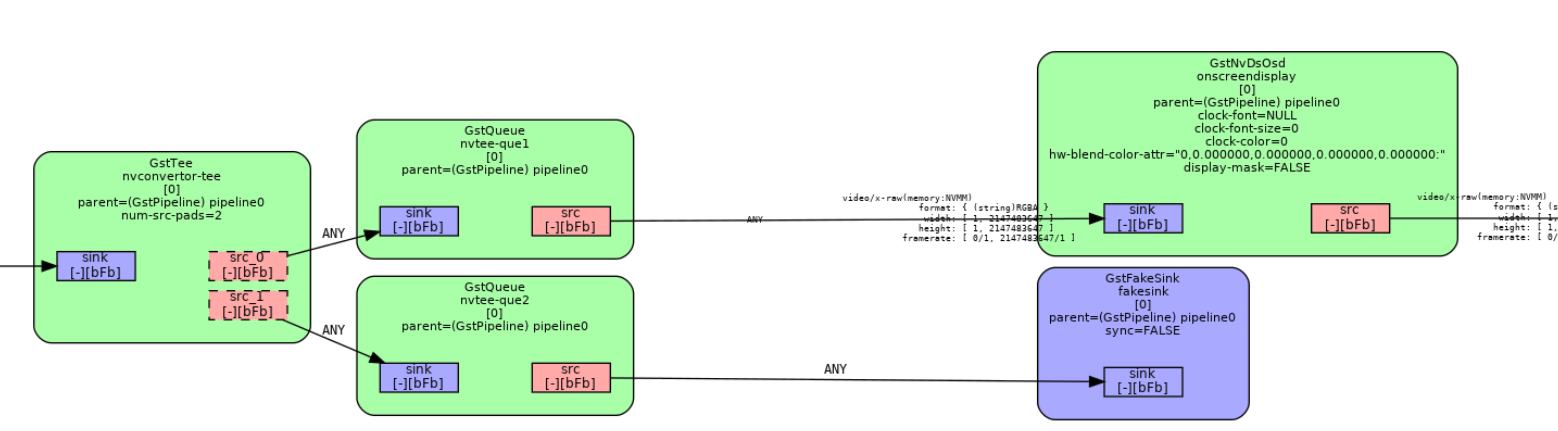
So, I tried to create tee after nvinfer and gsdvideoconvert, before osd. For one queue, it is connected to osd, and the other queue is connected to Appsink. Property of the second queue is 2, with parameter Leaky.
-
Next, inside function new_buffer, which is connected by Appsink:
appsink.connect("new-sample", new_buffer), I tried to write some delays, in order to simulate the situation where heavy calculations inside Appsink. -
Probe function is created towards osd:
osdsinkpad = nvosd.get_static_pad("sink");osdsinkpad.add_probe(Gst.PadProbeType.BUFFER, osd_sink_pad_buffer_probe, 0).
There are some details missed, but I will paste all codes below. I would expect to see real time video displayed in local screen. But it is not, after I tried many times.
How to Reproduce
These code are based on deepstream_test_1.py. After copy and paste codes below, you could try to reproduce by typing python3 deepstream_test_1.py /opt/nvidia/deepstream/deepstream-6.0/samples/streams/sample_qHD.h264 in terminal. I did’t use container.
Codes
Codes for deepstream_test_1.py:
#!/usr/bin/env python3
import sys
sys.path.append('../')
import gi
gi.require_version('Gst', '1.0')
from gi.repository import GObject, Gst
from common.is_aarch_64 import is_aarch64
from common.bus_call import bus_call
from post_processing import PostProcessing
import time
import cv2
import numpy
import pyds
import os
os.environ["GST_DEBUG_DUMP_DOT_DIR"] = "/tmp"
os.putenv('GST_DEBUG_DUMP_DIR_DIR', '/tmp')
PGIE_CLASS_ID_VEHICLE = 0
PGIE_CLASS_ID_BICYCLE = 1
PGIE_CLASS_ID_PERSON = 2
PGIE_CLASS_ID_ROADSIGN = 3
# Notice,I deleted original comments since nothing changed. And add new comments for changes.
# In this secario, I set 1 sec delay in Appsink new_buffer function, to simulate heavy calculation condition.
# If Appsink calculation speed does not influence the main pipeline system work, then you should expect the video stream display on local screen with real time
# and print message display in terminal with FPS frequency.
# However, what I see is the stuck screen, and print message with frequency 1 Hz.
def osd_sink_pad_buffer_probe(pad,info,u_data):
frame_number=0
num_rects=0
objectdetect = {}
gst_buffer = info.get_buffer()
if not gst_buffer:
print("Unable to get GstBuffer ")
return
batch_meta = pyds.gst_buffer_get_nvds_batch_meta(hash(gst_buffer))
l_frame = batch_meta.frame_meta_list
while l_frame is not None:
try:
frame_meta = pyds.NvDsFrameMeta.cast(l_frame.data)
except StopIteration:
break
frame_number=frame_meta.frame_num
num_rects = frame_meta.num_obj_meta
l_obj=frame_meta.obj_meta_list
while l_obj is not None:
try:
obj_meta=pyds.NvDsObjectMeta.cast(l_obj.data)
except StopIteration:
break
BB_info = obj_meta.rect_params
objectdetect.update({obj_meta.class_id: [BB_info.left,BB_info.top,BB_info.left+BB_info.width,BB_info.top+BB_info.height]})
obj_meta.rect_params.border_color.set(0.0, 0.0, 1.0, 0.0)
try:
l_obj=l_obj.next
except StopIteration:
break
# Send data to post_processing object.
pp.pushAllMeta(frame_number, num_rects, objectdetect)
# Get data from post_processing object.
# Notice, although pushAllMeta function and getMeta function are just in consequent line, what the metadata get
# from getMeta function is in fact the results after postProcessingMain function.
display_frameNum, display_numRects, display_objCounter = pp.getMeta()
if display_objCounter != None:
display_meta=pyds.nvds_acquire_display_meta_from_pool(batch_meta)
display_meta.num_labels = 1
py_nvosd_text_params = display_meta.text_params[0]
# Display the parameters after getMeta function.
py_nvosd_text_params.display_text = "Frame Number={} Number of Objects={} Vehicle_count={} Person_count={}".format(display_frameNum, display_numRects, display_objCounter[PGIE_CLASS_ID_VEHICLE], display_objCounter[PGIE_CLASS_ID_PERSON])
py_nvosd_text_params.x_offset = 10
py_nvosd_text_params.y_offset = 12
py_nvosd_text_params.font_params.font_name = "Serif"
py_nvosd_text_params.font_params.font_size = 10
py_nvosd_text_params.font_params.font_color.set(1.0, 1.0, 1.0, 1.0)
py_nvosd_text_params.set_bg_clr = 1
py_nvosd_text_params.text_bg_clr.set(0.0, 0.0, 0.0, 1.0)
# Display on terminal.
print(pyds.get_string(py_nvosd_text_params.display_text))
pyds.nvds_add_display_meta_to_frame(frame_meta, display_meta)
try:
l_frame=l_frame.next
except StopIteration:
break
return Gst.PadProbeReturn.OK
# Not used in order to make test results more clear.
def gst_to_opencv(sample):
buf = sample.get_buffer()
caps = sample.get_caps()
print (caps.get_structure(0).get_value('format'))
print (caps.get_structure(0).get_value('height'))
print (caps.get_structure(0).get_value('width'))
print (buf.get_size())
arr = numpy.ndarray(
(caps.get_structure(0).get_value('height'),
caps.get_structure(0).get_value('width'),
3),
buffer=buf.extract_dup(0, buf.get_size()),
dtype=numpy.uint8)
return arr
# This function is Appsink buffer function. Main usage of postProcessingMain is just to delay 1 second per time.
def new_buffer(sink):
global image_arr
sample = sink.emit("pull-sample")
# buf = sample.get_buffer()
# print "Timestamp: ", buf.pts
#arr = gst_to_opencv(sample)
#image_arr = arr
pp.postProcessingMain()
return Gst.FlowReturn.OK
def main(args):
global pp
if len(args) != 2:
sys.stderr.write("usage: %s <media file or uri>\n" % args[0])
sys.exit(1)
GObject.threads_init()
Gst.init(None)
print("Creating Pipeline \n ")
pipeline = Gst.Pipeline()
if not pipeline:
sys.stderr.write(" Unable to create Pipeline \n")
print("Creating Source \n ")
source = Gst.ElementFactory.make("filesrc", "file-source")
if not source:
sys.stderr.write(" Unable to create Source \n")
print("Creating H264Parser \n")
h264parser = Gst.ElementFactory.make("h264parse", "h264-parser")
if not h264parser:
sys.stderr.write(" Unable to create h264 parser \n")
print("Creating Decoder \n")
decoder = Gst.ElementFactory.make("nvv4l2decoder", "nvv4l2-decoder")
if not decoder:
sys.stderr.write(" Unable to create Nvv4l2 Decoder \n")
streammux = Gst.ElementFactory.make("nvstreammux", "Stream-muxer")
if not streammux:
sys.stderr.write(" Unable to create NvStreamMux \n")
pgie = Gst.ElementFactory.make("nvinfer", "primary-inference")
if not pgie:
sys.stderr.write(" Unable to create pgie \n")
nvvidconv = Gst.ElementFactory.make("nvvideoconvert", "convertor")
if not nvvidconv:
sys.stderr.write(" Unable to create nvvidconv \n")
# splits data to multiple pads, like multi-thread.
tee=Gst.ElementFactory.make("tee", "nvconvertor-tee")
if not tee:
sys.stderr.write(" Unable to create tee DS pipeline module.")
# Queue to main pipeline
queue1=Gst.ElementFactory.make("queue", "nvtee-que1")
if not queue1:
sys.stderr.write(" Unable to create queue1 DS pipeline module.")
nvosd = Gst.ElementFactory.make("nvdsosd", "onscreendisplay")
if not nvosd:
sys.stderr.write(" Unable to create nvosd \n")
# Queue to Appsink
queue2=Gst.ElementFactory.make("queue", "nvtee-que2")
# Set the leaky to 2. I also tried to set it into 0. I didn't see difference.
queue2.set_property("leaky", 2)
if not queue2:
sys.stderr.write(" Unable to create queue2 DS pipeline module.")
if is_aarch64():
transform = Gst.ElementFactory.make("nvegltransform", "nvegl-transform")
print("Creating EGLSink \n")
sink = Gst.ElementFactory.make("nveglglessink", "nvvideo-renderer")
if not sink:
sys.stderr.write(" Unable to create egl sink \n")
# Appsink. I also tried to set change/uncomment properties below, but I didn't see difference.
appsink = Gst.ElementFactory.make("appsink", "sink")
appsink.set_property("emit-signals",True)
appsink.set_property("max-buffers", 2)
appsink.set_property("drop", True)
appsink.set_property("sync", False)
# Uncomment first. Will not influence results.
#caps = Gst.caps_from_string("video/x-raw, format=(string){BGR, GRAY8}; video/x-bayer,format=(string){rggb,bggr,grbg,gbrg}")
#caps = Gst.caps_from_string("video/x-raw, format=(string)BGR")
#appsink.set_property("caps", caps)
appsink.connect("new-sample", new_buffer)
print("Playing file %s " %args[1])
source.set_property('location', args[1])
streammux.set_property('width', 1920)
streammux.set_property('height', 1080)
streammux.set_property('batch-size', 1)
streammux.set_property('batched-push-timeout', 4000000)
pgie.set_property('config-file-path', "dstest1_pgie_config.txt")
print("Adding elements to Pipeline \n")
pipeline.add(source)
pipeline.add(h264parser)
pipeline.add(decoder)
pipeline.add(streammux)
pipeline.add(pgie)
pipeline.add(nvvidconv)
pipeline.add(tee)
pipeline.add(queue1)
pipeline.add(queue2)
pipeline.add(nvosd)
pipeline.add(sink)
pipeline.add(appsink)
if is_aarch64():
pipeline.add(transform)
# we link the elements together
# file-source -> h264-parser -> nvh264-decoder ->
# nvinfer -> nvvidconv -> nvosd -> video-renderer
print("Linking elements in the Pipeline \n")
source.link(h264parser)
h264parser.link(decoder)
sinkpad = streammux.get_request_pad("sink_0")
if not sinkpad:
sys.stderr.write(" Unable to get the sink pad of streammux \n")
srcpad = decoder.get_static_pad("src")
if not srcpad:
sys.stderr.write(" Unable to get source pad of decoder \n")
srcpad.link(sinkpad)
streammux.link(pgie)
pgie.link(nvvidconv)
nvvidconv.link(tee)
src_tee_osd_pad = tee.get_request_pad("src_%u")
src_tee_appsink_pad = tee.get_request_pad("src_%u")
sink_osd_pad = queue1.get_static_pad("sink")
sink_appsink_pad = queue2.get_static_pad("sink")
src_tee_osd_pad.link(sink_osd_pad)
src_tee_appsink_pad.link(sink_appsink_pad)
# link tee, queue and appsink
queue1.link(nvosd)
queue2.link(appsink)
if is_aarch64():
nvosd.link(transform)
transform.link(sink)
else:
nvosd.link(sink)
# object of Postprocessing
pp = PostProcessing()
loop = GObject.MainLoop()
bus = pipeline.get_bus()
bus.add_signal_watch()
bus.connect ("message", bus_call, loop)
osdsinkpad = nvosd.get_static_pad("sink")
if not osdsinkpad:
sys.stderr.write(" Unable to get sink pad of nvosd \n")
osdsinkpad.add_probe(Gst.PadProbeType.BUFFER, osd_sink_pad_buffer_probe, 0)
#Gst.debug_bin_to_dot_file(pipeline, Gst.DebugGraphDetails.ALL, "pipeline")
print("Starting pipeline \n")
pipeline.set_state(Gst.State.PLAYING)
try:
loop.run()
except:
pass
pipeline.set_state(Gst.State.NULL)
if __name__ == '__main__':
sys.exit(main(sys.argv))
Codes for post_processing.py
import threading
import time
PGIE_CLASS_ID_VEHICLE = 0
PGIE_CLASS_ID_BICYCLE = 1
PGIE_CLASS_ID_PERSON = 2
PGIE_CLASS_ID_ROADSIGN = 3
class PostProcessing(object):
def __init__(self):
self.objectdetect = None
self.objectdetect_new = None
self.frame_number = 0
self.frame_number_new = 0
self.num_rects = 0
self.num_rects_new = 0
self.obj_counter = None
def pushAllMeta(self, frame_number, num_rects, objectdetect):
self.frame_number_new = frame_number
self.num_rects_new = num_rects
self.objectdetect_new = objectdetect
def getMeta(self):
return self.frame_number, self.num_rects, self.obj_counter
def postProcessingMain(self):
self.obj_counter = {
PGIE_CLASS_ID_VEHICLE:0,
PGIE_CLASS_ID_PERSON:0,
PGIE_CLASS_ID_BICYCLE:0,
PGIE_CLASS_ID_ROADSIGN:0
}
if self.objectdetect_new == None:
return
else:
for key, value in self.objectdetect_new.items():
self.obj_counter[key] += 1
self.frame_number = self.frame_number_new
self.num_rects = self.num_rects_new
self.objectdetect = self.objectdetect_new
time.sleep(1)
Thanks a lot for your help.
Best
Yichao