We are experiencing occasional reboot issues with Xavier devices in a large-scale deployment. Below are the details:
- Failure Frequency: In a batch of 56 devices, 7 reboots occurred over a period of 30 days.
- Possible Trigger: We found that a rapid 0.5V drop in input voltage can sometimes cause a reboot, but this is not confirmed as the root cause.
- Log Analysis: System logs contain some abnormal messages, but these messages also appear on devices that run without issues, so they don’t fully correlate with the reboot events.
- Hardware Design: We only use Xavier’s core components, and all external peripherals (including the power module) are custom-designed.
Additional Information:
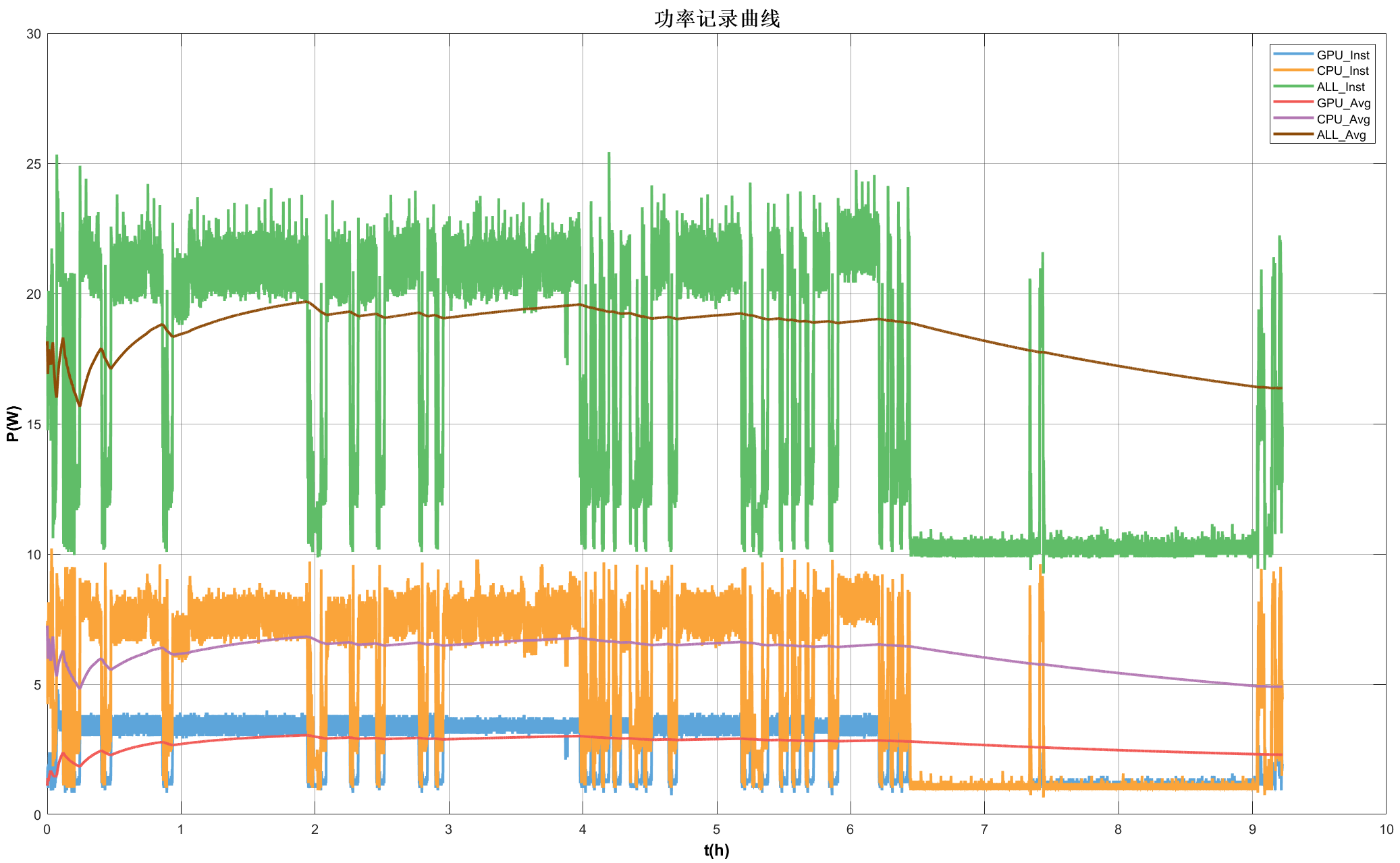
- We conducted CPU and GPU load tests, but the issue could not be triggered.
- We printed the application’s worker ID changes over the course of an overnight idle period, hoping it could help with the analysis.
- Device info: Xavier AGX 32GB/JetPack 4.6.3
Questions:
- What are the potential causes of unexpected reboots in Xavier devices?
- Are there any recommended debugging steps to identify whether the reboot is caused by power issues, software crashes, or hardware failures?
- Is there a way to check if the PMIC or another subsystem is triggering the reboot?
- Can any software operations (not system commands, but regular applications) trigger a system reboot on Xavier devices?
- Could memory fragmentation possibly be causing this issue?
Any insights or recommendations would be greatly appreciated! I will attach system log screenshots for reference.



