That should automatically get set to what --resolution argument is set to when ssd-mobilenet-v1 is used. If print out the value of size in the Resize object’s constructor, does it change when you change the --resolution argument?
Print gives 512 :)

I Understood that the right point to chose model is approx at 90th epoch.
Any ideas what this classification validation loss means which i marked red? I think it shows that model has gained some accuracy but in validation the model in unstable - but … is this point where I have trained the model too much or should i wait until it lowers more and becomes stable?
I’ve not trained ssd-mobilenet for more than 100 epochs, so I can’t say for sure, but the tapering of all of the loss curves would seem to indicate convergence of the training around epoch 120 for your dataset (so you may want to call that good to prevent overfitting). Otherwise you may need to experiment more with the learning rate scheduling after epoch 120 to further decrease the learning rate.
thnx. I thought so.
Actually - i thought that using SSD Mobilnet V1 and 512 resolution shows me better small objects and stripes on images. But … SSD mobilnet V2 is performing extremely well and it doesn’t consume too much system resources. I understood that by default V2 is having resolution 224x224 and still wondering how it works so well :)
Are you referring to the SSD-Mobilenet-v2 that train_ssd.py trains with PyTorch, or the default SSD-Mobilenet-v2 COCO model that comes with jetson-inference (which came from TensorFlow in UFF format)? Regardless, IIRC the default resolution for both is 300x300.
I use this mb2-ssd-lite-mp-0_686.pth and use same train_ssd.py from pytorch-ssd while training. I made there some adjustments, compared it with jetson-inference training scripts. So, i’m not sure. I thought that v2 takes as input image 224x224 - but is this “input image” used in different contest or i misunderstood something? :)
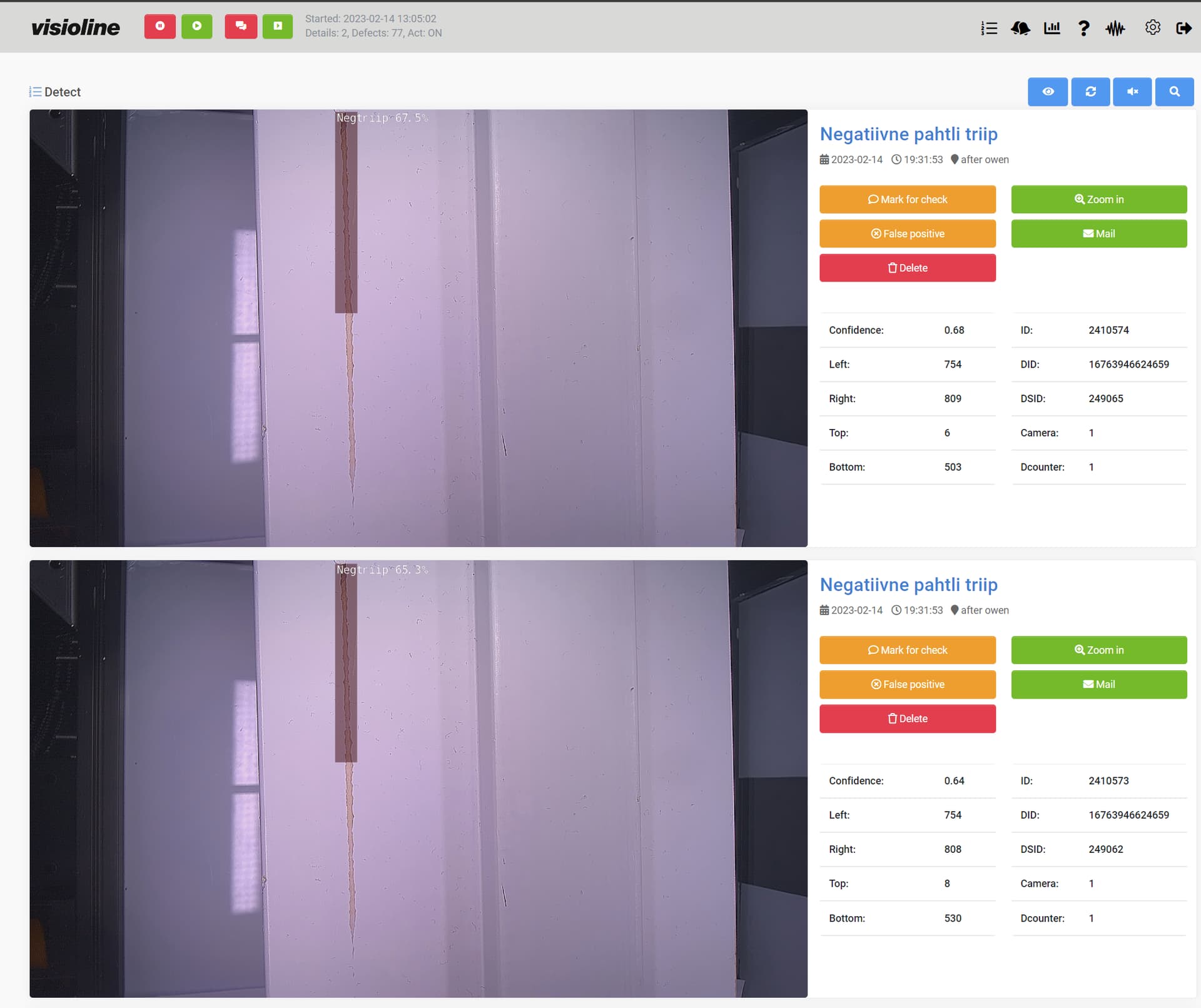
I added some pics also - maybe it is interesting for you. At the moment I’m struggling how to detect those negative light gray stripes (marked green):

Just for illustrations:


In the model setup, SSD-Mobilenet-v2 uses the same config as SSD-Mobilenet-v1, so I think it is 300x300: https://github.com/dusty-nv/pytorch-ssd/blob/21383204c68846bfff95acbbd93d39914a77c707/train_ssd.py#L238
You may be able to add config.set_image_size(args.resolution) to here so that SSD-Mobilenet-v2 responds to the --resolution command-line argument, but I’m not sure.
I’m curious that when you said SSD-Mobilenet-v2 was performing extremely well, did you mean that it was more accurate? My benchmarking showed the runtime performance to be basically the same as -v1, but I didn’t try this scenario with small objects. You objects seem to have a very small aspect ratio (i.e. height is much greater than width) and I’m not sure what tweaks you could make to the SSD anchors/priors to help with that but I’m guessing some additional experimentation could tell.
thnx
thnx that you are “in topic”, i mostly do this project alone. it has been great help.
I guess that beginners and dumb users as i are lucky :) - I think, the case was that before I used SSD v1, I changed the settings and later trained with v2 and didn’t know that it uses the same conf (but i thought couple of times if it was configurable) - so, my “old v1” settings gives better resolution and v2 gives accuracy and better detecting:
specs = [
SSDSpec(32, 16, SSDBoxSizes(10, 35), [2, 3]),
SSDSpec(16, 32, SSDBoxSizes(35, 50), [2, 3]),
SSDSpec(8, 64, SSDBoxSizes(50, 65), [2, 3]),
SSDSpec(4, 100, SSDBoxSizes(195, 240), [2, 3]),
SSDSpec(2, 150, SSDBoxSizes(240, 285), [2, 3]),
SSDSpec(1, 300, SSDBoxSizes(285, 512), [2, 3])
]
priors = generate_ssd_priors(specs, image_size)
def set_image_size(size=512, min_ratio=20, max_ratio=90):
global image_size
global specs
global priors
Is the 512px the limit or can i go further?
What about ssd mobilenet v3?
i measure the model performance again and let you know if it is interesting to you. i’ll bring out how fast the model works. So, same settings, same dataset, one is v1 and other v2.
one thing diferent is batch size, i have 2x1070 8GB and batch size 60 is with v2 too much (out of memory).
ssd v1:
visioline@mv:~/install/pytorch-ssd$ python3 train_ssd_gpus.py --dataset-type=voc --data=data/jwx --model-dir=models/jwx-super-v1 --batch-size=60 --workers=22 --epochs=600 --resolution=512 --use-cuda=True --gpu-devices 0 1 --validation-mean-ap=True --checkpoint-folder=models/jwx-super-v1-checkpoint --validation-epochs=10
ssd v2:
visioline@mv:~/install/pytorch-ssd$ python3 train_ssd_gpus.py --dataset-type=voc --data=data/jwx --model-dir=models/jwx-super-v2 --batch-size=30 --workers=22 --epochs=600 --resolution=512 --use-cuda=True --gpu-devices 0 1 --net=mb2-ssd-lite --pretrained-ssd=models/mb2-ssd-lite-mp-0_686.pth --validation-mean-ap=True --checkpoint-folder=models/jwx-super-v2-checkpoint --validation-epochs=10
I’ve not tried >512px so I’m not sure if there are issues or not, but that set_image_size() algorithm supposedly should configure it for any size.
I haven’t backported SSD-Mobilenet-v3 to the repo (it was added to the upstream repo, but without the pretrained model) or tried it with ONNX.


Thanks @raul.orav, appreciate you sharing your results - I will keep this in mind when training new models!
Dusty, can you give me a hint how to use with python jetson’s nvenc0 or nvjpg? The problem is that converting CUDa to numpy and using CV2 uses too much CPU.
At the moment i stream video this way:
input_img1 = camera1.Capture() #lets capture image from camera 1
Define the function that captures video frames and converts them to JPEG format
def generate_frames(ximg):
while True:
vimg1 = cudaToNumpy(ximg) #lets convert it to numpy array
vimg1 = cv2.cvtColor(vimg1, cv2.COLOR_RGB2BGR) #lets convert it to BGR to avoid seeing blue image
# Convert the numpy array to JPEG format
ret, jpeg = cv2.imencode(‘.jpg’, vimg1)
if not ret:
break
# Yield the JPEG data as a byte string
yield (b’–frame\r\n’
b’Content-Type: image/jpeg\r\n\r\n’ + jpeg.tobytes() + b’\r\n’)
Define the route for streaming video
@app.route(‘/video1’)
def video_feed1():
# Return a Response object with the generator function that converts the frames to JPEG format
return Response(generate_frames(input_img1),
mimetype=‘multipart/x-mixed-replace; boundary=frame’)
When using Python, it would probably be through GStreamer. However, might I recommend streaming the video via RTP, RTSP, or WebRTC instead?
Dusty, before it was good to test on command line detectnet with --headless option. But when using dev branch, it says that there is no output. Maybe it isn’t bad idea to add a “true headless” option, where there is no output, only text output in terms of found classes, coordinates and confidence, etc (no image output).
For me the workaround is to test on command line (via SSH) detectnet with output option which saves video :) But still… Explanation is that i got covid and have only ssh access to jetson :) - i’m testing object tracking in dev branch.
I’m thinking that “–tracker-max-frames=X” would be also quite useful in some applications
OK thank you I will look into that, are you using detectnet (C++) or detectnet.py?
detectnet.py