Issue:
During validation of the Mask2Former, the accuracy and mIoU metrics are always 1.0. This is obviously incorrect and should be lower. The issue occurs when validating on coco panoptic as well as coco instance annotations.
I ran the instance segmentation tutorial notebook (mask2former_inst.ipynb). I changed the batch size and number of workers for training and trained on the validation set to just speed up the process. See the spec file here: spec_inst.txt (1.6 KB)
I then tested some other custom coco datasets available online. From this it seems like the problem only occurs when the number of classes is 1. I adjusted my custom apples dataset such that it had two classes and changed the annotations to have roughly half of both classes. I ran the same training, but now with only the number of classes adjusted: spec_inst_apples2.txt (1.6 KB)
This produced an accuracy and mIoU that is not 1.0:
Please follow the default notebook to train and run inference to confirm it is working. The training epoch is set to 50 by default. Your setting(only train for 1 epoch) is not enough.
I do not care so much about how high the accuracy and the mIoU of the model that is produced by the tutorial notebook. I want to train a model on a custom dataset, but it seems like that the evaluation script does not yield correct results when the num_classes is set to 1 in the config file, because the accuracy and mIoU is always 1.0. As per my previous post, the default notebook does yield correct accuracies and mIoU (although not high). By changing my custom dataset to two classes, the validation does work correctly, however this is not desired.
I am seeking to validate my custom trained model which only has to predict a single class, instead of validating the standard model produced by the default notebook. Can you help me with this?
Can you enlarge more training epochs to check if it works? I am afraid the training does not converge yet.
I will also check further if it supports only class 1.
It can support running with only 1 class.
Please ensure “the category ids and annotation ids must be greater than 0.” mask2former - NVIDIA Docs. Thanks.
If possible, please share the minimal dataset to us to reproduce as well.
I have made sure that the annotation and category ids are both 1 for my single class dataset, but the problem still persists.
Unfortunately, I cannot share my dataset. However, I am able to reproduce the result on the COCO dataset. I have converted the annotations of the COCO val2017 dataset to only contain one and two classes. Here are the zip files containing the json files for the annotations: val_single_class.zip (3.1 MB) val_double_class.zip (3.4 MB)
The experiment configuration files are set up to both train and validate for a single epoch on the COCO val2017 dataset using the available pretrained model. When training, the validation at the end of the epoch shows an accuracy and mIoU of 1.0 on the single class dataset and an accuracy of 0.991 and mIoU of 0.934 on the double class dataset.
Note that you have to download the pretrained model and the COCO val2017 images. These are available here. You also have to set the filepaths/folderpaths in the config files to match your workspace setup.
Please let me know if you are able to reproduce the result or if anything is unclear.
Training for only 1 epoch does not make sense to compare. Also, “an accuracy and mIoU of 1.0” has not much different against "an accuracy of 0.991 and mIoU of 0.934 ". They all imply that the training does not converge yet. The inference result should be similar(almost are wrong). So, I still suggest we to run full training to compare. I am running on my side as well. Will update to you if I have. Thanks.
Hello, I’m running into the same issue. I’m training Mask2former on my own COCO formatted dataset with 1 class anywhere from 5 to 200 epochs. I’ve tried a variety of different hyperparameters, and all of them result in mIoU of 1 for all epochs which is making me doubt the training progress.
I’m able to train Mask2former using mmdetection with great results; however, trying to replicate the process on TAO, the performance is falling short and has been disappointing. I’ve attached the relative files for your reference if necessary. labelmap_inst.txt (130 Bytes) spec_inst.txt (2.3 KB) train_annotations.txt (3.2 MB)
Unfortunately the shared thread didn’t help with my issue. What log are you looking for exactly, so I can share appropriately? For now I’ve attached the autogenerated experiment yaml file as well as the status file for training. experiment_yaml.txt (4.8 KB) status_yaml.txt (69.4 KB)
@Morganh Digging through the source code, it appears that this line of code has been commented out:
[:, 1:]drops the real class 0 and keeps only the “no-object” channel. With just one class, the model can now predict only “no-object”, so every pixel it outputs is indexed as 0. During mIoU computation class 0 is compared with the present ground-truth (also indexed 0 after reduce_zero_label=True), giving an intersection = union case or IoU = 1 for every image. At least this is my theory.
However, making the changes (:1 to :-1) inside the container and testing it from within the container made no difference:
Thanks for the info. But when I docker login the nvcr.io/nvidia/tao/tao-toolkit:5.5.0-pyt and check /usr/local/lib/python3.10/dist-packages/nvidia_tao_pytorch/cv/mask2former/model/pl_model.py.
$ docker run --runtime=nvidia -it --rm nvcr.io/nvidia/tao/tao-toolkit:5.5.0-pyt /bin/bash
root@11f18e6d31af:/opt/nvidia/tools# ls /usr/local/lib/python3.10/dist-packages/nvidia_tao_pytorch/cv/mask2former/model/pl_model.py
The line 637 is not commented out.
632 def instance_inference(self, mask_cls, mask_pred):
633 """Post process for instance segmentation."""
634 # mask_pred is already processed to have the same shape as original input
635 image_size = mask_pred.shape[-2:]
636 # [Q, K]
637 scores = F.softmax(mask_cls, dim=-1)[:, 1:]
Mine is also the same. I’ve been doing more debugging in the container, and it seems that the model is not learning my “foreground” or non-background pixels at all. When I print the unique predicted labels, I only get [0] and not [0, 1] which is what you expect if the model were to predict both foreground and background. I can confirm this by looking at the segmentation mask input to the model and the predict mask: Input:
This all makes me think the issue is dataset related or how the pipeline maps the labels to indexes and so forth.
I understand the dataloader expects the COCO format, and I’ve reviewed my dataset to be correct, but I’m not sure if I’ve missed something subtle that is resulting in this behavior. Are you able to verify the attached example validation annotation file for accuracy? Things like categories, the segmentation format, etc. val_annotations.txt (248.1 KB)
p.s. I still think setting reduce_zero_label to False is sensible here as my dataset has only 1 class.
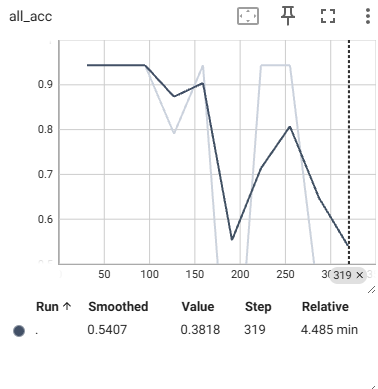
p.s. After changing reduce_zero_label to False I do get a value that is lower than 1; however, it ends up staying the same for all epochs and suddenly dropping for the last epoch. Printing the values during each epoch I get this:
iou [0.9436853 0. ]
miou 0.47184265
It seems to me that the model is not making any prediction for the second class (which is either the background or foreground in this case), so one value in iou is always 0 now.
I suppose some good news is that now I can see a mask on prediction; however, another strange finding is that looking at the input segmentation to the model and its prediction, the label values seem to be flipped. Notice how the purple and yellow are flipped in these images. Input
As a reminder, it seems like per mmdetection documentation, for binary segmentations a few changes are needed, but I’m not sure how I can make these changes in TAO. Reference How to handle binary segmentation task in the following repo:
This reduce_zero_label controls whether annotation labels are decremented by 1 at data load time. For binary segmentation datasets with only two classes (background = 0 and foreground = 1), this parameter should be set to False . Setting it to True causes all labels to shift down by one, making background labels invalid and giving the model no proper foreground class to learn. So, please set to False.
More, it is not expected t0 set num_classes: 1. For binary segmentation, it is a must to set: num_classes=2. Please retry with this setting.
Hello Morgan, I’ve already tried the combination with num_classes=2 and reduce_zero_label=False with no luck. Moreover, reduce_zero_label should be a passable parameter if it needs to be set accordingly for a binary task, or this should be done dynamically within the dataloader pipeline.