Hello,
I’m using:
- Nvidia Jetson AGX Orin Dev Kit
- Jetpack 6 DP
- Deepstream pipeline
- Inference with Triton Server 2.43 (docker image)
I’m using a segmentation model developed in my project and I’m getting about 50-55FPS. I’d like to understand how I can enhance the performance because I noticed that GPU (through jtop) is used around 20%.
I used Nsight systems to investigate my CPU/GPU usage. I noticed a low GPU average usage (about 20-25%) but I have some trouble to identify what is causing the GPU to be under-utilized → i’d like to identify why the GPU is resting :

The nsight report is around 2Gb.
That’s the first time I’m using nsight so any tips will be welcome. I did watch some webinar on it so I understand how the tool work but I’m unable to draw conclusions.
It would be really great to have a little help from you to continue my work.
Hi,
Which backend do you use? TensorRT, PyTorch, or TensorFlow?
Would you mind attaching the nsys output so we can check the details to get more info?
Thanks.
Hello,
I’m using TensorRT.
Here is the link
Hi,
We tried to download the file but failed several times.
Could you help us re-check it?
Thanks.
Hi,
Thanks a lot for re-uploading the file.
Confirmed that we can download and open the file.
Will share more info with you later.
Hi,
Could you share more about the model and use case?
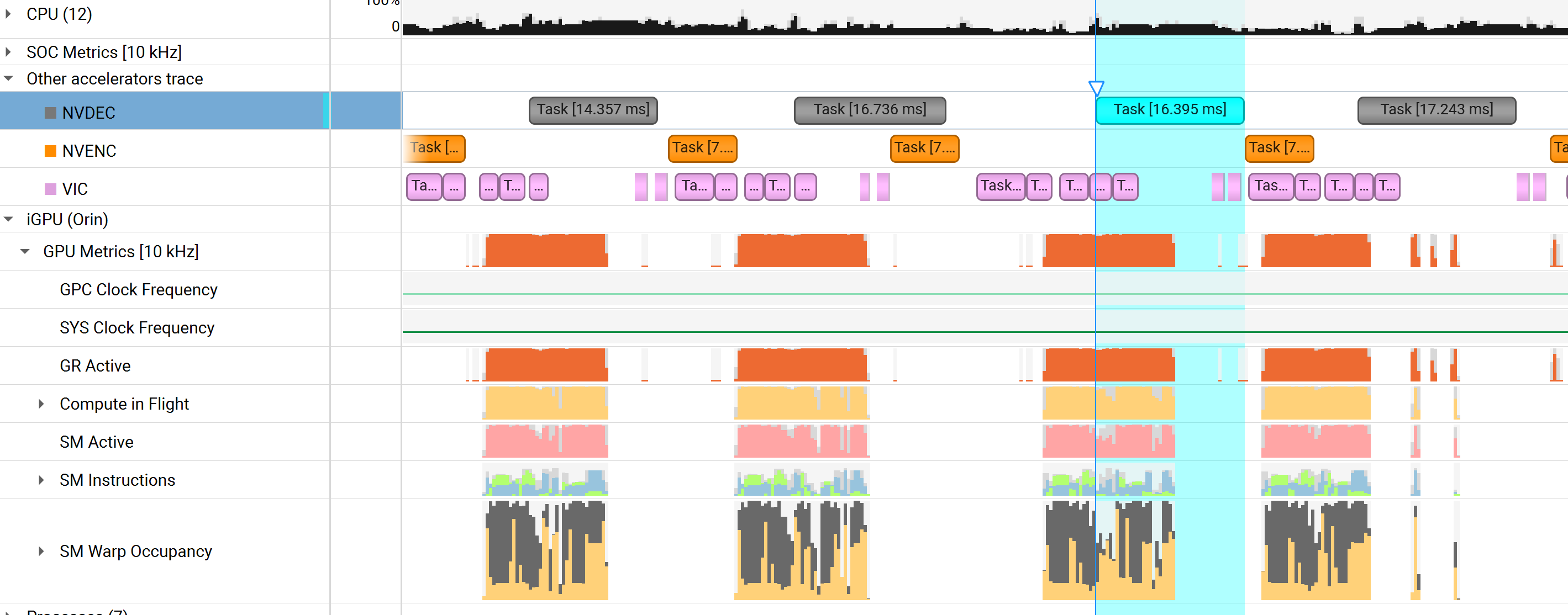
Based on your nsys file, the NVDEC takes 16.3~16.7ms seems to be the bottleneck of the pipeline.
Thanks.
Hi AastaLLL,
- Could you share more about the model and use case?
The model is a custom segmentation model. The use case is human/object detection.
- Based on your nsys file, the NVDEC takes 16.3~16.7ms seems to be the bottleneck of the pipeline.
Thanks for the analysis.
I’m using a video file for that is encoded in 1080p 30fps (h264).
How can I make it run faster and use less time in decoding ?
Hi,
Based on our spec here, h264 decoding can reach higher throughput.
Which nvpmodel do you use? Could you maximize the device’s performance and try it again?
$ sudo nvpmodel -m 0
$ sudo jetson_clocks
Could you also turn off the Triton inference and test the decoding fps separately?
We also have some recommendations for performance optimization.
Please also give it a try.
https://docs.nvidia.com/metropolis/deepstream/6.3/dev-guide/text/DS_ref_app_deepstream.html#performance-optimization
Thanks.
Hello,
- Which nvpmodel do you use? Could you maximize the device’s performance and try it again?
$ sudo nvpmodel -m 0
$ sudo jetson_clocks
Yes, I’ve already done that.
- Could you also turn off the Triton inference and test the decoding fps separately?
What do you mean ? Using gstreamer only ? Or doing the inference ?
I’m not sure how it is changing anything since the inference is done after the decoding of video.
Anyway, if I use the config file you referenced, I got this error:
Creating nvstreammux
Creating nvinfer
Could not find group property
** ERROR: <gst_nvinfer_parse_config_file:1382>: failed.
Hi,
Could you share your config/sample/model with us so we can check it further?
Please also share the reproducible steps as well.
Thanks.
Sorry for the delay.
I find the issue and I was able to perform the test.
As a reference, here is the config file I used:
config_file.txt (2.0 KB)
And here is link to the report
I checked and it is much faster.
To be able to share the code that I used for my request, how can I transfer it privately ? The project is under NDA.
Hello,
Do you have news for me ?
Hello,
Can I please get an update ?
Hi,
Sorry for the late update.
In the config file you shared, the primary-gie is disabled.
Do you get a much faster result based on it?
Are you able to share the code with a privacy message or need some extra agreement?
Thanks.
Yes, it was really fast. The report is in the post from May 2.
Are you able to share the code with a privacy message or need some extra agreement?
Privacy message should be fine. How do we get in touch through there ?
Hi,
Are you able to measure the time without inference?
Since we originally thought the bottleneck comes from NVDEC, this should not change (~16ms) even if disabling the primary-gie.
The primary message is also a topic that can add comments so it should be fine (discussion).
Thanks.
I’ll try it.
I sent you a PM with the files so you can try to reproduce.