Continuing the discussion from How to do inference with fpenet_fp32.trt:
Please provide the following information when requesting support.
• Hardware: GTX 1070Ti
• Network Type: FpeNet
• TLT Version: tao-converter(tao-converter-x86-tensorrt8.0)
• How to reproduce the issue ?
I convert FpeNet to TensorRT by following steps:
- Download model: https://catalog.ngc.nvidia.com/orgs/nvidia/models/tlt_fpenet/files?version=deployable_v1.0
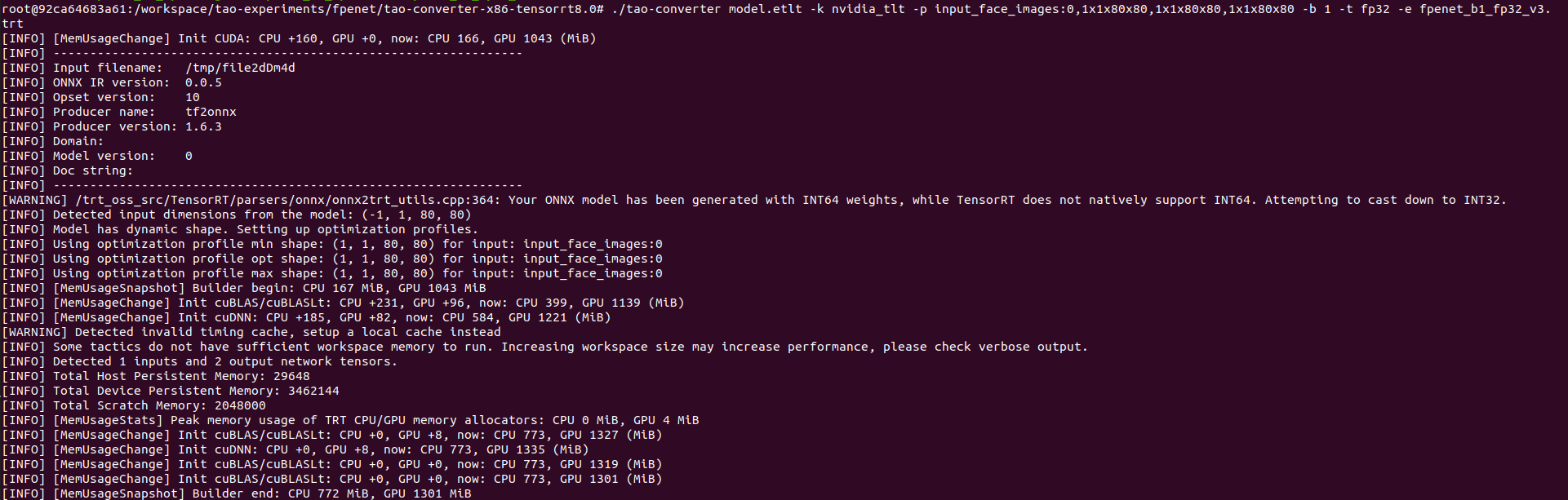
- Convert to TensorRT by the command: ./tao-converter model.etlt -k nvidia_tlt -p input_face_images:0,1x1x80x80,1x1x80x80,1x1x80x80 -b 1 -t fp32 -e fpenet_b1_fp32_v2.trt
Output Logs:
[INFO] [MemUsageChange] Init CUDA: CPU +160, GPU +0, now: CPU 166, GPU 982 (MiB)
[INFO] ----------------------------------------------------------------
[INFO] Input filename: /tmp/fileHbd8d0
[INFO] ONNX IR version: 0.0.5
[INFO] Opset version: 10
[INFO] Producer name: tf2onnx
[INFO] Producer version: 1.6.3
[INFO] Domain:
[INFO] Model version: 0
[INFO] Doc string:
[INFO] ----------------------------------------------------------------
[WARNING] /trt_oss_src/TensorRT/parsers/onnx/onnx2trt_utils.cpp:364: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
[INFO] Detected input dimensions from the model: (-1, 1, 80, 80)
[INFO] Model has dynamic shape. Setting up optimization profiles.
[INFO] Using optimization profile min shape: (1, 1, 80, 80) for input: input_face_images:0
[INFO] Using optimization profile opt shape: (1, 1, 80, 80) for input: input_face_images:0
[INFO] Using optimization profile max shape: (1, 1, 80, 80) for input: input_face_images:0
[INFO] [MemUsageSnapshot] Builder begin: CPU 168 MiB, GPU 982 MiB
[INFO] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +231, GPU +96, now: CPU 399, GPU 1078 (MiB)
[INFO] [MemUsageChange] Init cuDNN: CPU +185, GPU +82, now: CPU 584, GPU 1160 (MiB)
[WARNING] Detected invalid timing cache, setup a local cache instead
[INFO] Some tactics do not have sufficient workspace memory to run. Increasing workspace size may increase performance, please check verbose output.
[INFO] Detected 1 inputs and 2 output network tensors.
[INFO] Total Host Persistent Memory: 29792
[INFO] Total Device Persistent Memory: 2642432
[INFO] Total Scratch Memory: 2048000
[INFO] [MemUsageStats] Peak memory usage of TRT CPU/GPU memory allocators: CPU 0 MiB, GPU 4 MiB
[INFO] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +1, GPU +8, now: CPU 773, GPU 1235 (MiB)
[INFO] [MemUsageChange] Init cuDNN: CPU +0, GPU +8, now: CPU 773, GPU 1243 (MiB)
[INFO] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +0, now: CPU 773, GPU 1227 (MiB)
[INFO] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +0, now: CPU 772, GPU 1209 (MiB)
[INFO] [MemUsageSnapshot] Builder end: CPU 772 MiB, GPU 1209 MiB
- Run test.py: python test.py --input test.png

I got this error
inferece time: 0.001052992000040831
image has been writen to landmarks.jpg
[TensorRT] ERROR: 1: [hardwareContext.cpp::terminateCommonContext::141] Error Code 1: Cuda Runtime (invalid device context)
[TensorRT] INTERNAL ERROR: [defaultAllocator.cpp::free::85] Error Code 1: Cuda Runtime (invalid argument)
Segmentation fault (core dumped)
I run everything in docker: nvcr.io/nvidia/tao/tao-toolkit-tf:v3.21.11-tf1.15.4-py3
Thanks,