Hi, everyone , first of all, this error occurs when i tried to convert onnx model trained by pytorch to *.engine file.
My enviroment is as follows
RTX3090 / ubuntu18.04
i 've intalled cuda11.2 and tensorrt8.2 GA version on my computer.
the details are
ubuntu 18.04
TensorRT 8.2GA
onnx-tensorrt for tensorrt8,please refer to other repos, onnx-tensorrt repo
cuda 11.2
Name: torch
Version: 1.7.0+cu110
Summary: Tensors and Dynamic neural networks in Python with strong GPU acceleration
Home-page: https://pytorch.org/
Author: PyTorch Team
Author-email: packages@pytorch.org
License: BSD-3
Location: /home/{Path}/anaconda3/envs/CenterTrack/lib/python3.6/site-packages
Requires: numpy, typing-extensions, future, dataclasses
Required-by: torchvision, torchaudio
GTX3090
– The C compiler identification is GNU 7.5.0
– The CXX compiler identification is GNU 7.5.0
– Detecting C compiler ABI info
– Detecting C compiler ABI info - done
– Check for working C compiler: /usr/bin/cc - skipped
– Detecting C compile features
– Detecting C compile features - done
– Detecting CXX compiler ABI info
– Detecting CXX compiler ABI info - done
– Check for working CXX compiler: /usr/bin/c++ - skipped
– Detecting CXX compile features
– Detecting CXX compile features - done
– Found Protobuf: /usr/local/lib/libprotobuf.so;-lpthread (found version “3.15.8”)
–
– ******** Summary ********
– CMake version : 3.22.2
– CMake command : /snap/cmake/1005/bin/cmake
– System : Linux
– C++ compiler : /usr/bin/c++
– C++ compiler version : 7.5.0
– CXX flags : -Wall -Wno-deprecated-declarations -Wno-unused-function -Wnon-virtual-dtor
– Build type : Release
– Compile definitions : SOURCE_LENGTH=42;ONNX_NAMESPACE=onnx2trt_onnx
– CMAKE_PREFIX_PATH :
– CMAKE_INSTALL_PREFIX : /usr/local
– CMAKE_MODULE_PATH :
– ONNX version : 1.8.0
– ONNX NAMESPACE : onnx2trt_onnx
– ONNX_BUILD_TESTS : OFF
– ONNX_BUILD_BENCHMARKS : OFF
– ONNX_USE_LITE_PROTO : OFF
– ONNXIFI_DUMMY_BACKEND : OFF
– ONNXIFI_ENABLE_EXT : OFF
– Protobuf compiler : /usr/local/bin/protoc
– Protobuf includes : /usr/local/include
– Protobuf libraries : /usr/local/lib/libprotobuf.so;-lpthread
– BUILD_ONNX_PYTHON : OFF
– Found CUDA headers at /usr/local/cuda/include
– Found TensorRT headers at /usr/include/x86_64-linux-gnu
– Find TensorRT libs at /usr/lib/x86_64-linux-gnu/libnvinfer.so;/usr/lib/x86_64-linux-gnu/libnvinfer_plugin.so
– Found TENSORRT: /usr/include/x86_64-linux-gnu
– Found Threads: TRUE
– Found CUDA: /usr/local/cuda-11.2 (found version “11.2”)
– Found TensorRT headers at /usr/include/x86_64-linux-gnu
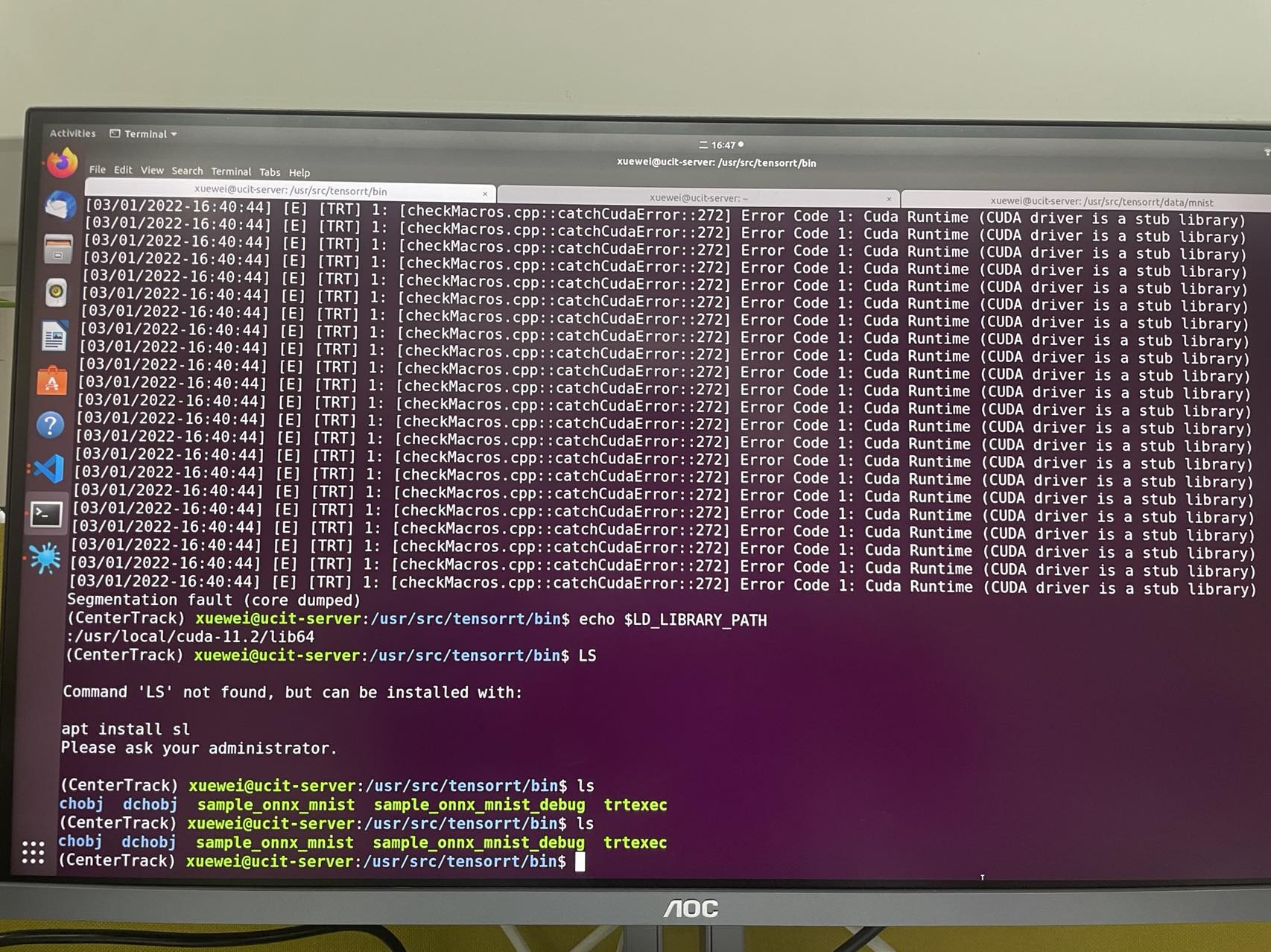
finally, i built my program successfully on the basis of above enviroment, however, when i executed the program to do onnx transferring to engine file, i got the error of
[checkMacros.cpp::catchCudaError::272] Error Code 1: Cuda Runtime (CUDA driver is a stub library)
i 've tried to search this error on google, however, i have not found some helpful information yet, it referred stub library, which really made me confused, so any help or suggestions will be so much appreciated! thanks in advance!!