Hi all,
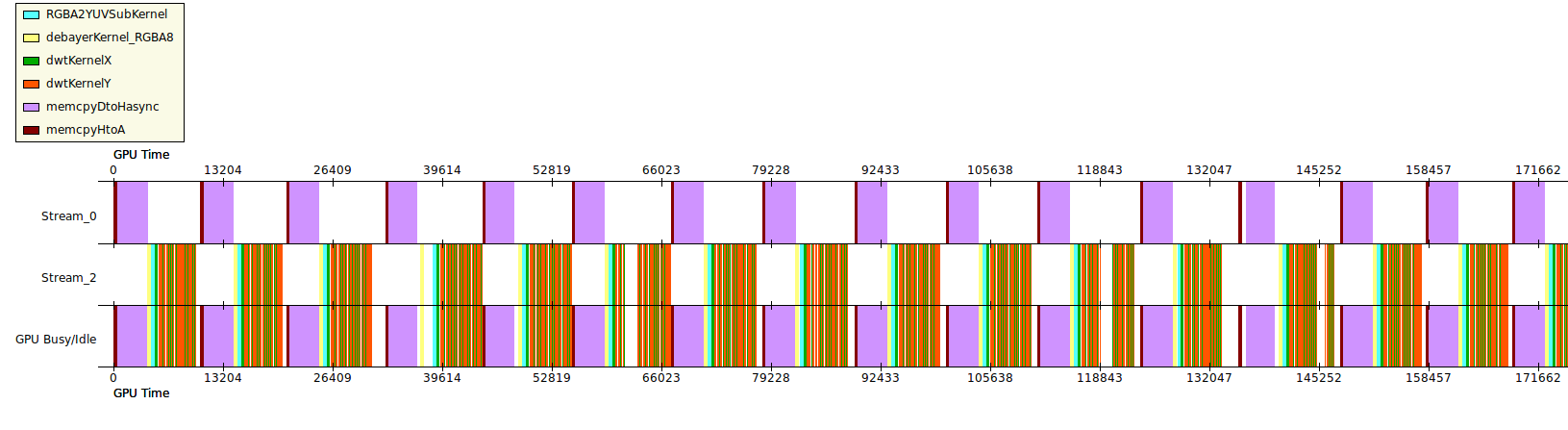
I’ve got some cuda code that I wanted to speed up by overlapping asynchronous device2host copies with kernel execution using page-locked memory. When inspecting the GPU-time width plot, I do not see the overlap (see attached figure).
When I put the copy on the same stream as the kernels, execution times are 4.2 ms per iteration. When I put it in a different stream, execution time drops to 2.95 ms per iteration, so it works.
In both cases, however, the GPU time width plot looks exactly the same. Even when I put the copy in the same stream as the kernels, it appears in Stream_0 in the plot.
Is this a bug? Or am I interpreting the profiler incorrectly?
N.