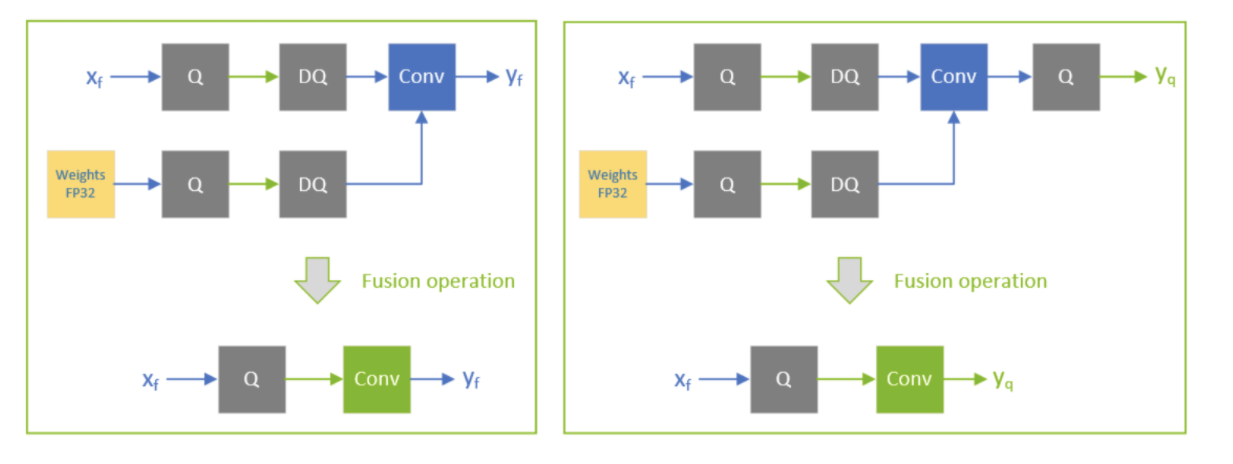
I am very confused about the design concept of the Q/DQ node during QAT. Take the picture below as example, now that TensorRT has the implementation of int8 conv op,
why we cannot quantize weights and activations to int8 then use int8 conv op directly during explicit quantization?
and why we must use DQ to restore precision? If we act like this, take number 3 as example, is it like that we don’t use integer 3 but use float 3.0 instead? What’s the meaning of DQ node?
And one more question,why the int8 implementation is faster than fp16, is it because that the int8 has faster engine?
I would very appreciate if someone can give me some explanations!
and the link you give is different? The thing bothers me a lot is that why we need to use DQ in the pytorch_quantization package to restore precision to float? Thanks
Quantization refers to techniques for performing computations and storing tensors at lower bit widths than floating-point precision. A quantized model executes some or all of the operations on tensors with integers rather than floating-point values. So we need inputs as floating points.
QAT is a quantization method used in conjunction with training. I.e. it is used in torch and TF. These frameworks use a fake-quantization function. When you want to export these models to ONNX for TRT consumption the fake-quantization is converted to a pair of Q-DQ operators. Pytorch’s quantization also supports the fusion of some nodes with fake-quantization, but ONNX does not support these fused nodes so these models can’t be exported to ONNX.