We have trained the object detection model using tensorflow/Keras framework using the FP32 precision and then performed PTQ on a calibration dataset.
We got the TRT engine with good inference speed but the precision is affected significantly, so we decided to perform QAT training.
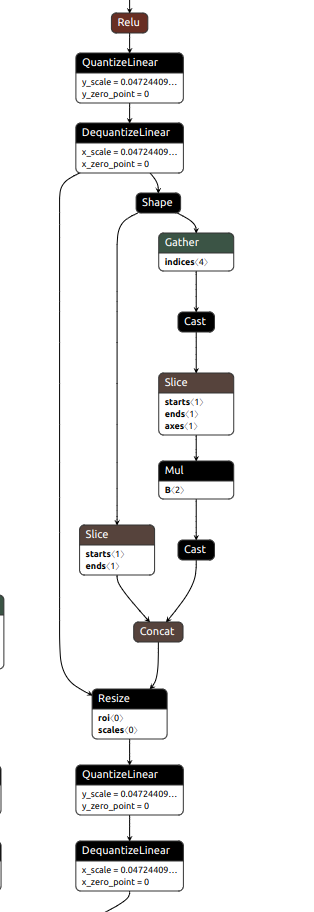
After a lot of refactoring we have got the final int8 model with precision comparable to FP32 model (sometimes even better), but the speed of the TRT produced engine is considerable slower than for engine generated using PTQ. Using the TRT profiling we have found that a lot of operations are still being executed in FP32, so we have investigated all of that cases and whenever it is possible added Q/DQ nodes or changed the graph to avoid transitions to FP32.
We have found that all differences in speed between the QAT and PTQ engines are because of UpSampling2D layers (translated to ONNX Resize operation), which are up scaling the input tensor using the “nearest mode”. In case of PTQ engine these layers are executed in int8 precision, but for QAT engine input tensors are always dequantized to FP32 and then quantized back to INT8. From the profiling log we see that the total cost of extra DQ/Q nodes kept in the graph are approximately corresponds to the performance loss we see comparing to the PTQ engine.
The sub-graph for QAT model looks like:
The PTQ case:
, { "name" : "ttfnet/conv2d_6/Conv2D + ttfnet/conv2D_up3/Relu", "timeMs" : 20.2009, "averageMs" : 0.169756, "medianMs" : 0.169472, "percentage" : 0.652824 }
, { "name" : "Resize__1176", "timeMs" : 35.3989, "averageMs" : 0.297469, "medianMs" : 0.29744, "percentage" : 1.14397 }
, { "name" : "PWN(ttfnet/add_2/add)", "timeMs" : 95.5724, "averageMs" : 0.803129, "medianMs" : 0.80304, "percentage" : 3.08857 }
Resize operation IO formats for PTQ:
"LayerType": "Resize",
"Inputs": [
{
"Name": "ttfnet/conv2D_up5/Relu:0",
"Location": "Device",
"Dimensions": [1,128,30,90],
"Format/Datatype": "Thirty-two wide channel vectorized row major Int8 format"
}],
"Outputs": [
{
"Name": "Resize__1044:0",
"Location": "Device",
"Dimensions": [1,128,60,180],
"Format/Datatype": "Thirty-two wide channel vectorized row major Int8 format"
}],
The QAT case:
, { "name" : "ttfnet/quant_conv2d_6/LastValueQuant/QuantizeAndDequantizeV4/Identity:0 + QuantLinearNode__254 + ttfnet/quant_conv2d_6/Conv2D", "timeMs" : 16.9824, "averageMs" : 0.166494, "medianMs" : 0.166512, "percentage" : 0.542475 }
, { "name" : "DequantLinearNode__615", "timeMs" : 39.9534, "averageMs" : 0.3917, "medianMs" : 0.391776, "percentage" : 1.27625 }
, { "name" : "Resize__1828", "timeMs" : 157.379, "averageMs" : 1.54293, "medianMs" : 1.54294, "percentage" : 5.02722 }
, { "name" : "QuantLinearNode__618", "timeMs" : 109.131, "averageMs" : 1.06991, "medianMs" : 1.07011, "percentage" : 3.48602 }
, { "name" : "PWN(ttfnet/quant_add_2/add)", "timeMs" : 76.8304, "averageMs" : 0.753239, "medianMs" : 0.753024, "percentage" : 2.45422 }
Resize operation IO formats for QAT:
"Inputs": [
{
"Name": "ttfnet/quant_up_sampling2d/LastValueQuant/QuantizeAndDequantizeV4:0",
"Location": "Device",
"Dimensions": [1,128,30,90],
"Format/Datatype": "Row major linear FP32"
}],
"Outputs": [
{
"Name": "Resize__1696:0",
"Location": "Device",
"Dimensions": [1,128,60,180],
"Format/Datatype": "Row major linear FP32"
}],
We have tried graph with and without QDQ nodes prior to the Resize operation, but it doesn’t help, Resize always executed as FP operation.
We have also tried to replace the sub-graph with Resize operation by the custom TRT plugin which can perform the up-sampling operation in INT8, HALF and FLOAT formats (sub-graph looks like shown below).

During the engine creation, the plugin is being asked for support of different format combinations including formats matching the output format of the previous layer, but in the final profile we see that the transition to FLOAT is still used. In case if plugin reports that the FLOAT datatype is not supported the TensorRT refuses to create engine at all.
Obviously there is something wrong with the onnx model/graph as in PTQ mode it seems like all operations can be executed using int8 precision. So, what is wrong with our model?
Of course the performance penalties can be reduced by specifying --fp16 in addition to --int8, in this case operations mentioned above will be performed in fp16.
