Hello, I am fairly new to machine learning and nvidia tao. I am attempting to train the emotionnet model on a new data set. I’ve successfully created json files for this dataset and am now attempting to convert them to tfrecords. However, although the tfrecord files are being created, they are empty. I have looked at other places on the internet for help, but no one else seems to have this specific problem, and I don’t think it’s an issue with the ~/.tao_mounts.json.
Please provide the following information when requesting support.
• Hardware (T4/V100/Xavier/Nano/etc) - Quadro RTX 6000
• Network Type (Detectnet_v2/Faster_rcnn/Yolo_v4/LPRnet/Mask_rcnn/Classification/etc) - emotionnet
• TLT Version (Please run “tlt info --verbose” and share “docker_tag” here) - nvidia/tao/tao-toolkit-tf: v3.22.05-tf1.15.5-py3:
• Training spec file(If have, please share here) - emotionnet_tlt_pretrain.yaml
• How to reproduce the issue ? (This is for errors. Please share the command line and the detailed log here.)
tao emotionnet dataset_convert -c /workspace/tao-experiments/emotionnet/dataset_specs/dataio_config_ckplus.json
Log:
2022-06-29 11:53:38,553 [INFO] root: Registry: [‘nvcr.io’]
2022-06-29 11:53:38,694 [INFO] tlt.components.instance_handler.local_instance: Running command in container: nvcr.io/nvidia/tao/tao-toolkit-tf:v3.22.05-tf1.15.5-py3
2022-06-29 16:53:39.851597: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
WARNING:tensorflow:Deprecation warnings have been disabled. Set TF_ENABLE_DEPRECATION_WARNINGS=1 to re-enable them.
/usr/local/lib/python3.6/dist-packages/requests/init.py:91: RequestsDependencyWarning: urllib3 (1.26.5) or chardet (3.0.4) doesn’t match a supported version!
RequestsDependencyWarning)
Matplotlib created a temporary config/cache directory at /tmp/matplotlib-6bf8vw2r because the default path (/.config/matplotlib) is not a writable directory; it is highly recommended to set the MPLCONFIGDIR environment variable to a writable directory, in particular to speed up the import of Matplotlib and to better support multiprocessing.
Using TensorFlow backend.
WARNING:tensorflow:From /root/.cache/bazel/_bazel_root/ed34e6d125608f91724fda23656f1726/execroot/ai_infra/bazel-out/k8-fastbuild/bin/magnet/packages/iva/build_wheel.runfiles/ai_infra/iva/detectnet_v2/tfhooks/checkpoint_saver_hook.py:25: The name tf.train.CheckpointSaverHook is deprecated. Please use tf.estimator.CheckpointSaverHook instead.
2022-06-29 16:53:42,092 [WARNING] tensorflow: From /root/.cache/bazel/_bazel_root/ed34e6d125608f91724fda23656f1726/execroot/ai_infra/bazel-out/k8-fastbuild/bin/magnet/packages/iva/build_wheel.runfiles/ai_infra/iva/detectnet_v2/tfhooks/checkpoint_saver_hook.py:25: The name tf.train.CheckpointSaverHook is deprecated. Please use tf.estimator.CheckpointSaverHook instead.
WARNING:tensorflow:Deprecation warnings have been disabled. Set TF_ENABLE_DEPRECATION_WARNINGS=1 to re-enable them.
/usr/local/lib/python3.6/dist-packages/requests/init.py:91: RequestsDependencyWarning: urllib3 (1.26.5) or chardet (3.0.4) doesn’t match a supported version!
RequestsDependencyWarning)
Using TensorFlow backend.
WARNING:tensorflow:From /root/.cache/bazel/_bazel_root/ed34e6d125608f91724fda23656f1726/execroot/ai_infra/bazel-out/k8-fastbuild/bin/magnet/packages/iva/build_wheel.runfiles/ai_infra/iva/detectnet_v2/tfhooks/checkpoint_saver_hook.py:25: The name tf.train.CheckpointSaverHook is deprecated. Please use tf.estimator.CheckpointSaverHook instead.
2022-06-29 16:53:44,372 [WARNING] tensorflow: From /root/.cache/bazel/_bazel_root/ed34e6d125608f91724fda23656f1726/execroot/ai_infra/bazel-out/k8-fastbuild/bin/magnet/packages/iva/build_wheel.runfiles/ai_infra/iva/detectnet_v2/tfhooks/checkpoint_saver_hook.py:25: The name tf.train.CheckpointSaverHook is deprecated. Please use tf.estimator.CheckpointSaverHook instead.
WARNING:tensorflow:From /root/.cache/bazel/_bazel_root/ed34e6d125608f91724fda23656f1726/execroot/ai_infra/bazel-out/k8-fastbuild/bin/magnet/packages/driveix/build_wheel.runfiles/ai_infra/driveix/emotionnet/dataio/data_converter.py:98: The name tf.FixedLenFeature is deprecated. Please use tf.io.FixedLenFeature instead.
2022-06-29 16:53:44,384 [WARNING] tensorflow: From /root/.cache/bazel/_bazel_root/ed34e6d125608f91724fda23656f1726/execroot/ai_infra/bazel-out/k8-fastbuild/bin/magnet/packages/driveix/build_wheel.runfiles/ai_infra/driveix/emotionnet/dataio/data_converter.py:98: The name tf.FixedLenFeature is deprecated. Please use tf.io.FixedLenFeature instead.
WARNING:tensorflow:From /root/.cache/bazel/_bazel_root/ed34e6d125608f91724fda23656f1726/execroot/ai_infra/bazel-out/k8-fastbuild/bin/magnet/packages/driveix/build_wheel.runfiles/ai_infra/driveix/emotionnet/dataio/data_converter.py:101: The name tf.VarLenFeature is deprecated. Please use tf.io.VarLenFeature instead.
2022-06-29 16:53:44,384 [WARNING] tensorflow: From /root/.cache/bazel/_bazel_root/ed34e6d125608f91724fda23656f1726/execroot/ai_infra/bazel-out/k8-fastbuild/bin/magnet/packages/driveix/build_wheel.runfiles/ai_infra/driveix/emotionnet/dataio/data_converter.py:101: The name tf.VarLenFeature is deprecated. Please use tf.io.VarLenFeature instead.
2022-06-29 16:53:44,385 [INFO] main: Generate Tfrecords for data with required json labels
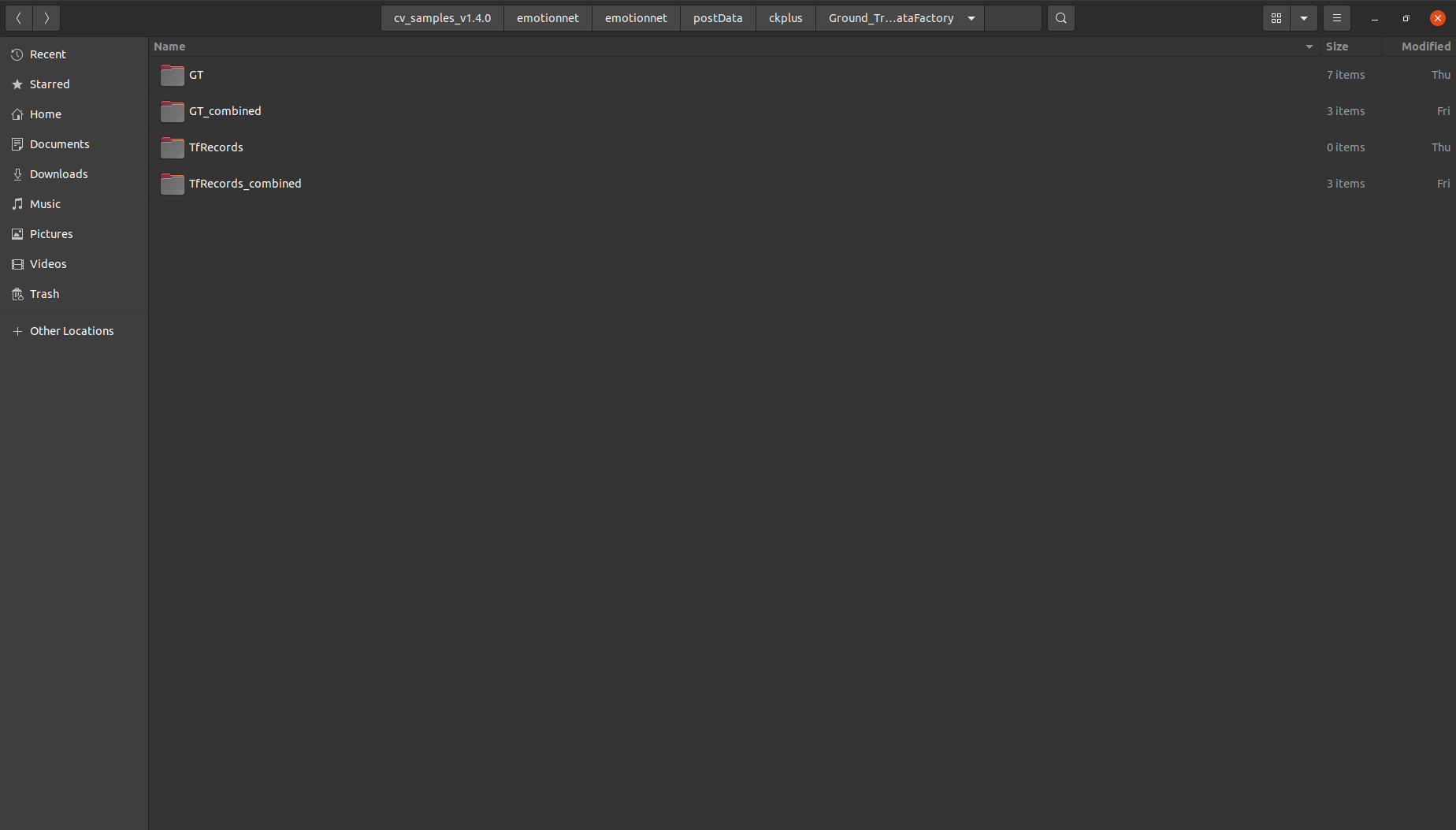
/workspace/tao-experiments/emotionnet/postData/ckplus2/Ground_Truth_DataFactory/TfRecords
/workspace/tao-experiments/emotionnet/postData/ckplus2/Ground_Truth_DataFactory/GT
2022-06-29 16:53:44,385 [INFO] main: Start to parse data…
2022-06-29 16:53:44,385 [INFO] main: Run full conversion…
/workspace/tao-experiments/emotionnet/postData/ckplus2/GT_user_json
2022-06-29 16:53:44,385 [INFO] main: Convert json file…
2022-06-29 16:53:45,692 [INFO] main: Start to write user tfrecord…
2022-06-29 16:53:45,692 [INFO] main: Start to split data…
/workspace/tao-experiments/emotionnet/postData/ckplus2/Ground_Truth_DataFactory/TfRecords_combined
2022-06-29 16:53:45,692 [INFO] main: Test:
2022-06-29 16:53:45,692 [INFO] main: Validation
2022-06-29 16:53:45,692 [INFO] main: Train
WARNING:tensorflow:From /root/.cache/bazel/_bazel_root/ed34e6d125608f91724fda23656f1726/execroot/ai_infra/bazel-out/k8-fastbuild/bin/magnet/packages/driveix/build_wheel.runfiles/ai_infra/driveix/emotionnet/dataio/data_converter.py:273: The name tf.python_io.TFRecordWriter is deprecated. Please use tf.io.TFRecordWriter instead.
2022-06-29 16:53:45,692 [WARNING] tensorflow: From /root/.cache/bazel/_bazel_root/ed34e6d125608f91724fda23656f1726/execroot/ai_infra/bazel-out/k8-fastbuild/bin/magnet/packages/driveix/build_wheel.runfiles/ai_infra/driveix/emotionnet/dataio/data_converter.py:273: The name tf.python_io.TFRecordWriter is deprecated. Please use tf.io.TFRecordWriter instead.
/workspace/tao-experiments/emotionnet/postData/ckplus2/Ground_Truth_DataFactory/GT_combined
2022-06-29 11:53:46,488 [INFO] tlt.components.docker_handler.docker_handler: Stopping container.