Originally published at: https://developer.nvidia.com/blog/detectnet-deep-neural-network-object-detection-digits/
The NVIDIA Deep Learning GPU Training System (DIGITS) puts the power of deep learning in the hands of data scientists and researchers. Using DIGITS you can perform common deep learning tasks such as managing data, defining networks, training several models in parallel, monitoring training performance in real time, and choosing the best model from the…
Could you please explain how do you obtain a receptive field of 555 x 555 pixels and the stride of 16 pixels in the sentence "Using GoogLeNet with it’s final pooling layer removed results in the sliding window application of a CNN with a receptive field of 555 x 555 pixels and a stride of 16 pixels." Thank you
There is a good explanation of how to calculate the receptive field of the output convolution layer of a network here: http://stackoverflow.com/qu...
Do you plan to release a version for custom-sized images, instead of 1248x384 (and for custom sized objects) ?
Hi Alp, You can modify your image size in network. I usually do this in the network customization window. The image size is inserted into the network both at the beginning and the end.
Hi Allison, I managed to create a trainingset with 1248x384 images, but this time, I cannot test with images larger than this resolution, it fails to detect. Is it not possible test with larger images, in this system? I was hoping to detect objects in, like 5000x5000 images, but seems not possible?
Are you getting an error or just no bounding boxes? Are you trying to perform detection with with a network that was trained with 1234x384 and then do detection on 5000x5000 pixel images? If so, you need to change the image dimensions in your network in the customization window. This needs to be done in the labels, transformation, cluster, and mAP layers. I hope this helps.
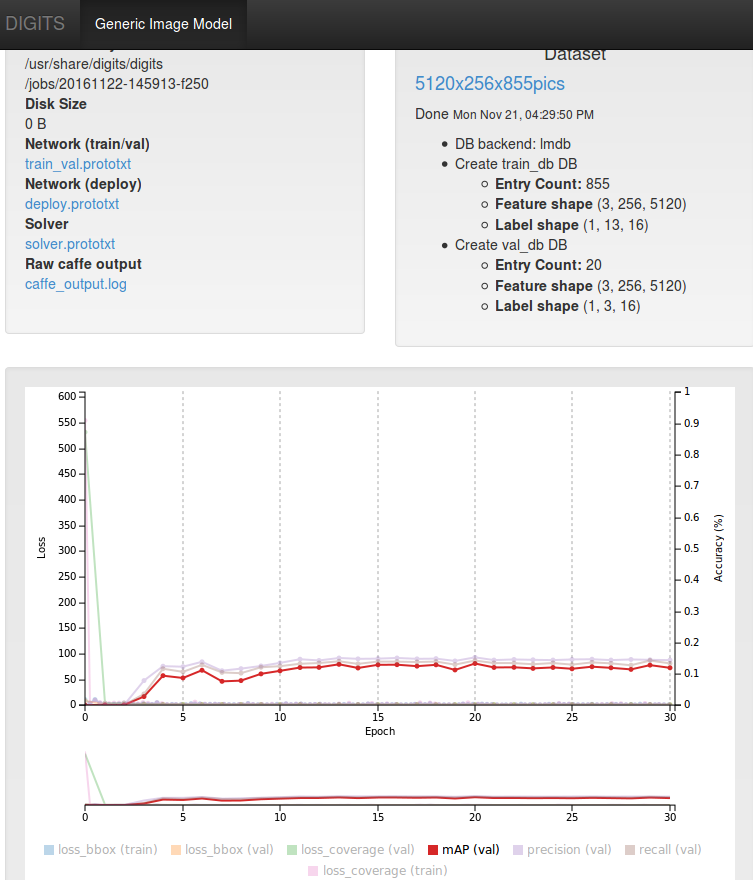
Thank you for taking time, I have tried your advice with 5120x256 dimensions. If I dont get you wrong, train_transform, val_transform, cluster, cluster_gt and mAP sections were modified with 5120x256 dimensions but training with new values immediately stopped with out of memory error (dataset is 1248x384 custom images, normally converges well with default values).
In this point, can we say, under limitation of 12gb GPU memory, it is simply not possible to test large size images ?
I actually need to know, before spending several days, am I trying the impossible, again, within my hardware limitations (Single Titan X maxwell).
-----problem solved----------
Problem solved now, thank you for the guidance. I set batch size & acc. to 3 & 4 ; along with above modifications to the network, this way, avoided ""out of memory" error and succesfully trained 855 of 5120x256 res. images.
https://uploads.disquscdn.c... https://uploads.disquscdn.c...
{kind=link}
{kind=link}
When creating your own labels for detectnet, what is the easiest way to specify the bounding boxes for your objects in the images ?
Successfully trained an object detection model using Detectnet. My system configuration is Core i5 processor, 16 GB RAM, and GTX 1080 GPU. Input image size is 1360 X 800. While testing it took almost 15 sec to detect object and plot the boxes on a single image.
It is specified in the passage that testing an input image size 1536×1024 will take only 41ms on Titan X GPU.
Network model I used is the detectnet_network.prototxt which is available along with caffe-0.15.14.
What is the reason for high execution time
Is your timing based on using the DIGITS interface with the option selected to visualize the individual layer activations? If so, most of that time is spent in generating all the additional information for the layer visualizations and activation histograms. The 41ms timing quoted in the post is solely the feed-forward inference time (obtained using the "caffe time" command line utility), so it doesn't include those overheads.
There are a number of open-source labelling tools available for this purpose, e.g. https://github.com/cvhciKIT...
The statement is correct - an FCN only contains convolutional layers and has no fully-connected layers.
Yes, the option for visualize individual layer activation was selected.
Removed the selection and run the test. The execution time reduced to 3 sec.
Can I get an execution time near to 41ms using my system configuration (Core i5 processor, 16 GB RAM, and GTX 1080 GPU) and Input image size is 1360 X 800?
Yes, you should be able to use the "caffe time" function along with the deploy.prototxt for DetectNet to see similar inference times. You will need to use batch size 1.
Kitti dontcare labeling is not quite like the DetectNet one. Kitti's README says: "'DontCare labels denote regions in which objects have not been labeled" and "You can use the don't care labels in the training set to avoid that your object
detector is harvesting hard negatives from those areas, in case you consider
non-object regions from the training images as negative examples."
The way I look at it, the dontcare label is supposed to denote a region where no labeling work has been done (there could be positive and negative examples there). The way you use it in DetectNet, is for negative regions, meaning places where there is no object of interest.
Am I right?
I guess there is no way I could use DetectNet with Kitti's semantic, given that any other labels are mapped to dontcare, so they are treated as negative examples. Any ideas?
I wrote a small macro tool for faster labeling of custom detectnet datasets. It allows you to draw bounding boxes around objects, provide a label name and save its coordinates. Rest of the parameters (truncated, occluded etc.,) recorded as zero.
Nowhere near a bulletproof coding, but it serves the purpose.
Dear all. What would be the correct way to refer DetectNet in a scientific publication?
Can you please provide a detailed description of the configuration parameters mentioned in this article?
Namely,
detectnet_groundtruth_param {
stride: 16 ---This was explained
scale_cvg: 0.4
gridbox_type: GRIDBOX_MIN
min_cvg_len: 20
coverage_type: RECTANGULAR
image_size_x: 1024 -----This was explained
image_size_y: 512 -----This was explained
obj_norm: true
crop_bboxes: false
}
I actually can guess what the following does from their names but your input is appreciated.
detectnet_augmentation_param {
crop_prob: 1.0
shift_x: 32
shift_y: 32
scale_prob: 0.4
scale_min: 0.8
scale_max: 1.2
flip_prob: 0.5
rotation_prob: 0.0
max_rotate_degree: 5.0
hue_rotation_prob: 0.8
hue_rotation: 30.0
desaturation_prob: 0.8
desaturation_max: 0.8
}