A clear and concise description of the bug or issue.
Environment
TensorRT Version: 8.4.1.5 GPU Type: NVIDIA QUADRO M4000 Nvidia Driver Version: 516.01 CUDA Version: 11.7 CUDNN Version: Operating System + Version: Windows 10 Python Version (if applicable): TensorFlow Version (if applicable): 2.3.1 PyTorch Version (if applicable): Baremetal or Container (if container which image + tag):
Steps To Reproduce
Hello, i am facing an issue on my way to process inferences with the following CNN : Densenet201.
I am starting with a TensorFlow model (model format : saved_model.pb). And I want to convert it in the following format → saved_model.trt.
To do so I followed the tutorial from TensorRT Documentation and did these steps :
Transform the tensorflow model in ONNX → python -m tf2onnx.convert --saved-model “.\model_path” --opset 13 --output model.onnx
Use trtexec to transform the model into a .trt file → trtexec --onnx=model.onnx --saveEngine=densenet201.trt
And finally use it in my project, I used the samples provided to guide me in this step.
Unfortunately my results with the .trt model differs from the one with the tensorflow model, but not for all inferences.. I get some predictions similar to the one with tensorflow, and others which are really differents.
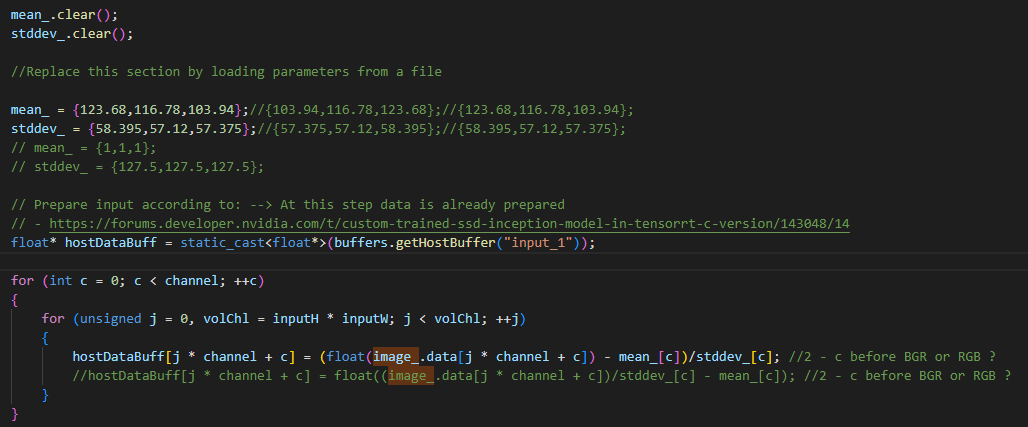
I can also present the way I normalize/standardize data before doing the inference with the model :
Hi,
Please refer to below links related custom plugin implementation and sample:
While IPluginV2 and IPluginV2Ext interfaces are still supported for backward compatibility with TensorRT 5.1 and 6.0.x respectively, however, we recommend that you write new plugins or refactor existing ones to target the IPluginV2DynamicExt or IPluginV2IOExt interfaces instead.
Hi, thank you for your answer.
I am not sure to understand your solution. Should I integrate the preprocessing (normalisation/standardisation) into the model by adding custom layers instead of doing it with the code I shared in my first comment ?
Hello again, I have checked both .trt and .onnx models and the results are the same than the tensorflow model in my benchmark in python. But my benchmark in C++ still give me incorrect results with the same trt model. I also checked the values of the input buffer corresponding to the image i want to infer and the values seems to be the same than the one I have with keras preprocessing function… I used “fasterRCNN” sample provided by NVIDIA as a guide for the preprocessing and inference but it doesn’t seem to be enough…
Do you mean trt model in python gives the same results as onnxruntime, but in the case of c++ they are different?
Could you please share with us the minimal issue repro onnx model and scripts/steps to try from our end for better debugging.