• Hardware (T4/V100/Xavier/Nano/etc)
tesla t4
• Network Type (Detectnet_v2/Faster_rcnn/Yolo_v4/LPRnet/Mask_rcnn/Classification/etc)
action_recognition_net
• TLT Version (Please run “tlt info --verbose” and share “docker_tag” here)
format_version: 2.0
toolkit_version: 4.0.1
published_date: 03/06/2023
• Training spec file(If have, please share here)
train_rgb_3d_finetune.yaml:
output_dir: /results/rgb_3d_ptm
encryption_key: nvidia_tao
model_config:
model_type: rgb
backbone: resnet18
rgb_seq_length: 3
input_type: 3d
sample_strategy: consecutive
dropout_ratio: 0.0
train_config:
optim:
lr: 0.001
momentum: 0.9
weight_decay: 0.0001
lr_scheduler: MultiStep
lr_steps: [5, 15, 20]
lr_decay: 0.1
epochs: 20
checkpoint_interval: 1
dataset_config:
train_dataset_dir: /data/train
val_dataset_dir: /data/test
label_map:
throw: 0
output_shape:
- 224
- 224
batch_size: 32
workers: 8
clips_per_video: 5
augmentation_config:
train_crop_type: no_crop
horizontal_flip_prob: 0.5
rgb_input_mean: [0.5]
rgb_input_std: [0.5]
val_center_crop: False
• How to reproduce the issue ? (This is for errors. Please share the command line and the detailed log here.)
CLI:
print("Train RGB only model with PTM")
!tao action_recognition train \
-e $SPECS_DIR/train_rgb_3d_finetune.yaml \
-r $RESULTS_DIR/rgb_3d_ptm \
-k $KEY \
model_config.rgb_pretrained_model_path=$RESULTS_DIR/pretrained/actionrecognitionnet_vtrainable_v1.0/resnet18_3d_rgb_hmdb5_32.tlt \
model_config.rgb_pretrained_num_classes=5
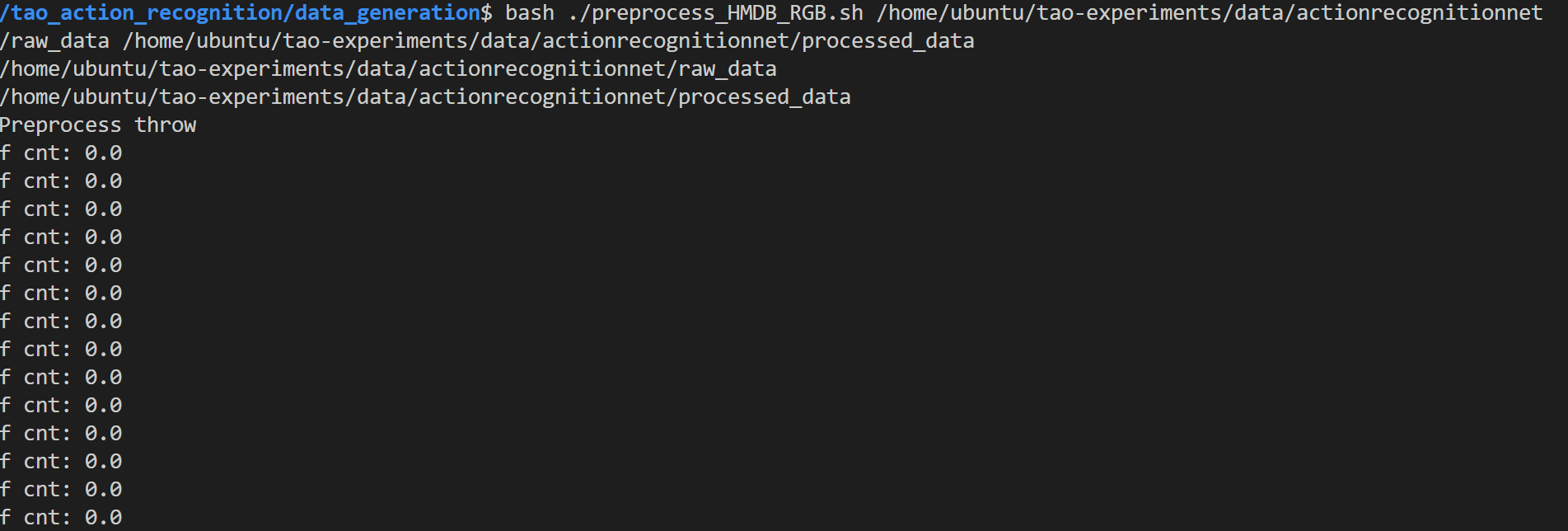
I tried to train the model with custom action recognition for ‘throw’ but it is giving me this error as shown below:
Error Log:
Train RGB only model with PTM
2023-05-23 11:11:12,944 [INFO] root: Registry: ['nvcr.io']
2023-05-23 11:11:12,998 [INFO] tlt.components.instance_handler.local_instance: Running command in container: nvcr.io/nvidia/tao/tao-toolkit:4.0.0-pyt
ANTLR runtime and generated code versions disagree: 4.8!=4.9.3
ANTLR runtime and generated code versions disagree: 4.8!=4.9.3
[NeMo W 2023-05-23 11:11:26 nemo_logging:349] <frozen cv.action_recognition.scripts.train>:81: UserWarning:
'train_rgb_3d_finetune.yaml' is validated against ConfigStore schema with the same name.
This behavior is deprecated in Hydra 1.1 and will be removed in Hydra 1.2.
See https://hydra.cc/docs/next/upgrades/1.0_to_1.1/automatic_schema_matching for migration instructions.
Created a temporary directory at /tmp/tmpuro6y_xl
Writing /tmp/tmpuro6y_xl/_remote_module_non_scriptable.py
loading trained weights from /results/pretrained/actionrecognitionnet_vtrainable_v1.0/resnet18_3d_rgb_hmdb5_32.tlt
ResNet3d(
(conv1): Conv3d(3, 64, kernel_size=(5, 7, 7), stride=(2, 2, 2), padding=(2, 3, 3), bias=False)
(bn1): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool3d(kernel_size=(1, 3, 3), stride=2, padding=(0, 1, 1), dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock3d(
(conv1): Conv3d(64, 64, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv3d(64, 64, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(bn2): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock3d(
(conv1): Conv3d(64, 64, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv3d(64, 64, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(bn2): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock3d(
(conv1): Conv3d(64, 128, kernel_size=(3, 3, 3), stride=(1, 2, 2), padding=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv3d(128, 128, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(bn2): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv3d(64, 128, kernel_size=(1, 1, 1), stride=(1, 2, 2), bias=False)
(1): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock3d(
(conv1): Conv3d(128, 128, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv3d(128, 128, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(bn2): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock3d(
(conv1): Conv3d(128, 256, kernel_size=(3, 3, 3), stride=(1, 2, 2), padding=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv3d(256, 256, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(bn2): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv3d(128, 256, kernel_size=(1, 1, 1), stride=(1, 2, 2), bias=False)
(1): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock3d(
(conv1): Conv3d(256, 256, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv3d(256, 256, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(bn2): BatchNorm3d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock3d(
(conv1): Conv3d(256, 512, kernel_size=(3, 3, 3), stride=(1, 2, 2), padding=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv3d(512, 512, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(bn2): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv3d(256, 512, kernel_size=(1, 1, 1), stride=(1, 2, 2), bias=False)
(1): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock3d(
(conv1): Conv3d(512, 512, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(bn1): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv3d(512, 512, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1), bias=False)
(bn2): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avg_pool): AdaptiveAvgPool3d(output_size=(1, 1, 1))
(fc_cls): Linear(in_features=512, out_features=1, bias=True)
)
[NeMo W 2023-05-23 11:11:31 nemo_logging:349] /opt/conda/lib/python3.8/site-packages/pytorch_lightning/trainer/connectors/callback_connector.py:151: LightningDeprecationWarning: Setting `Trainer(checkpoint_callback=False)` is deprecated in v1.5 and will be removed in v1.7. Please consider using `Trainer(enable_checkpointing=False)`.
rank_zero_deprecation(
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
Missing logger folder: /results/rgb_3d_ptm/lightning_logs
Train dataset samples: 70
Validation dataset samples: 30
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
Adjusting learning rate of group 0 to 1.0000e-03.
| Name | Type | Params
--------------------------------------------
0 | model | ResNet3d | 33.2 M
1 | train_accuracy | Accuracy | 0
2 | val_accuracy | Accuracy | 0
--------------------------------------------
33.2 M Trainable params
0 Non-trainable params
33.2 M Total params
132.742 Total estimated model params size (MB)
Sanity Checking: 0it [00:00, ?it/s][NeMo W 2023-05-23 11:11:31 nemo_logging:349] <frozen cv.action_recognition.dataloader.frame_sampler>:63: RuntimeWarning: divide by zero encountered in remainder
Error executing job with overrides: ['output_dir=/results/rgb_3d_ptm', 'encryption_key=nvidia_tao', 'model_config.rgb_pretrained_model_path=/results/pretrained/actionrecognitionnet_vtrainable_v1.0/resnet18_3d_rgb_hmdb5_32.tlt', 'model_config.rgb_pretrained_num_classes=5']
An error occurred during Hydra's exception formatting:
AssertionError()
Traceback (most recent call last):
File "/opt/conda/lib/python3.8/site-packages/hydra/_internal/utils.py", line 252, in run_and_report
assert mdl is not None
AssertionError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "</opt/conda/lib/python3.8/site-packages/nvidia_tao_pytorch/cv/action_recognition/scripts/train.py>", line 3, in <module>
File "<frozen cv.action_recognition.scripts.train>", line 81, in <module>
File "<frozen cv.super_resolution.scripts.configs.hydra_runner>", line 99, in wrapper
File "/opt/conda/lib/python3.8/site-packages/hydra/_internal/utils.py", line 377, in _run_hydra
run_and_report(
File "/opt/conda/lib/python3.8/site-packages/hydra/_internal/utils.py", line 294, in run_and_report
raise ex
File "/opt/conda/lib/python3.8/site-packages/hydra/_internal/utils.py", line 211, in run_and_report
return func()
File "/opt/conda/lib/python3.8/site-packages/hydra/_internal/utils.py", line 378, in <lambda>
lambda: hydra.run(
File "/opt/conda/lib/python3.8/site-packages/hydra/_internal/hydra.py", line 111, in run
_ = ret.return_value
File "/opt/conda/lib/python3.8/site-packages/hydra/core/utils.py", line 233, in return_value
raise self._return_value
File "/opt/conda/lib/python3.8/site-packages/hydra/core/utils.py", line 160, in run_job
ret.return_value = task_function(task_cfg)
File "<frozen cv.action_recognition.scripts.train>", line 75, in main
File "<frozen cv.action_recognition.scripts.train>", line 64, in run_experiment
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 771, in fit
self._call_and_handle_interrupt(
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 724, in _call_and_handle_interrupt
return trainer_fn(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 812, in _fit_impl
results = self._run(model, ckpt_path=self.ckpt_path)
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1237, in _run
results = self._run_stage()
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1324, in _run_stage
return self._run_train()
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1346, in _run_train
self._run_sanity_check()
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1414, in _run_sanity_check
val_loop.run()
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/loops/base.py", line 204, in run
self.advance(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/loops/dataloader/evaluation_loop.py", line 153, in advance
dl_outputs = self.epoch_loop.run(self._data_fetcher, dl_max_batches, kwargs)
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/loops/base.py", line 204, in run
self.advance(*args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/loops/epoch/evaluation_epoch_loop.py", line 111, in advance
batch = next(data_fetcher)
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/utilities/fetching.py", line 184, in __next__
return self.fetching_function()
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/utilities/fetching.py", line 259, in fetching_function
self._fetch_next_batch(self.dataloader_iter)
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/utilities/fetching.py", line 273, in _fetch_next_batch
batch = next(iterator)
File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 681, in __next__
data = self._next_data()
File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1374, in _next_data
return self._process_data(data)
File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1400, in _process_data
data.reraise()
File "/opt/conda/lib/python3.8/site-packages/torch/_utils.py", line 543, in reraise
raise exception
IndexError: Caught IndexError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/_utils/worker.py", line 302, in _worker_loop
data = fetcher.fetch(index)
File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/_utils/fetch.py", line 49, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/opt/conda/lib/python3.8/site-packages/torch/utils/data/_utils/fetch.py", line 49, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "<frozen cv.action_recognition.dataloader.ar_dataset>", line 239, in __getitem__
File "<frozen cv.action_recognition.dataloader.ar_dataset>", line 203, in get_frames
IndexError: list index out of range
Telemetry data couldn't be sent, but the command ran successfully.
[Error]: <urlopen error [Errno -2] Name or service not known>
Execution status: FAIL
2023-05-23 11:11:36,292 [INFO] tlt.components.docker_handler.docker_handler: Stopping container.