Hi @Morganh,
The below mentioned are the files present in tlt_pretrained_models that I have earlier used for running the FacDetectIR pretrained model.
glueck@gluecktx2DS5:/opt/nvidia/deepstream/deepstream-5.1/samples/configs/tlt_pretrained_models$ cat config_infer_primary_facedetectir.txt
################################################################################
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.
################################################################################
[property]
gpu-id=0
net-scale-factor=0.0039215697906911373
tlt-model-key=tlt_encode
tlt-encoded-model=../../models/tlt_pretrained_models/facedetectir/resnet18_facedetectir_pruned.etlt
labelfile-path=labels_facedetectir.txt
int8-calib-file=../../models/tlt_pretrained_models/facedetectir/facedetectir_int8.txt
model-engine-file=../../models/tlt_pretrained_models/facedetectir/resnet18_facedetectir_pruned.etlt_b1_gpu0_int8.engine
input-dims=3;240;384;0
uff-input-blob-name=input_1
batch-size=1
process-mode=1
model-color-format=0
## 0=FP32, 1=INT8, 2=FP16 mode
network-mode=1
num-detected-classes=1
interval=0
gie-unique-id=1
output-blob-names=output_bbox/BiasAdd;output_cov/Sigmoid
[class-attrs-all]
pre-cluster-threshold=0.2
group-threshold=1
## Set eps=0.7 and minBoxes for cluster-mode=1(DBSCAN)
eps=0.2
#minBoxes=3
glueck@gluecktx2DS5:/opt/nvidia/deepstream/deepstream-5.1/samples/configs/tlt_pretrained_models$ cat deepstream_app_source1_facedetectir.txt
################################################################################
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.
################################################################################
[application]
enable-perf-measurement=1
perf-measurement-interval-sec=1
[tiled-display]
enable=1
rows=1
columns=1
width=1280
height=720
gpu-id=0
[source0]
enable=1
#Type - 1=CameraV4L2 2=URI 3=MultiURI
type=2
num-sources=1
#uri=file://../../streams/sample_1080p_h265.mp4
uri=rtsp://root:Glueck321@10.0.1.36/axis-media/media.amp?streamprofile=H264
gpu-id=0
[streammux]
gpu-id=0
batch-size=1
batched-push-timeout=40000
## Set muxer output width and height
width=1920
height=1080
[sink0]
enable=1
#Type - 1=FakeSink 2=EglSink 3=File
type=2
sync=0
source-id=0
gpu-id=0
[osd]
enable=1
gpu-id=0
border-width=3
text-size=15
text-color=1;1;1;1;
text-bg-color=0.3;0.3;0.3;1
font=Arial
[primary-gie]
enable=1
gpu-id=0
# Modify as necessary
model-engine-file=../../models/tlt_pretrained_models/facedetectir/resnet18_facedetectir_pruned.etlt_b1_gpu0_int8.engine
batch-size=1
#Required by the app for OSD, not a plugin property
bbox-border-color0=1;0;0;1
bbox-border-color1=0;1;1;1
bbox-border-color2=0;0;1;1
bbox-border-color3=0;1;0;1
gie-unique-id=1
config-file=config_infer_primary_facedetectir.txt
[sink1]
enable=0
type=3
#1=mp4 2=mkv
container=1
#1=h264 2=h265 3=mpeg4
codec=1
#encoder type 0=Hardware 1=Software
enc-type=0
sync=0
bitrate=2000000
#H264 Profile - 0=Baseline 2=Main 4=High
#H265 Profile - 0=Main 1=Main10
profile=0
output-file=out.mp4
source-id=0
[sink2]
enable=0
#Type - 1=FakeSink 2=EglSink 3=File 4=RTSPStreaming 5=Overlay
type=4
#1=h264 2=h265
codec=1
#encoder type 0=Hardware 1=Software
enc-type=0
sync=0
bitrate=4000000
#H264 Profile - 0=Baseline 2=Main 4=High
#H265 Profile - 0=Main 1=Main10
profile=0
# set below properties in case of RTSPStreaming
rtsp-port=8554
udp-port=5400
[tracker]
enable=1
tracker-width=640
tracker-height=384
#ll-lib-file=/opt/nvidia/deepstream/deepstream-5.1/lib/libnvds_mot_iou.so
#ll-lib-file=/opt/nvidia/deepstream/deepstream-5.1/lib/libnvds_nvdcf.so
ll-lib-file=/opt/nvidia/deepstream/deepstream-5.1/lib/libnvds_mot_klt.so
#ll-config-file required for DCF/IOU only
ll-config-file=../deepstream-app/tracker_config.yml
#ll-config-file=iou_config.txt
gpu-id=0
#enable-batch-process applicable to DCF only
enable-batch-process=1
[tests]
file-loop=1
I usually run the file using the command;
deepstream-app -c deepstream_app_source1_facedetectir.txt
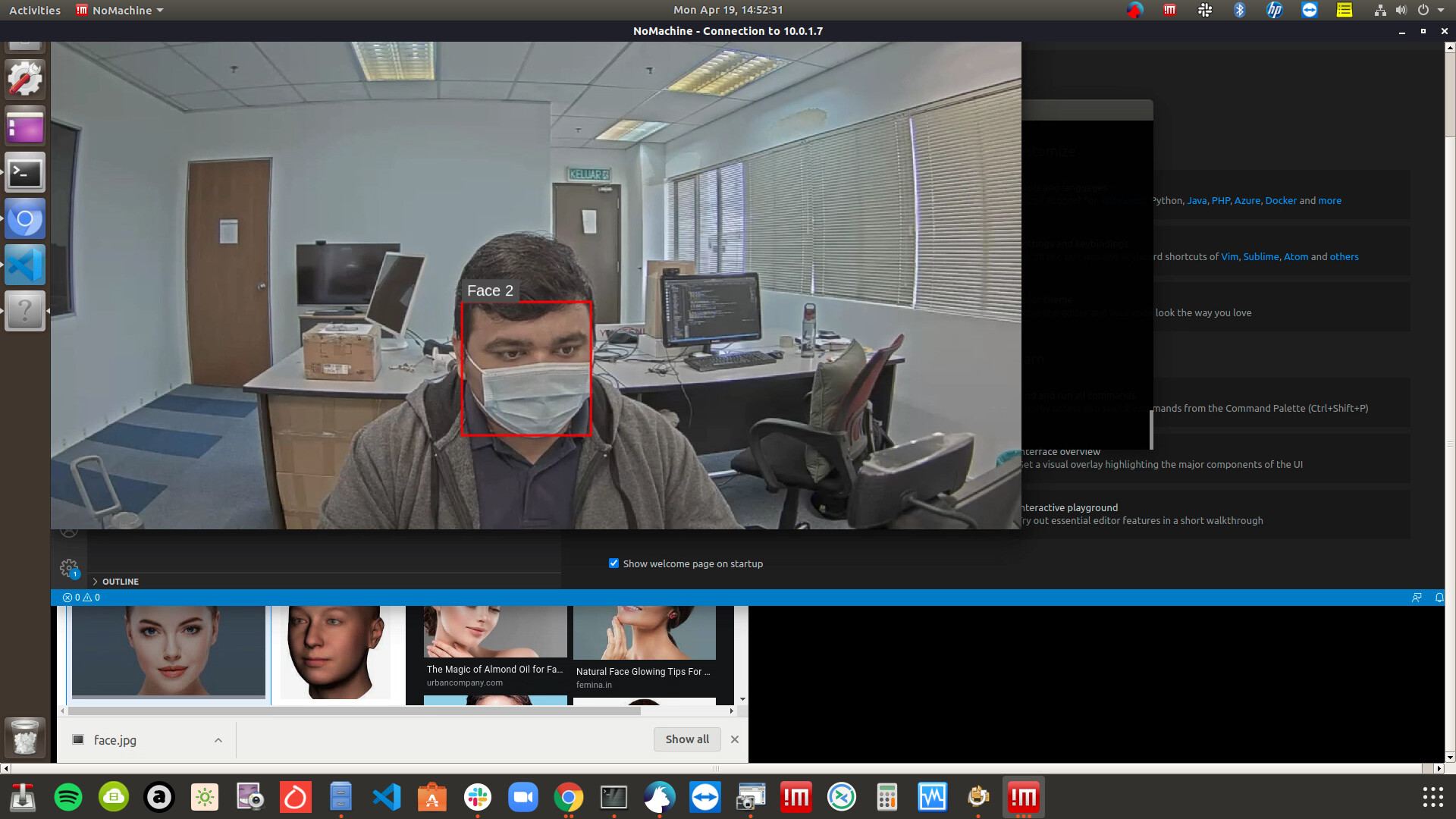
This is the output where face is detected.:
Also while running this I see a warning in the console that INT8 not supported trying FP16.
I want to run the same file with the custom model that I trained in any format INT8 or FP16 where the cell below is the only command mentioned in the ipynb for converting. There is no exporting step.

I followed the detectnet_v2 and converted the calibration.bin and now i want to know a way through which i can test on a real time stream either with INT8 or FP16.??
These files where generated by just replacing the paths in the cells to the trained resnet18_detector.etlt in the facenet directory in tlt-experiments.