I’m working on Windows 10 with an GRID RTX6000-4Q
I use CUDA v12.5
I’m trying to optimize my process of grabbing a desktop with DXGI and encoding it with the GPU’s functions.
In the process of trying to optimize that, I’ve managed to successfully do the grab and encode part. The part inbetween is kinda bothering me because i did a copy from the DXGI grabbed frame to have a CPU readable frame and encode it with CUDA.
The current process I had that worked but not very optimal is like this :
Grab frames from desktop with DXGI → CopyRessources(…) So i can have a CPU Readable frame → Map the frames with the CPU so I can have a Buffer that can be encoded → Encode with CUDA
What I want is :
Grab frames from desktop with DXGI → Map the frames with the /!\ GPU /!\ → Encode with CUDA.
So in order to do that, from what I read I some documentations is that I had to use this function :
In order to allow cuda mapping functions to perform the mappings.
The issue is this function doesn’t work since it returns a CUDA_ERROR_INVALID_VALUE
The cudaGraphicsResource is declared like so
I tried to verify the desc from my frame but doesn’t seems wrong, here’s my logs of the desc :
Texture Description:
Width: 1920
Height: 1080
MipLevels: 1
ArraySize: 1
Format: 87
SampleDesc.Count: 1
SampleDesc.Quality: 0
Usage: 0
BindFlags: 40
CPUAccessFlags: 0
MiscFlags: 10496
Changed my flag because it was wrong, Now It returns 400 which correspond to CUDA_ERROR_INVALID_HANDLE ( This indicates that a resource handle passed to the API call was not valid. Resource handles are opaque types like CUstream and CUevent.)
What does it mean ? since the function is supposed to be the one initializing the handle
I haven’t studied your code but note that you seem to be using the CUDA driver API (the cudaGraphicsD3D11RegisterResource mentioned in the title is from the CUDA runtime API). The driver API for typical usage normally requires a properly initialized CUDA context, and that could be an example of a resource handle that the interop API call is (implicitly) using (although if you had completely skipped that step I would expect a “not initialized” error message or similar).
Yes that’s right, I’m using CUDA driver API, context was set in the constructor of CUDAH264 class using .
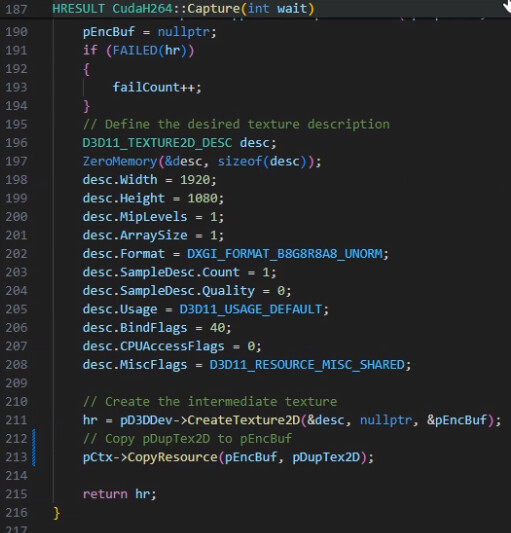
After some debugging I found out that maybe it came from my Direct3D texture’s description (the ID3D11Resource*). So I tried to use cudaGraphicsD3D11RegisterResource with a copy of my DXGI desktop grabbed texture (ID3D11Resource* pDupTex2D variable in my code) with a slight change in the desc. And then the function cudaGraphicsD3D11RegisterResource worked with a texture that had in it’s desc → MiscFlags = D3D11_RESOURCE_MISC_SHARED.
TLDR : My texture was the reason why I had CUDA_ERROR_INVALID_HANDLE because of a MiscFlags field in the texture’s description.
Although I don’t like the idea of having to do a copy of my frame everytime i grab it, I guess i don’t have the choice if it’s required for CUDA runtime API functions
But now I’m encountering another error with mapping now, it’s returning 400 too it’s maybe my texture’s desc again ?
Yeah I’m stuck again on another function.
So here I made a copy with createTexture2D and CopyResources to solve my previous problem with the RegisterResource
cuGraphicsMapResources(…) doesn’t seem to fail either but i’m confused about the cuStream argument, is it like an API call you have to wait when it’s mapping ?
cuGraphicsResourceGetMappedPointer return a NULL dptr with cudaStatus being 400 (CUDA_ERROR_INVALID_HANDLE) again so again a invalid handle (Could the cause be that i don’t wait the cuGraphicsMapResources with the cuStream argument ?)
why not do it like the sample code I linked? see here
A texture used as interop will normally lead to a cudaArray (or cuArray) resource on the CUDA side. subresourcegetmappedarray makes that available. getmappedpointer is for getting a pointer to linear memory - not possible with an array based interop.
And I would imagine the stream argument does what it does on nearly any other function parameter/argument usage. When you pass a stream argument to a CUDA API function, the typical reason is to submit the work associated with that function in a stream-oriented way, that is, where the rules for stream-oriented work execution apply.