I’m learning gemm using tensorcores. I find the example on cuda C++ programming guide.
But I found the result using tensor core is wrong compared with the result using pytorch.
Why is that? Is there anything wrong with my code? Thank you!
#include <vector>
#include <stdio.h>
#include <mma.h>
#include <cuda_fp16.h>
using namespace nvcuda;
__global__ void wmma_ker(half *a, half *b, float *c) {
wmma::fragment<wmma::matrix_a, 16, 16, 16, half, wmma::row_major> a_frag;
wmma::fragment<wmma::matrix_b, 16, 16, 16, half, wmma::col_major> b_frag;
wmma::fragment<wmma::accumulator, 16, 16, 16, float> c_frag;
wmma::fill_fragment(c_frag, 0.0f);
wmma::load_matrix_sync(a_frag, a, 16);
wmma::load_matrix_sync(b_frag, b, 16);
wmma::mma_sync(c_frag, a_frag, b_frag, c_frag);
wmma::store_matrix_sync(c, c_frag, 16, wmma::mem_row_major);
}
void test_gpu(int m, int n, int k) {
std::vector<__half> a, b;
a.resize(m * k);
b.resize(n * k);
std::vector<float> c;
c.resize(m * n, 0);
printf("A:\n");
for(int i = 0; i < m * k; i++) {
a[i] = i % 5;
printf("%.2f\t", (float)a[i]);
if((i+1)%n == 0) printf("\n");
}
printf("B:\n");
for(int i = 0; i < n * k; i++) {
b[i] = i % 5 + i % 4;
printf("%.2f\t", (float)b[i]);
if((i+1)%n == 0) printf("\n");
}
__half * d_a, *d_b;
float *d_c;
cudaMalloc(&d_a, sizeof(__half) * m * k);
cudaMalloc(&d_b, sizeof(__half) * n * k);
cudaMalloc(&d_c, sizeof(float) * m * n);
//transpose(a.data(), m, k);
//transpose(b.data(), k, n);
cudaMemcpy(d_a, a.data(), sizeof(__half) * m * k, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b.data(), sizeof(__half) * n * k, cudaMemcpyHostToDevice);
//gemm_cpu(a.data(), b.data(), c.data(), m, n, k);
wmma_ker<<<1, 32>>>(d_a, d_b, d_c);
cudaMemcpy(c.data(), d_c, sizeof(float) * m * n, cudaMemcpyDeviceToHost);
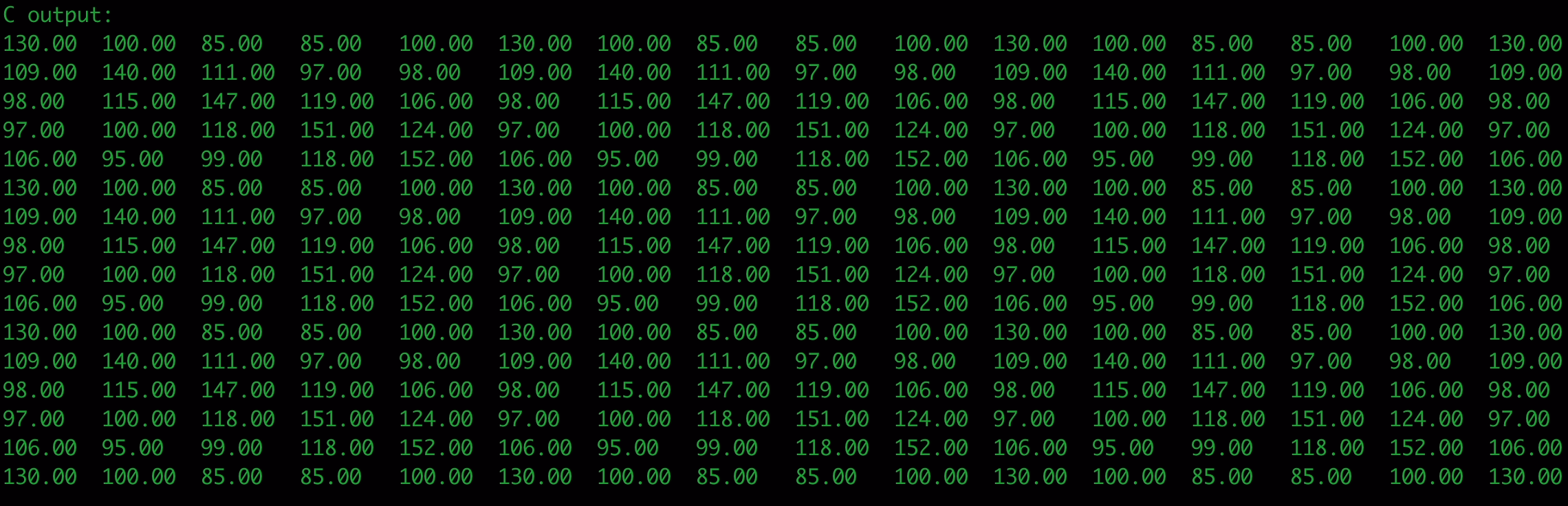
printf("C output:\n");
for(int i = 0; i < m * n; i++) {
printf("%.2f\t", (float)c[i]);
if((i+1)%n == 0) printf("\n");
}
printf("\n");
}
int main() {
test_gpu(16, 16, 16);
return 0;
}
import torch
a = [i%5 for i in range(0, 16 * 16)]
a = torch.Tensor(a).reshape(-1, 16)
b = [i%5 + i % 4 for i in range(0, 16 * 16)]
b = torch.Tensor(b).reshape(-1, 16)
print(a)
print(b)
print(torch.matmul(a, b))
C++ output
python output
