Originally published at: https://developer.nvidia.com/blog/programming-tensor-cores-cuda-9/
Tensor cores provide a huge boost to convolutions and matrix operations. Tensor cores are programmable using NVIDIA libraries and directly in CUDA C++ code. A defining feature of the new Volta GPU Architecture is its Tensor Cores, which give the Tesla V100 accelerator a peak throughput 12 times the 32-bit floating point throughput of the previous-generation…
Tensor-Cores - will it also be available within the next Gamer-GPU (Geforce) ?
That's a good question !
interesting possibilities for crypto currencies using tensor cores...
Which NN framework did you use for Figure4 inference?
This will really help the 3D porn industry, oh and cancer research, possibly...
When is "Titan W" coming out? You know, Two Titan-V's in one card?
Are you waiting for "Windows 4K" to be made?
I concur, I think I even know the theoretical solution: For each instance of CUDA algorithm line calculation, it gets stored in Matrix A until 16 instances are filled, then Stored into B, where their computation is multiplied which ought to lower the the net computation time by 4096 per tensor core utilized.... I've already seen this applied with the cryptonight algorithm, in terms of Hash Calculation however it was insufficient to generate a nonce. Create the nonce with that version of cryptonight and you revolutionize cryptomining!
10 months later, the answer is yes.
Extremely helpful. Thanks as always :)
Question: Do the Tensor cores run concurrently with the CUDA cores? If I were to have my deep learning model cranking away on TCs, could I simultaneously be rendering high quality graphics?
Nice blog but it misses the most important statement - "Tensor Cores require that the Tensors be in NHWC data layout." So if NCHW is given, it transposes it to NHWC.
Can you provide information about relative performance V100 / RTX 2080 TI or V100 / RTX 2080 ?
Thank you
GEMMs that do not satisfy the above rules will fall back to a non-Tensor Core implementation
this sounds like a silent failure, and a really bad thing
i assume hope theres some function to assert or check that TPUs are being used?
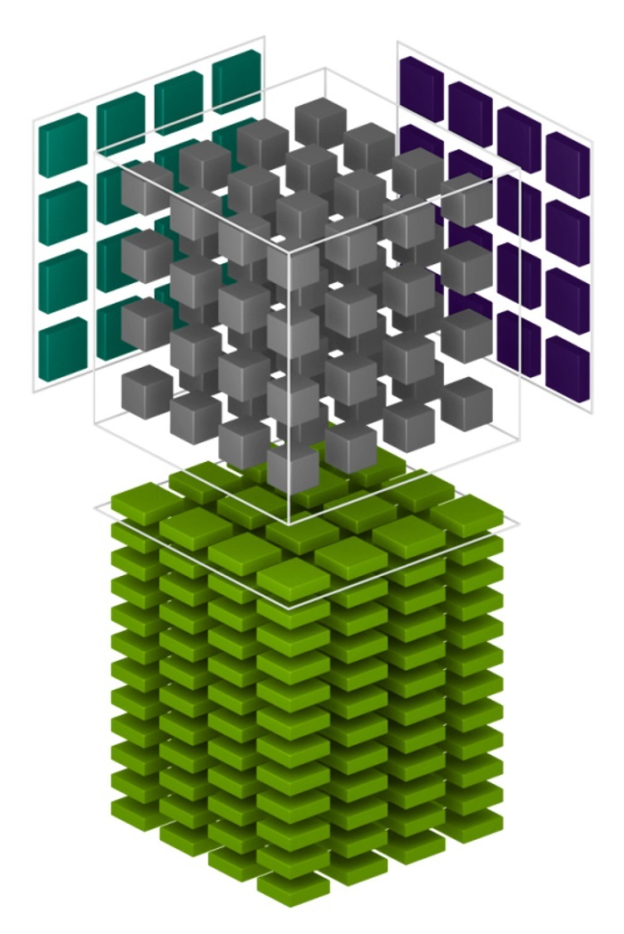
I think there is a technical error in this image https://developer-blogs.nvidia.com/wp-content/uploads/2017/12/tensor_cube_white-624x934.png. There should be 16 green layers instead of 12. As tensor core only performing multiplication of a 4x4 data, as a result 16 -4x4 array will be generated.
{kind=link}
I have a little question for tensor core code example in blog.
Since the threadblock dim3 is (128, 4), namely 16 warps, I think the loop over k is should be 4xWMMA_K which would optimize the performance.
Would this change the loop stride affect the correctness of result ?