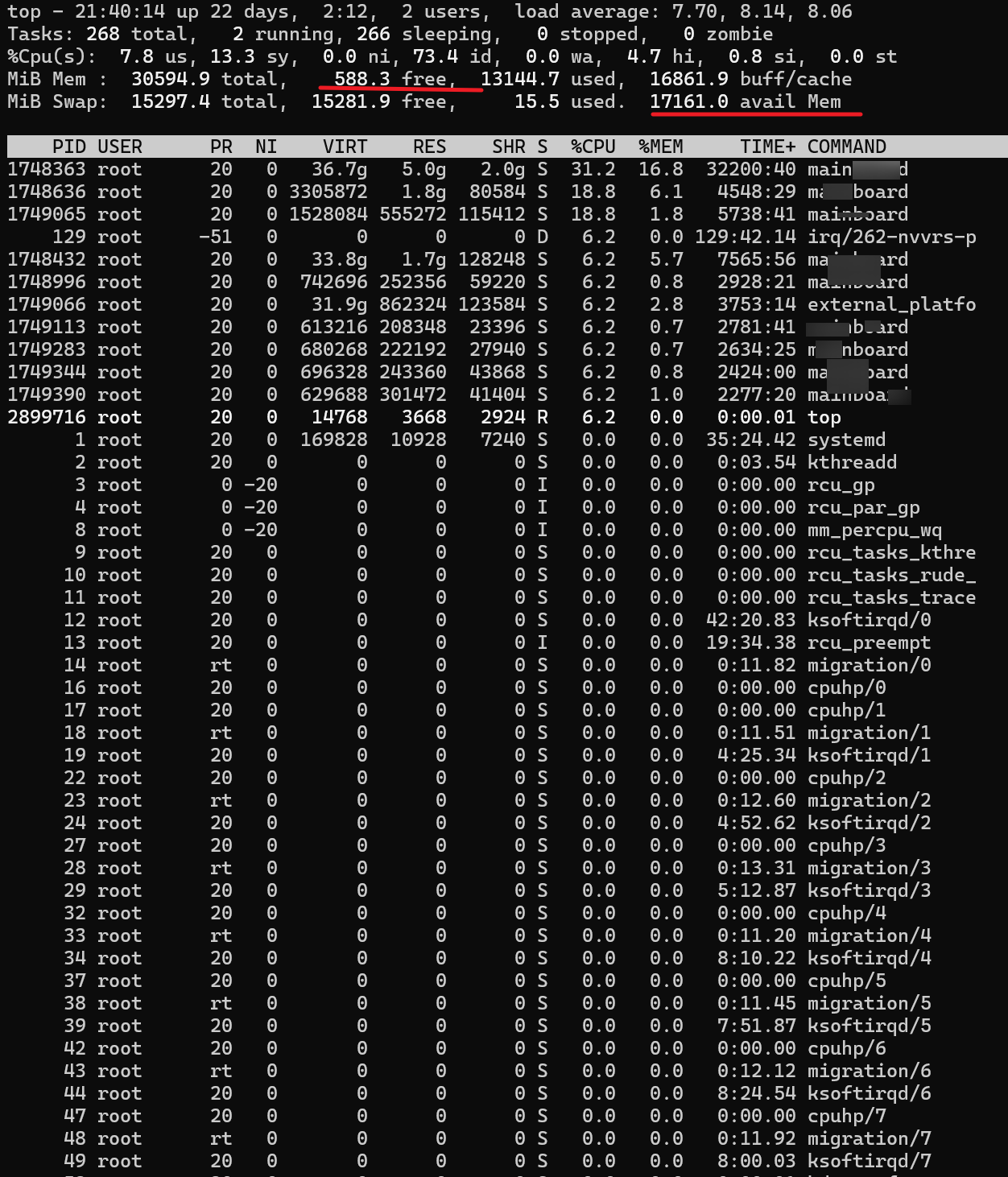
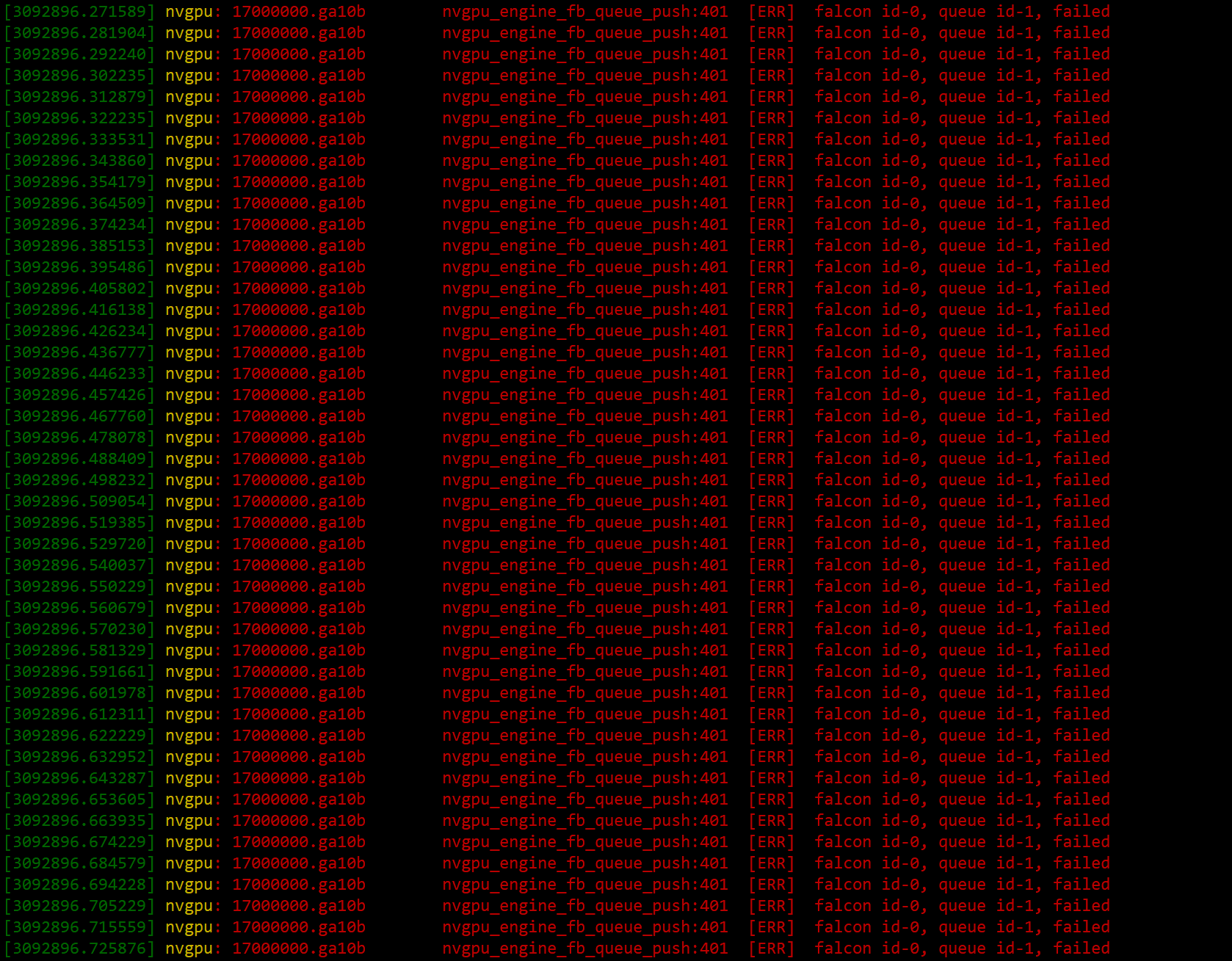
We have a module of AGX Orin (32) in our hands, and after running business for a period of time, the GPU cannot work properly. We are using JetPack 5.1.2. The relevant phenomena are as follows:
- Call CUDA library。test.cu
#include <stdio.h>
#include <cuda_runtime.h>
int main()
{
int count;
cudaGetDeviceCount(&count);
printf("count = %d\n",count);
return 0;
}
nvcc test.cu
./test.out

2、 View/dev/nvgpu node


3、dmesg关于gpu info failed
[4396822.611090] nvgpu: 17000000.ga10b gv100_pmu_lsfm_init_acr_wpr_region:53 [ERR] Failed to execute RPC status=0xfffffff4
[4396822.622334] nvgpu: 17000000.ga10b nvgpu_pmu_lsfm_bootstrap_ls_falcon:107 [ERR] LSF init WPR region failed
[4396822.622628] nvgpu: 17000000.ga10b nvgpu_pmu_lsfm_bootstrap_ls_falcon:128 [ERR] LSF Load failed
[4396822.622882] nvgpu: 17000000.ga10b nvgpu_gr_falcon_load_secure_ctxsw_ucode:714 [ERR] Unable to recover GR falcon
[4396822.623162] nvgpu: 17000000.ga10b nvgpu_gr_falcon_init_ctxsw:159 [ERR] fail
[4396822.623385] nvgpu: 17000000.ga10b nvgpu_cic_mon_report_err_safety_services:92 [ERR] Error reporting is not supported in this platform
[4396822.623718] nvgpu: 17000000.ga10b gr_init_ctxsw_falcon_support:833 [ERR] FECS context switch init error
[4396822.624002] nvgpu: 17000000.ga10b nvgpu_finalize_poweron:1010 [ERR] Failed initialization for: g->ops.gr.gr_init_support
[4396822.650606] nvgpu: 17000000.ga10b gk20a_power_write:127 [ERR] power_node_write failed at busy
[4396833.710180] nvgpu: 17000000.ga10b nvgpu_pmu_cmd_post:591 [ERR] FBQ cmd setup failed
[4396833.710484] nvgpu: 17000000.ga10b nvgpu_pmu_rpc_execute:713 [ERR] Failed to execute RPC status=0xfffffff4, func=0x0
[4396833.710817] nvgpu: 17000000.ga10b gv100_pmu_lsfm_init_acr_wpr_region:53 [ERR] Failed to execute RPC status=0xfffffff4
[4396833.722072] nvgpu: 17000000.ga10b nvgpu_pmu_lsfm_bootstrap_ls_falcon:107 [ERR] LSF init WPR region failed
[4396833.722377] nvgpu: 17000000.ga10b nvgpu_pmu_lsfm_bootstrap_ls_falcon:128 [ERR] LSF Load failed
[4396833.722624] nvgpu: 17000000.ga10b nvgpu_gr_falcon_load_secure_ctxsw_ucode:714 [ERR] Unable to recover GR falcon
[4396833.722910] nvgpu: 17000000.ga10b nvgpu_gr_falcon_init_ctxsw:159 [ERR] fail
[4396833.723122] nvgpu: 17000000.ga10b nvgpu_cic_mon_report_err_safety_services:92 [ERR] Error reporting is not supported in this platform
[4396833.723459] nvgpu: 17000000.ga10b gr_init_ctxsw_falcon_support:833 [ERR] FECS context switch init error
[4396833.723726] nvgpu: 17000000.ga10b nvgpu_finalize_poweron:1010 [ERR] Failed initialization for: g->ops.gr.gr_init_support
[4396833.750693] nvgpu: 17000000.ga10b gk20a_power_write:127 [ERR] power_node_write failed at busy
[4396835.626139] nvgpu: 17000000.ga10b nvgpu_pmu_cmd_post:591 [ERR] FBQ cmd setup failed
[4396835.626429] nvgpu: 17000000.ga10b nvgpu_pmu_rpc_execute:713 [ERR] Failed to execute RPC status=0xfffffff4, func=0x0
[4396835.626782] nvgpu: 17000000.ga10b gv100_pmu_lsfm_init_acr_wpr_region:53 [ERR] Failed to execute RPC status=0xfffffff4
[4396835.638032] nvgpu: 17000000.ga10b nvgpu_pmu_lsfm_bootstrap_ls_falcon:107 [ERR] LSF init WPR region failed
[4396835.638327] nvgpu: 17000000.ga10b nvgpu_pmu_lsfm_bootstrap_ls_falcon:128 [ERR] LSF Load failed
[4396835.638578] nvgpu: 17000000.ga10b nvgpu_gr_falcon_load_secure_ctxsw_ucode:714 [ERR] Unable to recover GR falcon
[4396835.638875] nvgpu: 17000000.ga10b nvgpu_gr_falcon_init_ctxsw:159 [ERR] fail
[4396835.639104] nvgpu: 17000000.ga10b nvgpu_cic_mon_report_err_safety_services:92 [ERR] Error reporting is not supported in this platform
[4396835.639436] nvgpu: 17000000.ga10b gr_init_ctxsw_falcon_support:833 [ERR] FECS context switch init error
[4396835.639702] nvgpu: 17000000.ga10b nvgpu_finalize_poweron:1010 [ERR] Failed initialization for: g->ops.gr.gr_init_support
[4396835.665634] nvgpu: 17000000.ga10b gk20a_power_write:127 [ERR] power_node_write failed at busy
[4396846.765863] nvgpu: 17000000.ga10b nvgpu_pmu_cmd_post:591 [ERR] FBQ cmd setup failed
[4396846.766156] nvgpu: 17000000.ga10b nvgpu_pmu_rpc_execute:713 [ERR] Failed to execute RPC status=0xfffffff4, func=0x0
[4396846.766537] nvgpu: 17000000.ga10b gv100_pmu_lsfm_init_acr_wpr_region:53 [ERR] Failed to execute RPC status=0xfffffff4
[4396846.777774] nvgpu: 17000000.ga10b nvgpu_pmu_lsfm_bootstrap_ls_falcon:107 [ERR] LSF init WPR region failed
[4396846.778082] nvgpu: 17000000.ga10b nvgpu_pmu_lsfm_bootstrap_ls_falcon:128 [ERR] LSF Load failed
[4396846.778331] nvgpu: 17000000.ga10b nvgpu_gr_falcon_load_secure_ctxsw_ucode:714 [ERR] Unable to recover GR falcon
Our equipment is still malfunctioning, please assist in analyzing the cause. We will try our best to continuously power on and restart to destroy the malfunction。