Hi Ruud -- we're working through the details of the release, but DIGITS 5 should be available on AWS by the end of the month.
Cheers!
Has this been released? If no are there beta testers?
Hi Greg, thank you for a very excellent article! Btw, did you use SYNTHIA RAND_CITYSCAPES in this article? If so, I am sorry if this is a bit technical, did you use the label images in the GT/COLOR directory? When I tried it on DIGITS, the image mode is RGBA, while DIGITS expects RGB or pallete mode. Did you convert the label images first to RGB or pallete mode or did you manage to use the data as is? Thank you in advance.
Hi Ricky, I used SYNTHIA_RAND_CVPR2016 for this article. SYNTHIA_RAND_CITYSCAPES comes with different labels in GT/LABELS indeed, which allow for instance-aware image segmentation since they include object instance IDs. As you suggested, you may use the images in GT/COLOR, either by converting them to RGB or making a small modification to the image segmentation extension in DIGITS to ignore the Alpha channel.
Hi Greg, Thanks a lot for the feedback and information!
any update on Digits 5 on AWS?
I'm a little confused, how it is possible? https://uploads.disquscdn.c...
{kind=link}
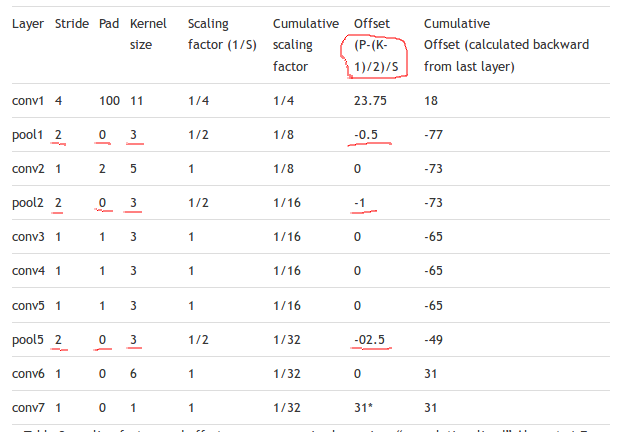
Typos have been corrected on pool2/pool5/conv6 rows.
Okay thanks, I'll await the release then.
For custom dataset preparation, you may want to look to the following, a tool to prepare segmented images & save output in Digits compatible format;
https://alpslabel.wordpress...
Hello Greg,
I think the paragraph "Enabling finer segmentation" refers to this paper: "Improving Fully Convolution Network for Semantic Segmentation" , where authors introduce modified FCN-8s as IFCN-8s.
Then my question is, have you implemented their suggestion? if Yes, where are the prototxt files?
Hello, "Enabling finer segmentation" in my article refers to section 4.2 ("Combining what and where") of the FCN paper. In practice I found FCN-8s to work well. I have not tried IFCN-8s.
I'm using DIGITS 5, but I can't find any pre-trained models. Could you make the .prototxt files that you used in this article available on some web page instead?
Hello, there is a walk-through on https://github.com/NVIDIA/D... with links to a pre-trained model and prototxt for FCN-Alexnet.
Why is the kernel size of the deconvolution layer set at 63, when the stride is 32? Is it always 2*Stride-1 ? When the deconvolution overlaps (which it does here) what is the final class of the output pixel?
Hi Greg,
Thanks for the blog. My question is, In model page, DO I have to set subtract mean to None in Data Transformations for training fcn-alexnet?.
Thanks
SK06
In fcn-alexnet in DIGITS there is a layer named "shift" which subtracts 127 from pixels, which results in an approximate centering of the data around zero. Therefore if you use this example, you should set mean subtraction to None on the model page because the network already does it.
This is the recommended way to set-up an upsampling layer through bilinear interpolation: http://caffe.berkeleyvision...
Hi Greg,
May I ask you what code have you used to create those inferences? (Outside DIGITS)
Why is the Zebra crossing of road labeled as Vegetation even in Ground truthas well as in inferred Pictures.