I have Write a Cuda Kernel, with carefully shared memory arrangement,and it should be bank conflict free.
If I emit the Kernel with only one Block, that is, set GridDim.x, GridDim.y, GridDim.z to 1, and the block contains 2 warps with 64 threads, it shows there are NO Shared load/store bank conflicts by using nsight compute.
But things come different when the GridDim get larger (eg. GridDim.x = 3, GridDim.y = 4, GridDim.z = 256 ), nsight compute shows thousands of shared load/store bank conflicts.
So, How can I locate the code? Does Bank conflict occurs when different warp scheduler access shared memory at the same time ? Is there any way to avoid?
In general shared memory bank conflicts can occur any time two different threads are attempting to access (from the same kernel instruction) locations within shared memory for which the lower 4 (pre-cc2.0 devices) or 5 bits (cc2.0 and newer devices) of the address are the same.
Wondering about how to avoid bank conflict from two different threads of different warps running on different processing blocks of a SM?
BTW, short scoreboard stall will (also) occur and be reported by NSight Compute, for bank conflict of this kind, am I right?
There is no such animal. Bank conflicts only occur in the context of a single instruction, issued to a single warp. Only threads in the same warp have the possibility to create bank conflicts.
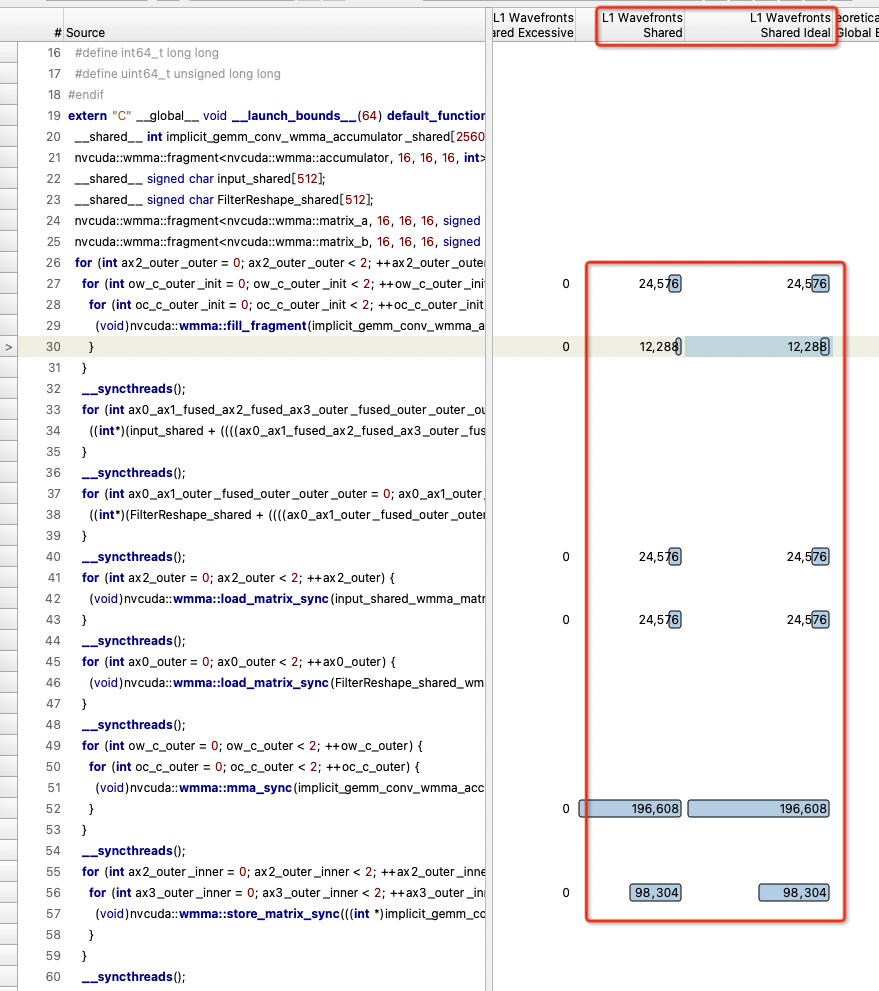
nsight compute has a code (source, sass) page, that localizes reports to specific lines of code. This blog (all 3 parts) may help. Part 2, figure 5 shows an example of the source code page.
In the source code page, I checked the ‘L1 Wavefronts Shared’ and ‘L1 Wavefronts Shared Ideal’ , values are all same in these 2 columns. Does this mean the source code achieved bank conflict free?
I probably wouldn’t be able to answer further questions without having the tool in front of me and access to the code to study. You may get better help on the nsight compute forum.