I’m doing a simulation with PhysX 3.4 SDK that isn’t intended for realtime applications.
When I increase the number of scene rididbodies past 65536, the simulation goes haywire (presumably because of some internal rb limit). According to the docs of v3.2.1, the internal scene-query limit 65536 was removed. Has something changed or is there a flag I need to enable to use more than 65536 rigidbodies? I already increased maxNbContactDataBlocks but that had no effect.
Do you have latest PhysX 3.4 release from GitHub? There should not be a limit on the number of bodies but there was a bug where a 16-bit counter was still being used to keep track of the number of contacts effecting a body that should have been fixed in that release.
I’m using the version of 3.4 downloaded on May 17, 2017. Was the issue fixed since then?
Edit: I don’t see any commits in the repository since that date, so it seems like I have the most up-to-date version.
Shouldn’t be. The fix was submitted in March and should have be in the latest release (and probably the release before that).
Could you provide a little more detail? What config are you using (win32, win64 etc.). Are you using GPU or CPU rigid body simulation etc.
Here’s a video showing the issue. I spawn 100,000 spheres (using sphere shape colliders) from frames 0-300 (in a front-facing orthographic viewport). You can see that once 65536 spheres have spawned (around frame 195), all spheres after that point start getting wonky collisions (falling through the ground, flying up in the air, etc).
This is in a 64 bit app, CPU only.
Also since you’re familiar with this topic…is there a GPU rigidbody limit? Because when I implemented GRBs with this same setup, once I surpassed around 15k rigidbodies they’d all go crazy (not just ignoring gravity or collisions…but literally just jittering all over the world in random locations) and the app would soon crash. I read about a 256mb memory limit for GPU sims and assumed I was just hitting it…but maybe that was a separate issue? Does a GPU sim have a rigidbody cap or is it supposed to be unlimited too? I was using a GTX 680 to sim and the same version of the SDK.
As with the CPU rigid bodies, there shouldn’t really be a hard limit on the number of bodies the GPU simulation can handle. If you take a look at the GRB Kapla demo that comes with PhysX 3.4 on GitHub, that has scenes that exceed 15,000 rigid bodies.
The issue is most likely related to the memory that’s reserved for contacts and constraints for the GPU simulation. Unfortunately, there’s not a clean way to resize these buffers from within the GPU simulation kernels so it’s currently the user’s responsibility to reserve enough space for the simulation to work in. You do this by adjusting the settings in PxgDynamicsMemoryConfig in PxSceneDesc. The default settings are OK for most game-like scenes, and cover up to around 15,000 bodies (more or less depending on how complex the geometries are etc.) but you’ll need to increase these buffer sizes to simulate larger scenes. You should get warnings emitted from the simulation telling you to increase buffers when the simulation finds that buffers are too small. The intention is for these warnings to be emitted and the simulation to continue, but with some contacts ignored. We haven’t quite reached the stage where it’s completely robust to fail cases yet - we’ll get there soon hopefully.
If you take a look at the kapla demo source code in SampleViewer.cpp, you’ll see that we doubled the capacity of these buffers to make sure that we had enough memory. Can you try doing this to see if it resolves your issue? Depending on how many objects you’re simulating, you may need to more than double these buffers.
A few caveats:
(1) Your GTX680 only has 2GB RAM so you might hit allocation failures if you increase these buffers significantly larger because the default sizes add up to around ~100MB.
(2) GPU acceleration is only provided for convex and box primitives (against convexes, boxes, meshes and heightfields). Any contact gen involving spheres, capsules or plane primitives will be handled by the CPU. So, if you’re simulating scenes with mainly simple primitives like spheres, GPU performance improvements will be limited to the solver and broad phase. It’ll still be quicker but you won’t get as much of a performance bump as you would using more complex geometries.
Hope this helps
Thanks for that explanation. It’s good to know that I can increase the memory limit like that. I think for now I’ll just avoid GRBs though due to the instability/crashing I experienced once the memory limit is reached. My application is designed to simulate hundreds of thousands of RBs, so even being able to max out the video card memory would still eventually lead to crashes if the sim doesn’t simply fall back to CPU and continue smoothly once gpu memory is maxed.
Any further ideas about the CPU sim instability past 65536, as demonstrated in my video? Having GRB would be a nice bonus, but the real problem right now is that CPU can’t handle high numbers of RBs either.
Thanks for reporting this.
We’ve been able to reproduce the issue. We did lift the internal limits on the number of bodies that could be simulated and we’ve tested scenes with over 100,000 bodies internally. However, this was mainly tested using the GPU solver because performance was unacceptably slow on CPU. If you do use the GPU solver (and set memory buffers large-enough), the current GPU code does handle > 65536 bodies just fine.
After a bit of investigation, it looks like the problem you noticed is caused by a 16-bit index in the CPU solver to index into the some body data during constraint preparation. We’ve fixed the issue locally and my repro of your scene seems to function correctly now.
I’ll do a bit more testing and hopefully we can include this fix in the next 3.4 patch
That’s great news! Thanks for looking into it :)
I’ll do a bit more testing with GRBs in the meantime and let you know if I run into the crashing issue again once memory limits are increased.
I did a little more digging into why GRB were crashing (using the exact setup above, with the only change being the collision shapes are switched to boxes instead of spheres, and only 10k rigidbodies are spawned).
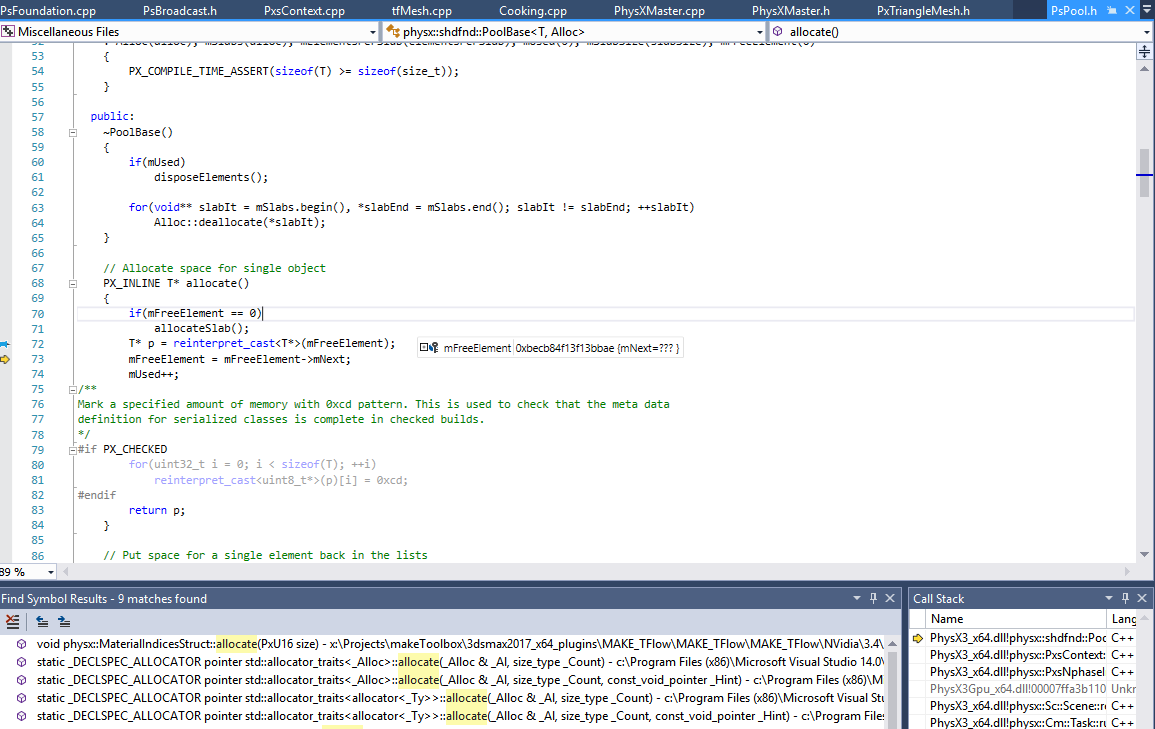
I spawn all 10k boxes from frames 0-50, and then get a repeatable crash around frame 250, long after the boxes settle on the ground. The crash only occurs in GRB/GPU mode and disappears when switching back to CPU mode. It happens in PsPool.h and it seems like it’s caused by a reinterpret_cast to a corrupted pointer. Here’s a screencap of the error in VS2015:

The interesting thing is that I didn’t enable ePCM in my sceneDesc, but the crash happens in an ePCM block of code. Turns out that even though the docs state that ePCM is off by default, when you instantiate a PxSceneDesc using a PxToleranceScale, ePCM is turned on in the constructor. By manually disabling ePCM after construction of the sceneDesc, I avoid the crash and GRB/GPU mode works fine and prints out error messages when memory limits are reached instead of crashing. I guess the downside is that ePCM can’t be used.
Once ePCM is off, I’ve tested 150k box rigidbodies spawning over various static colliders across a 300 frame interval and haven’t had any crashes occur…even without increasing the GPU memory limits. I get buffer overflow error limit messages and missed contacts (because I didn’t increase GPU memory limits), but not hard crashing. So that’s good.
Edit: scratch the last part. If I replay my scene enough times CUDA will still crash. At the start of each play I initialize all my scene variables (foundation, physics, cudacontextmanager, etc)…and at the end of each play I release them all…is there something else I need to do to clean up CUDA memory?
PCM is on by default in PhysX 3.4. It should be documented as such. I haven’t seen that first crash before. What are your simulation shapes? Is the ground a PxPlaneGeometry? The reason I ask is that the code you point to is the CPU fallback contact gen. Are there any warnings issues around this time prior to the crash? Those may give us some clues.
If you are getting buffer size warnings and you haven’t increased the memory buffers, you will potentially see some crashes. As mentioned, there are some portions of code that are robust to running out of buffer space, and some portions that are not and may write past the end of their buffers. If you see a warning about a buffer being too small, you should treat this as a serious issue to resolve by increasing the buffer space at the moment. We’ve made some effort to handle these cases to make sure that code doesn’t write past the end of buffers but, due to the fact that the GRB code is still being actively developed and algorithms/implementations are being refined, it’s not yet been possible to make this completely robust. As the code stabilizes, it will naturally become more robust.
In PxSceneDesc.h line 221…the comment documenting the usage of eEnable_PCM says “Default: false”. That’s where I was getting my info about it from.
In my crash the sim shapes were the same as above…10k boxes hitting a PxPlaneGeometry. There were no warning issued prior to the crash.
As for the GPU buffer warnings…they went away once I increased the memory buffers as suggested, but the hard crash after multiple playthroughs (ie, multiple cleanups + re-inits) did not (and it occurred without any error printouts) Is there anything else I need to do to clear out GPU memory, other than release the cuda context? I ran a GPU profiler and it reported that GPU memory was being freed after each successive playthrough…but maybe something is accidentally hanging on after cleanup still? My cleanup/init code is identical to the code found in the GRB snippets.