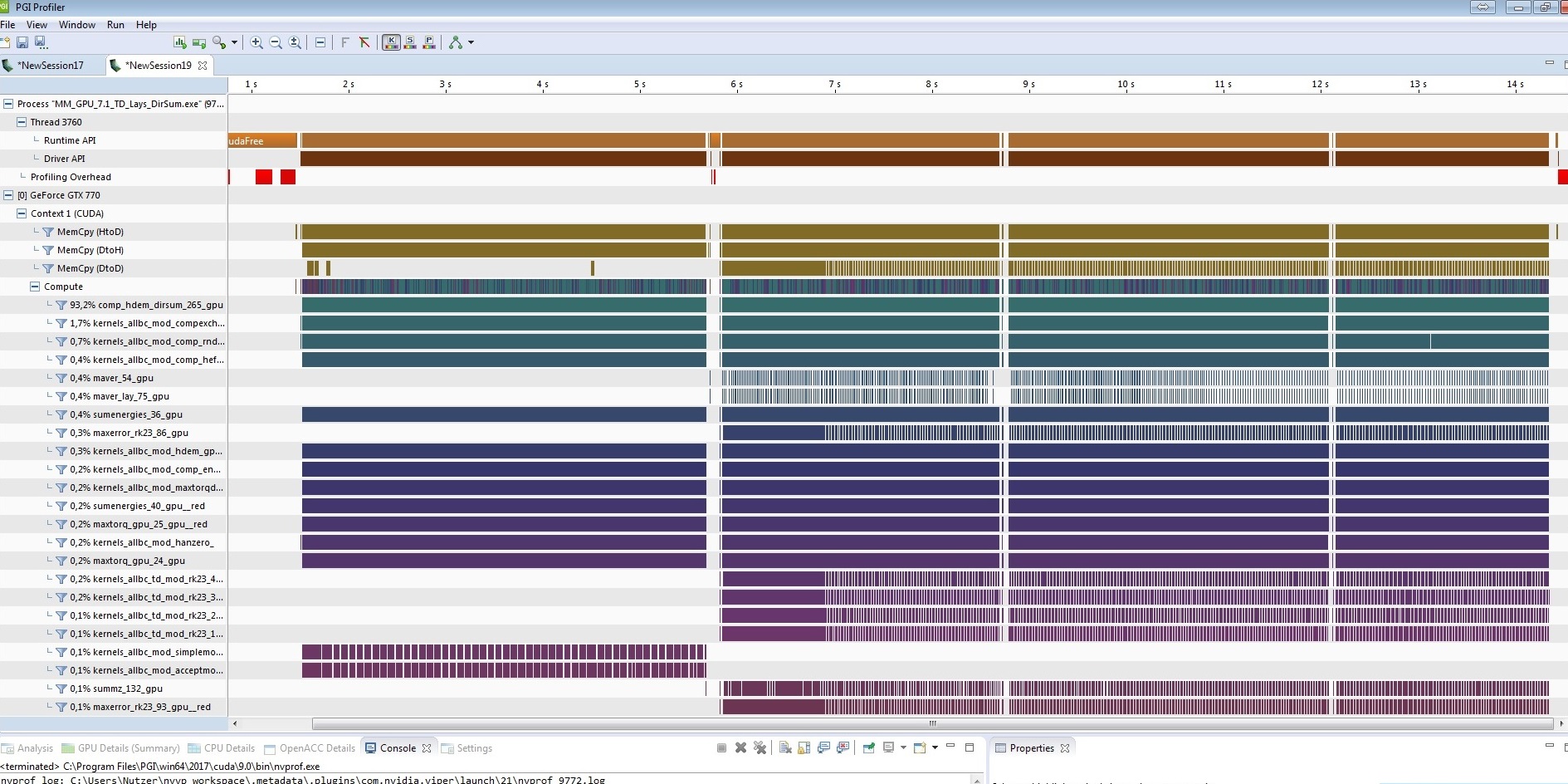
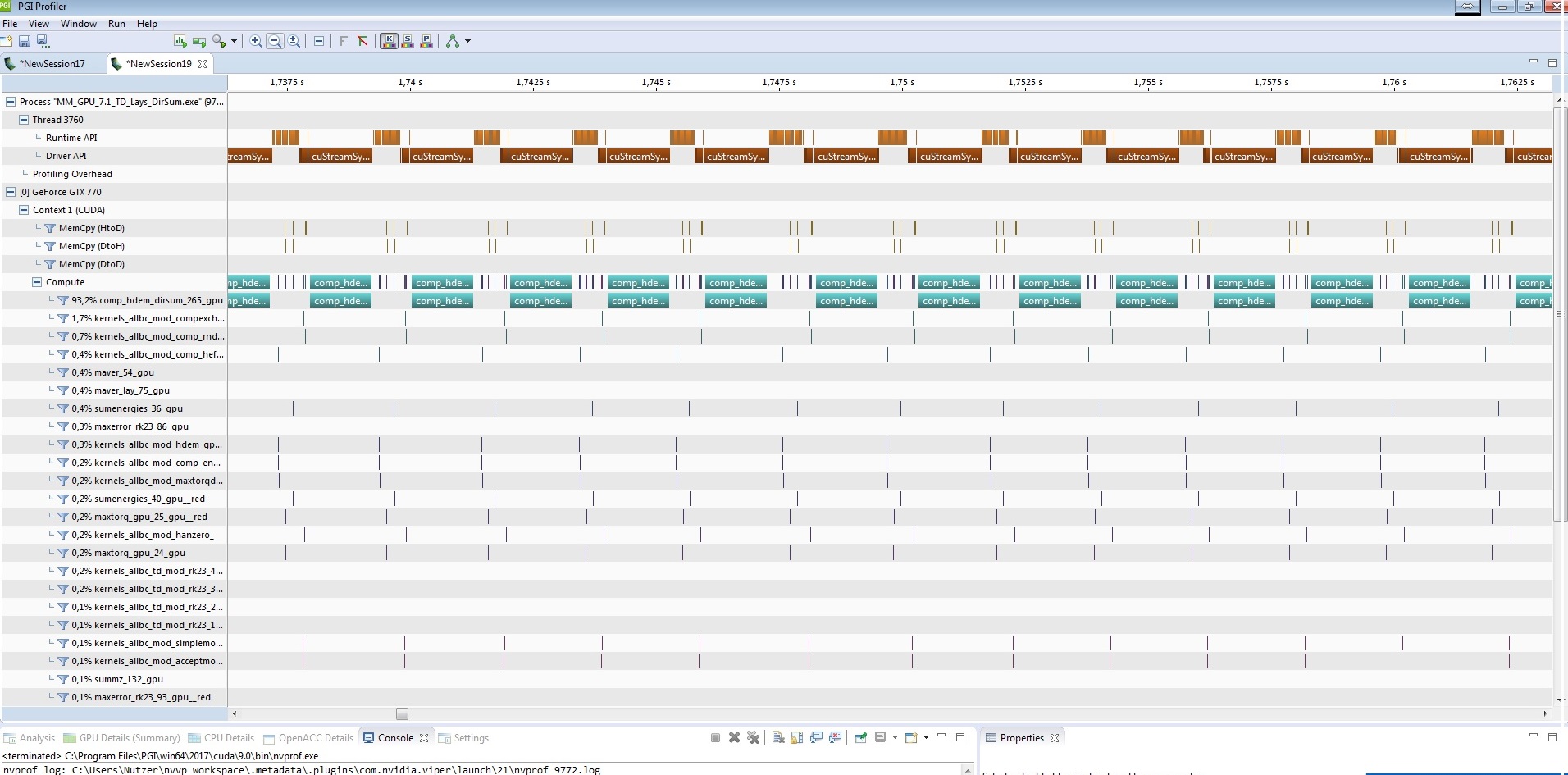
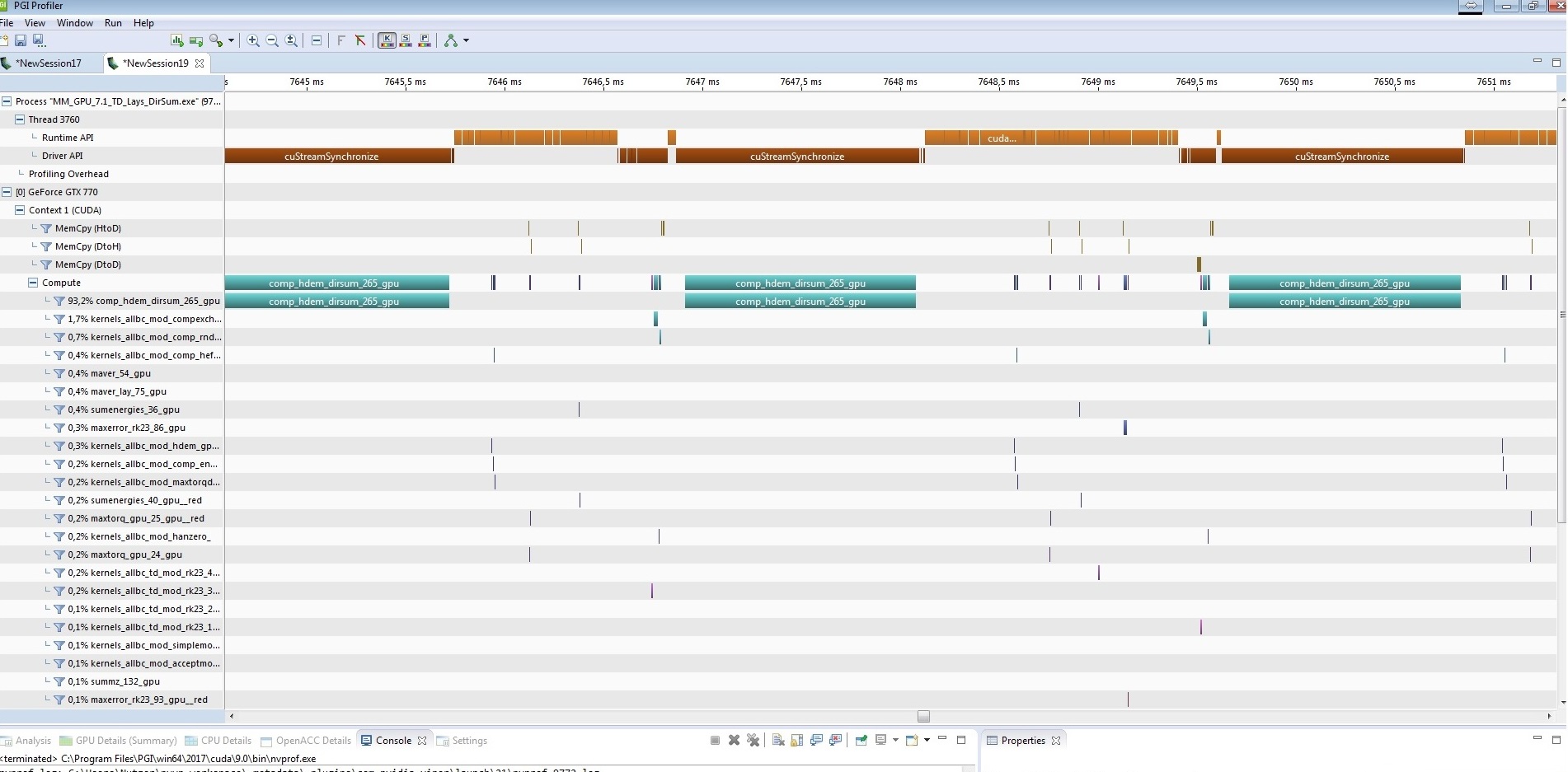
I want to port such a code with 6 nested loops from CPU to GPU:
do msc=1,Ny
do mtg=1,Ny
do jsc=1,Nz
do jtg=1,Nz
do isc=1,Nx
do itg=1,Nx
indx=abs(itg-isc)+1
indz=abs(jtg-jsc)+1
hx (itg,jtg,mtg)=hx(itg,jtg,mtg)+ prodMsV(isc,jsc,msc)/dv(msc) *
& (mx(isc,jsc,msc)*wwmx(indx,indz,msc,mtg)
& +my(isc,jsc,msc)*wwmy(indx,indz,msc,mtg)
& +mz(isc,jsc,msc)*wwmz(indx,indz,msc,mtg))
...
enddo
enddo
enddo
enddo
enddo
enddo
[b][/b]
My kernels for GPU:
attributes(global) SUBROUTINE Comp_nested_gpu
implicit none
Integer N, M, L
Integer i, j, k, bx, by, bz
Integer isc,jsc,msc,indx,indz
Real(8) MsVdv
! Get the thread indices
bx = blockidx%x
by = blockidx%y
bz = blockidx%z
j = (bx-1) * blockdim%x + threadidx%x
k = (by-1) * blockdim%y + threadidx%y
i = (bz-1) * blockdim%z + threadidx%z
N = ubound(mxDev,1)-1
M = ubound(mxDev,2)-1
L = ubound(mxDev,3)
if ((j<=N).AND. (k<=M) .AND. (i<=L)) then
call DirSum_in(j,k,i)
endif
END SUBROUTINE Comp_nested_gpu
attributes(device) SUBROUTINE DirSum_in(itg,jtg,mtg)
implicit none
Integer itg,jtg,mtg
Integer N, M, L
Integer bx, by, bz
Integer isc,jsc,msc,indx,indz
Real(8) MsVdv
! Get the thread indices
bx = blockidx%x
by = blockidx%y
bz = blockidx%z
isc = (bx-1) * blockdim%x + threadidx%x
jsc = (by-1) * blockdim%y + threadidx%y
msc = (bz-1) * blockdim%z + threadidx%z
N = ubound(mxDev,1)-1
M = ubound(mxDev,2)-1
L = ubound(mxDev,3)
if ((isc<=N).AND. (jsc<=M) .AND. (msc<=L)) then
...
MsVdv = prodMsVDev(isc,jsc,msc)/dvDev(msc)
hxdemDev(itg,jtg,mtg)=hxdemDev(itg,jtg,mtg)+MsVdv* &
(mxDev(isc,jsc,msc)*wwmxmxDev(indx,indz,msc,mtg)+ &
myDev(isc,jsc,msc)*wwmxmyDev(indx,indz,msc,mtg)+ &
mzDev(isc,jsc,msc)*wwmxmzDev(indx,indz,msc,mtg))
...
endif
END SUBROUTINE DirSum_in
The GPU code works very quickly, but return wrong result.
Should I use only one kernel for such calculations?