Please provide the following information when requesting support.
• Hardware (T4/V100/Xavier/Nano/etc)
• Network Type (Detectnet_v2/Faster_rcnn/Yolo_v4/LPRnet/Mask_rcnn/Classification/etc)
• TLT Version (Please run “tlt info --verbose” and share “docker_tag” here) 4.0.1-tf2.9.1
• Training spec file(If have, please share here)
• How to reproduce the issue ? (This is for errors. Please share the command line and the detailed log here.)
I want to run the AutoML experiments, for which I was installing the TAO REST API.
Current System: SSH into 10.103.48.174 server with Ubuntu 20.04.
Now I run bash setup.sh check-inventory.yml and it gives no output.
Finally I run bash setup.sh install
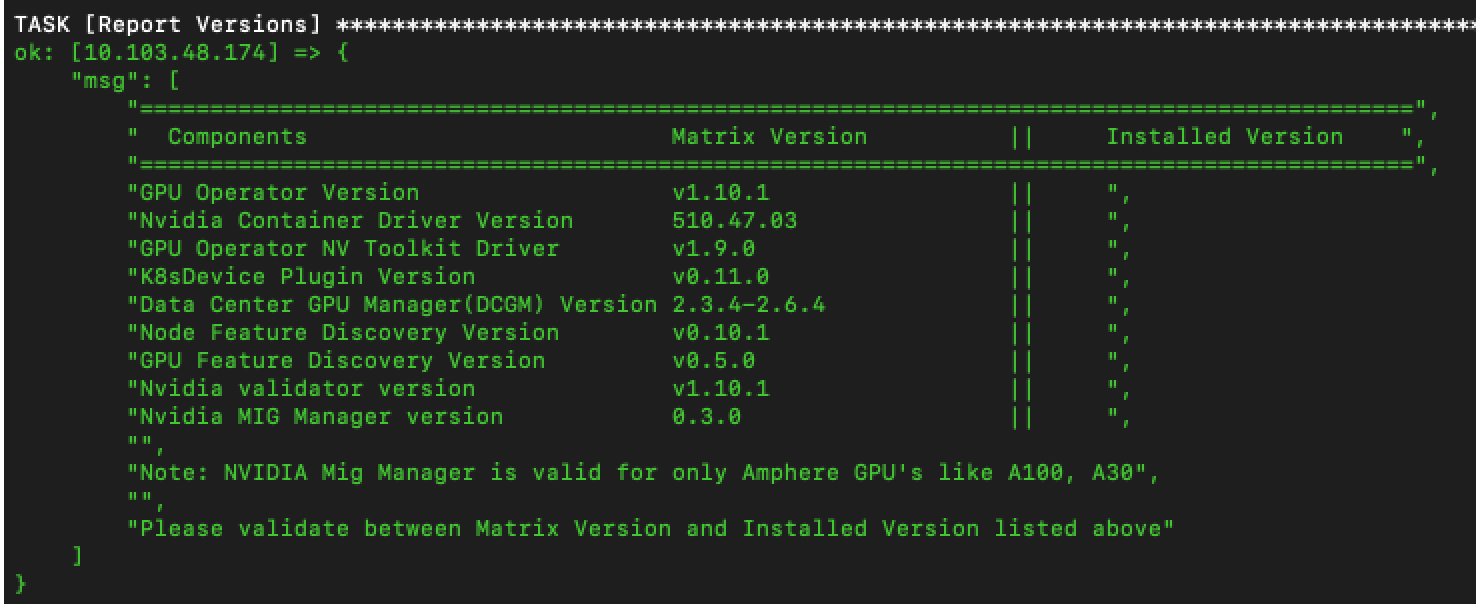
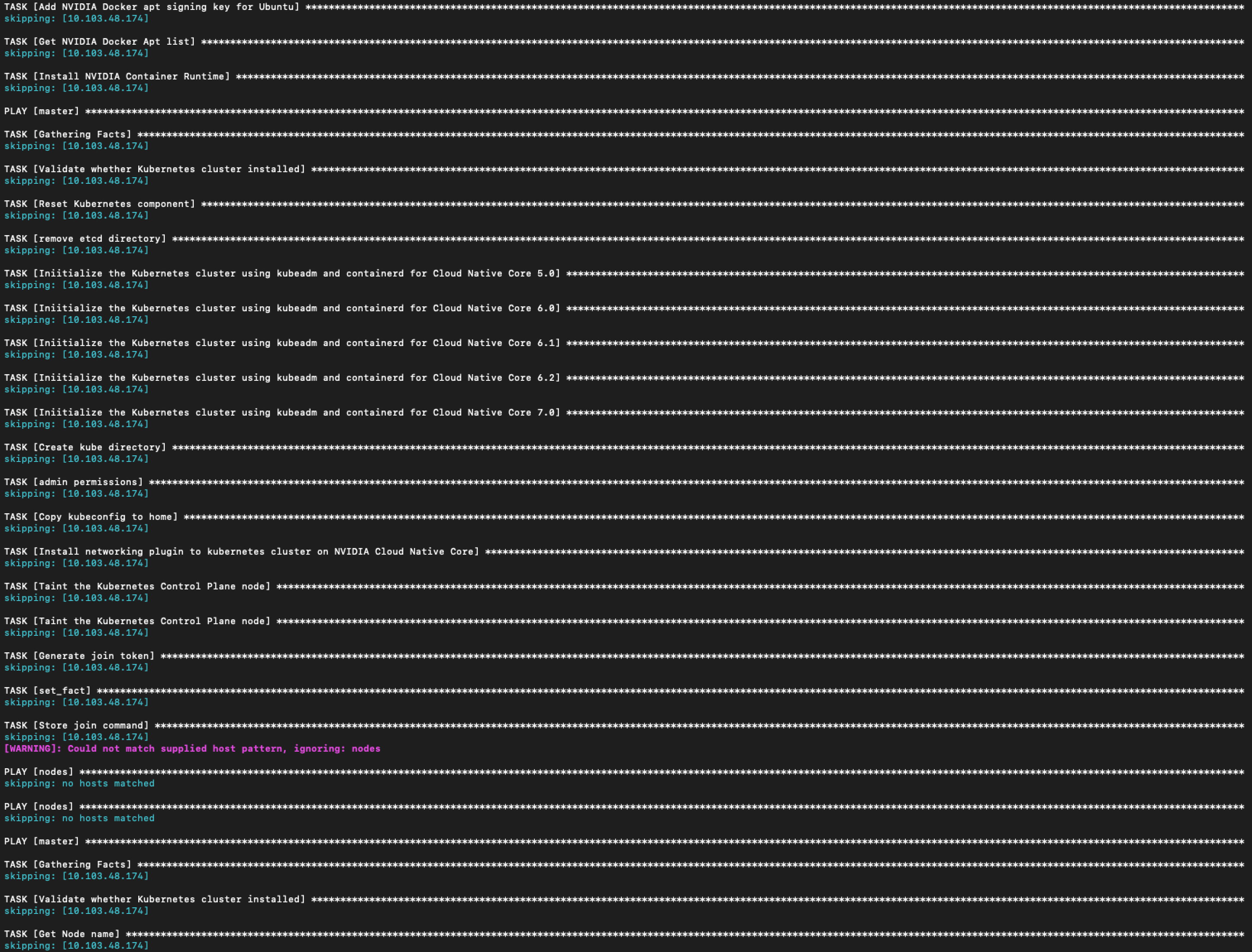
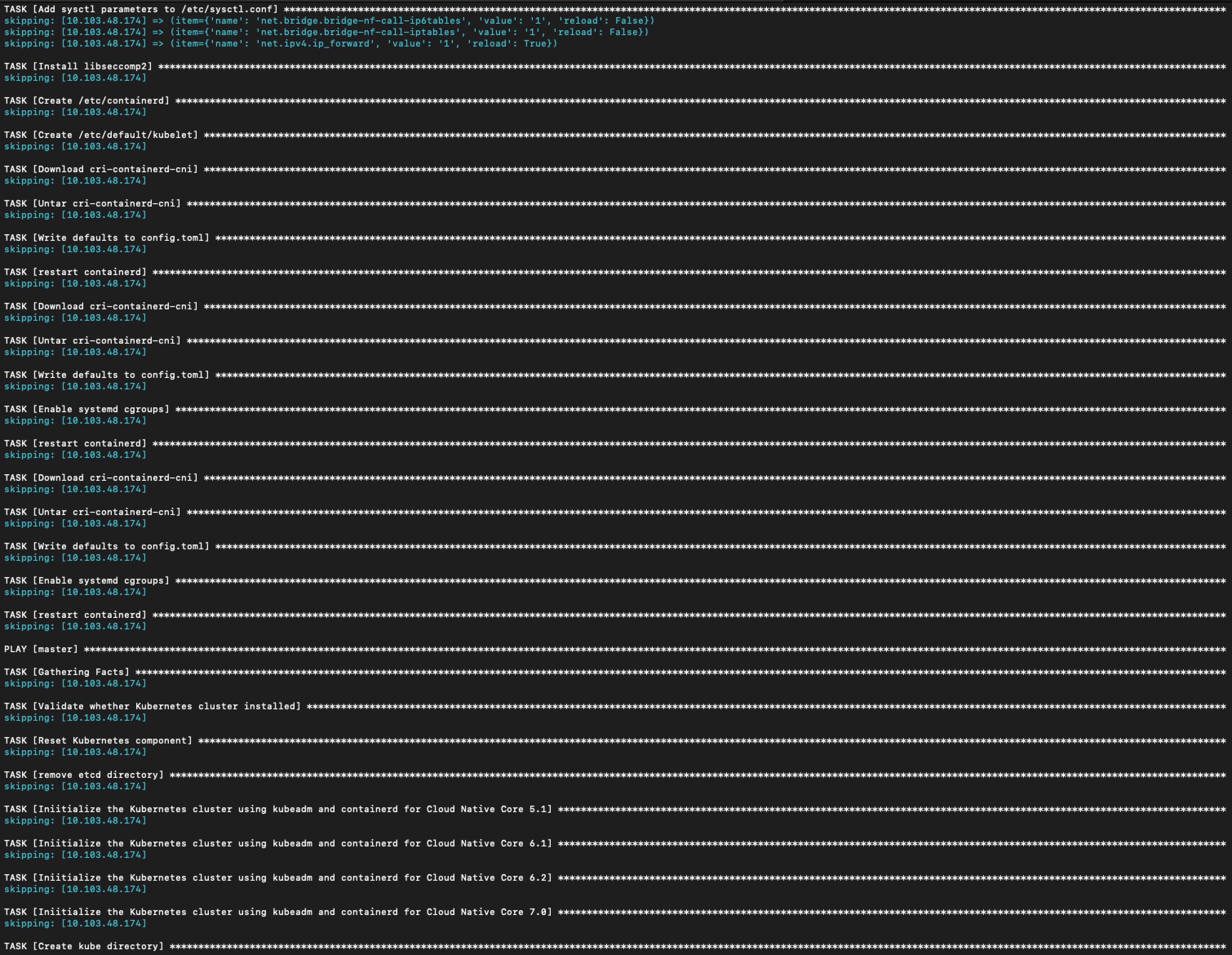
The code runs through most TASKS but skips a lot. for example -
Considering the fact that it first uninstalls all NVIDIA drivers, now I am left with no nvidia driver on my system because this install task is somehow skipped.
I have the following questions: 1. Is the way of specifying the IP address, and details in the host file correct? 2. Why is it skipping the driver installation process? 3. How do I fix the final error for the TASK [Validate GPU Operator Version for Cloud Native Core 6.1]
Just to clarify, for the IP part, I am already on 10.103.48.174, inside a conda environment, and that’s the same machine I want as master, so I have entered its IP details, that’s a plausible way of doing this right?
I did follow this as well as used v4.0.2 for everything and I get stuck at the same place as that person actually.
TASK [Waiting for the Cluster to become available] takes forever to load, I’ve waited 15 minutes, tried it twice. Rebooting the system actually did push it past that place where I was stuck, but the NVIDIA drivers installation is still being skipped and 2 validations are failing fatally.
To get the info from nvidia-smi, please run below command. $ kubectl get pods
then you can find the pod which is named nvidia-smi-xxxx, then, $ kubectl exec nvidia-smi-xxxx -- nvidia-smi
To get the info from nvidia-smi, yes, please run above command.
Usually the nvidia-smi pod’s name will not be changed. So, you just need to run $ kubectl exec nvidia-smi-xxxx -- nvidia-smi
I get it that this command works, but I would also like to access via just nvidia-smi
What should I do for that?
I ran $ bash setup.sh install is there anything else that needs to be done?