I have a project with 2 deepstream pipeline app. The first app will run on GPU 0 and the second one will run on GPU 1. My expectation is that 2 app will run separately in each GPU to have best performance for each app. However, when I see the monitor with nvtop, I see that app 1 run on both GPU 0 and GPU 1 although I set the gpu-id for nvinfer plugin when creating in the pipeline. If I disable NvInfer, 2 app will run separately with each other. I attached nvinfer config file and nvtop display image in the attachment. So my question is do I have problem with setting NvInfer or this plugin always have a part running on GPU 0 by default?
pose_engine.txt (905 Bytes)


Please provide complete information as applicable to your setup.
• Hardware Platform (Jetson / GPU)
• DeepStream Version
• JetPack Version (valid for Jetson only)
• TensorRT Version
• NVIDIA GPU Driver Version (valid for GPU only)
• Issue Type( questions, new requirements, bugs)
• How to reproduce the issue ? (This is for bugs. Including which sample app is using, the configuration files content, the command line used and other details for reproducing)
@Fiona.Chen This is the server information
• Hardware Platform: GPU
• DeepStream Version: 6.1
• TensorRT Version: v8.5
• NVIDIA GPU Driver Version: 535.183.01
• Issue Type: Questions
• How to reproduce the issue ?: Running 2 deepstream app with the same source code, enable nvinfer and set up gpu-id 0 and 1 for each of them. The problem is that the app running nvinfer in gpu 1 will use both gpu 0 and gpu 1 for processing. I just want each app will run seperately in one gpu to boost the best performance for each app.
Please help me to clarify the question. Thank you very much!
Most DeepStream modules are accelerated by GPU. Please set all GPU accelerated modules’ “gpu-id”.
It is better to upgrade to the latest DeepStream version.
@Fiona.Chen I alreadly set up gpu-id for each app with 0, 1 respectively. I also used NVIDIA_VISIBLE_DEVICES before running the app, the issue is the same. When I disable nvinfer and just run previous components in the pipiline, the issue is disappeared. So I think there is one part of nvinfer using GPU 0 by default, is it right?
You just post the configuration of gst-nvinfer. What is your setting in your app?
If you use NVIDIA_VISIBLE_DEVICES, you don’t need to set “gpu-id” value in the app or gst-nvinfer configuration.
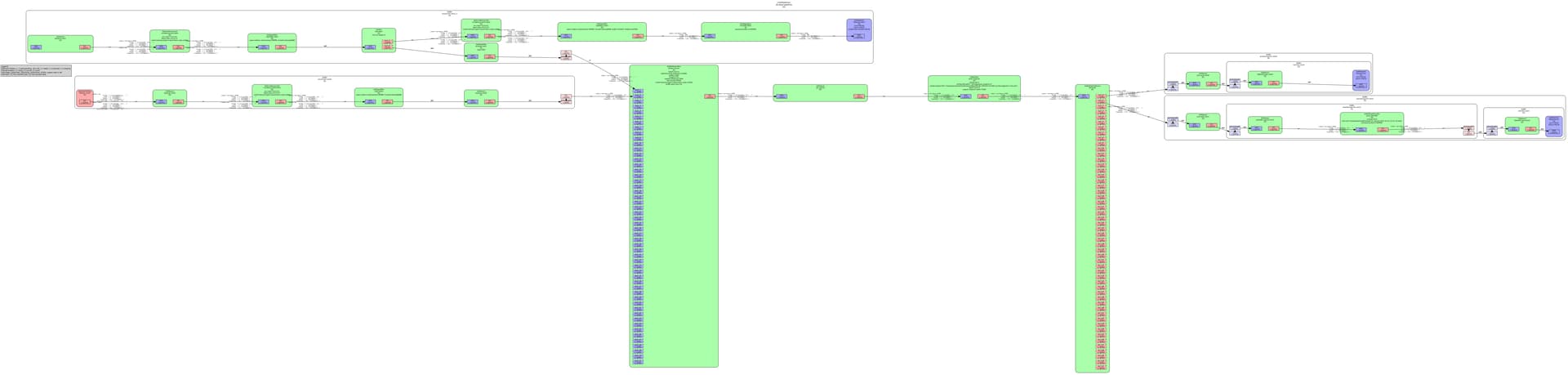
This is our pipeline. For other component, I also set gpu-id for each of them. I think the problem comes from nvinfer because If I disable nvinfer, I see 2 deepstream app run in 2 separated gpu 0 and 1 respectively.
I found the problem coming from the function gst_nvdspreprocess_output_loop of nvdspreprocess plugin. I need to set the cuda device for this thread and the problem disappeared but I still wonder how it afftect to system performance?By the way, I also have other question about how to calculate maximum number of cameras that the pipeline can run in parallel and how to configure pipeline to get max performance?. For the case I use nvpreprocess for 20 cameras with 3 rois, what is the most suitable batch-size to set for streammux and nvinfer to get max performance?
What do you mean by “afftect to system performance”?
The pipeline performance will be impacted by all the components inside it. Since all components work in asynchronous mode, the performance may be decided by the slowest components. In some cases, the pipeline works with clock, then the clock may impact the performance too. So it should be case by case.
The picture is too small to be clear.
There is no update from you for a period, assuming this is not an issue anymore. Hence we are closing this topic. If need further support, please open a new one. Thanks
This topic was automatically closed 14 days after the last reply. New replies are no longer allowed.