Hi guys,
I’m testing the performance number on Orin with MAXN mode. The pure conv2d model got result as below:
a. Run GPU only: 405.3 qps.
b. Run DLA only: 132.7 qps
c. Run GPU + DLA x2: GPU 229.2 qps +DLS 113.1 qps * 2 = 455.4 qps in total
It seems that the GPU turns slow if we use GPU and DLA together. Checked some related issue on Xavier topic but I am not sure if they are caused by the same reason.
The network simple structure is as follow picture:

The commands are as follows:
/usr/src/tensorrt/bin/trtexec --onnx=conv2d.onnx --avgRuns=200 --int8 --iterations=10000 --useSpinWait
/usr/src/tensorrt/bin/trtexec --onnx=conv2d.onnx --avgRuns=200 --int8 --iterations=10000 --useSpinWait --useDLACore=0 (or 1) --allowGPUFallback( tried both with allow Fallback or not allow Fallback, seems the same)
When there is only one DLA running, the Jetson Power GUI shows that the GPU loading is arround 30%. So I use the Nsight to get the profile of this model. The following picture is running one DLA only:

Question#1. There is a D2H and a H2D for each loop, is this memcpy plus the permutation block in #2 the reason why the GPU is occupied by 30% when there is DLA only, as I assume there should be no fall-back layer?
Question#2. There is two block “void …” in blue on stream 18, actually, it’s a permutationKernelPLC3. Why there is such a block on GPU while running a network on DLA? What does this block do? Why there are two permutation blocks consecutively?
Question#3 What’s “Task 6.934ms” in DLA0, is it the wall time the DLA hardware use? Why there is about 0.5ms idle time between each Task? Is DLA waiting for the GPU permutationKernelPLC3?
Then I compare the difference between GPU_only profile and GPU+2xDLA profile, for GPU only:
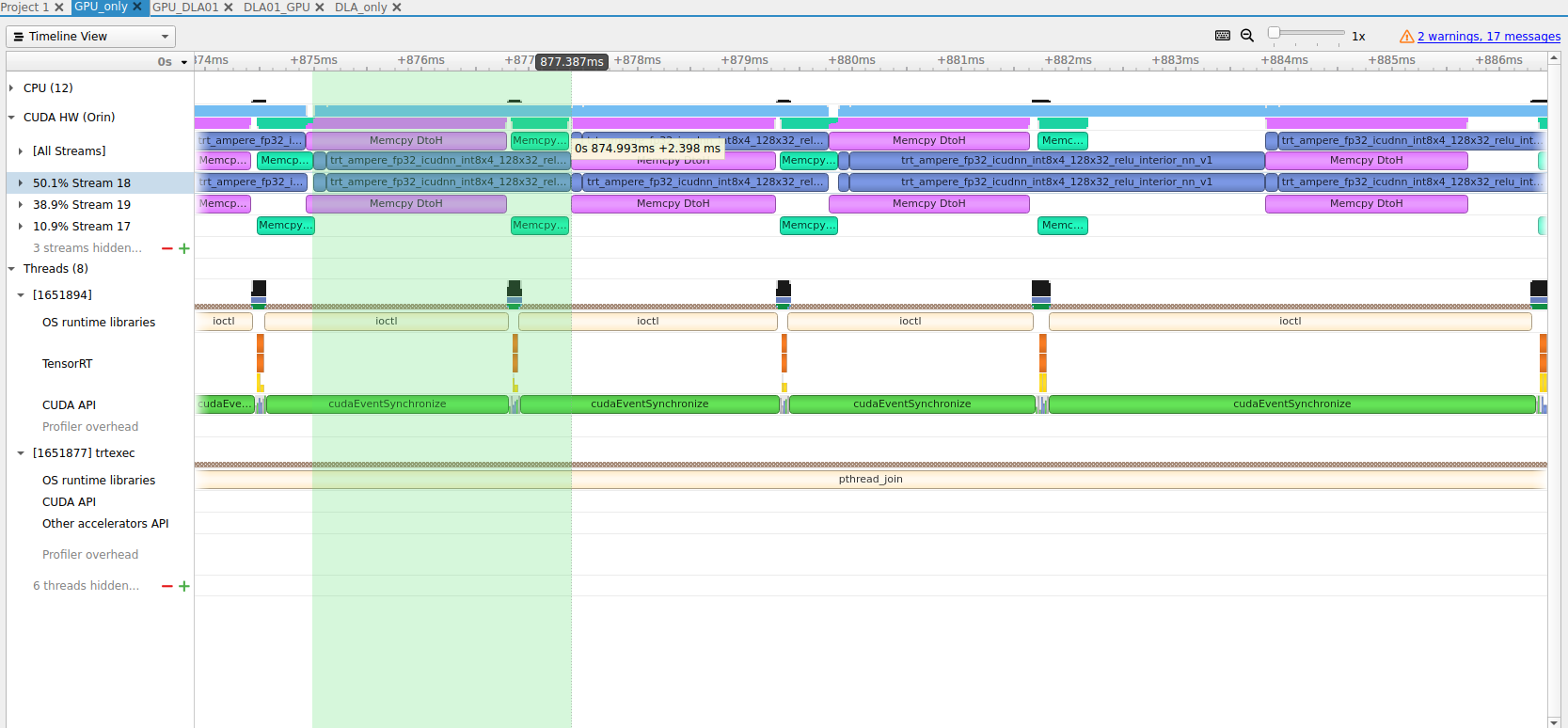
and GPU+2xDLA:

Question#4 In GPU+2xDLA, the time for “trt_ampere_fp32_icudnn_int8x4…” in blue gets unstable. It could be prolonged to 4.383ms as highlighted in the GPU+2xDLA and then it’s arround 2.4ms (while in GPU only mode the time is normally arround 2.4ms as highlighted). This phenomenon happens every 2 loop. So, why does the GPU calculation turns slow? Is it influenced by the permutationKernelPLC3 in DLA process? But this permutationKernelPLC3 seems to be very short (less than 0.6ms, for 2xDLA, I assumed it could be 1.2ms, still 1.2 + 2.4 < 4.383).
Question#5 In GPU+2xDLA, for stream 18 which seems to be the calculation stream? There is a signaficant idle time between each 2 loop (about 2.28ms between every 2 blue trt_ampere block). Why is this idle time exist, while in GPU only mode the idle time is very short (about 0.05ms)?
Question#6 The DLA “Task” time is 6.934ms in DLA only mode, but in GPU+2xDLA, the DLA time prolonged to arround 7.2ms. If DLA hardware runs independantly after the data is copied to DLA related memory, why does this time becomes longer in GPU+2xDLA mode?
Should you require any further information, please do not hesitate to let me know.
I look forward to your reply.
Thanks.

