Please provide the following info (tick the boxes after creating this topic): Software Version
[o] DRIVE OS 6.0.5
DRIVE OS 6.0.4 (rev. 1)
DRIVE OS 6.0.4 SDK
other
Target Operating System
[o] Linux
QNX
other
Hardware Platform
DRIVE AGX Orin Developer Kit (940-63710-0010-D00)
DRIVE AGX Orin Developer Kit (940-63710-0010-C00)
DRIVE AGX Orin Developer Kit (not sure its number)
[o] other : 940-63710-0010-300
SDK Manager Version
[o] 1.9.1.10844
other
Host Machine Version
native Ubuntu Linux 20.04 Host installed with SDK Manager
native Ubuntu Linux 20.04 Host installed with DRIVE OS Docker Containers
[o] native Ubuntu Linux 18.04 Host installed with DRIVE OS Docker Containers
other
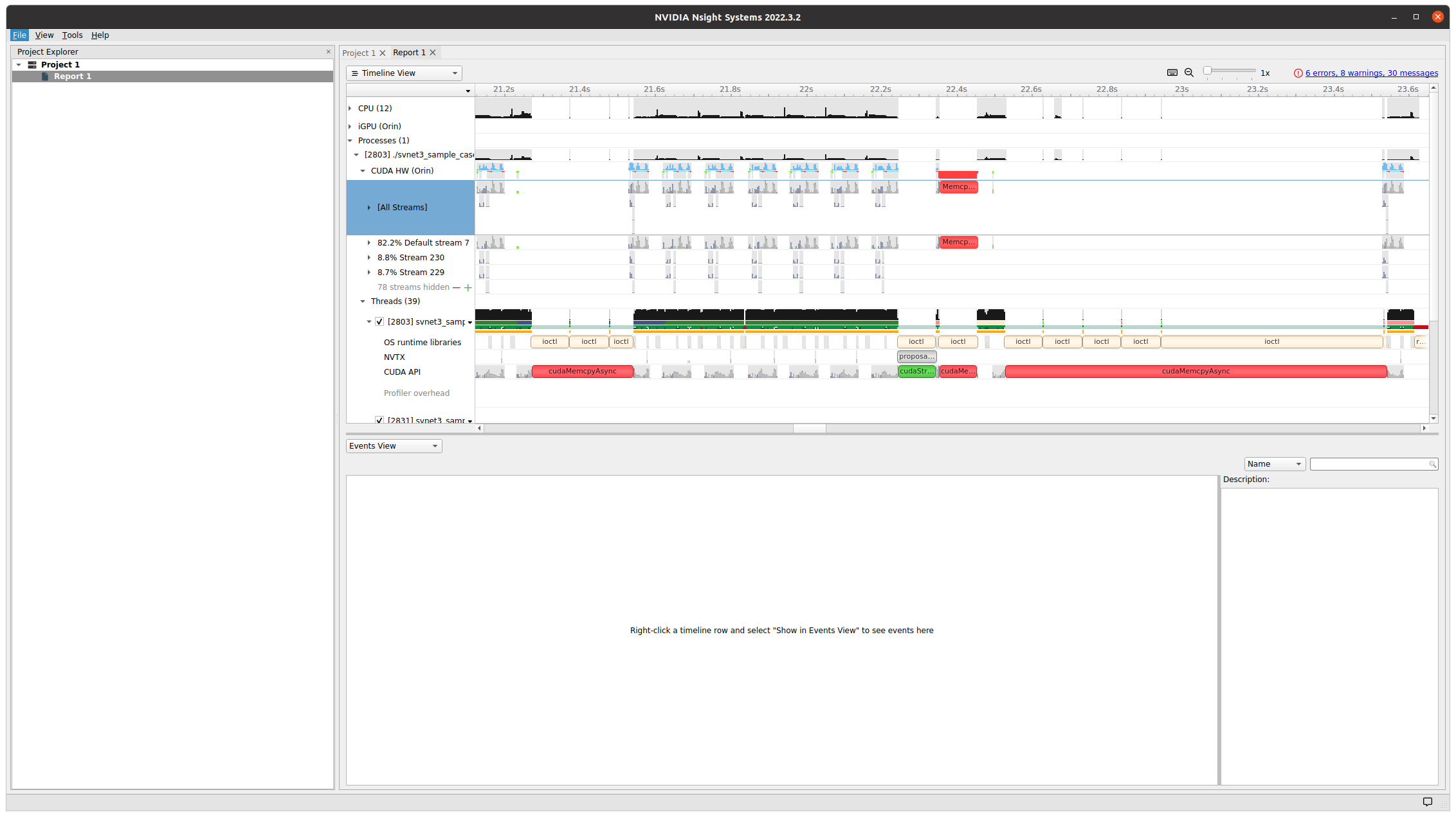
Hello, I’m trying to run our inference software in Drive AGX Orin newly.
But I met unaccountable problem that our S/W sometimes paused in idle status.
I found this problem is caused by cudaMemcpyAsync() function that makes blocking status after function call.
I checked it with nsight tool and I attached captured image.
Dear @cheolwoong.eom,
What is the size for those memcpy calls ? Is it h2d, d2h or d2d direction? Also, is this time indiate CUDA API launch overhead or memory copy time?
I just tested my S/W again, It takes 975 msec for 2048 bytes D2H cudaMemcpy.
But I believe it is not related with copy size and all issue operations are D2H.
I think this time is caused by memory copy, but I’m sure. I just found this issue at outside of given CUDA API functions.
When I replaced cudaMemcpyAsync() to cudaMemcpy(), I got the same result.
ioctl() calls have any relevant to cudaMemcpy() ? In timeline these functions are state in same place.
Dear @cheolwoong.eom,
We will look into the report. Just want to confirm if the cudamemcpyAsync is using pinned memory buffers?
Also share the Nsight Systems version used to create the report?
Dear @cheolwoong.eom,
It is strange, I could not load your report on my nsys 2022.3.2.
We don’t use pinned memory, just make buffer using “new” operation.
Is cudaMemcpyAsync() is used to overlap data transfer with computation? Also, Is it possible to move the memory allocations to initialization module so that during execution of application, it does not cause any latencies like these.
We are using cudaMemcpyAsync() for post-processing in CPU computation after ML processing in GPU.
Because buffer size is not always same, our software often re-allocate memory before cudaMemcpyAsync().
We have no plan to re-architect our software right now.
I already tested same code in other nVidia development kit like Jetson AGX Orin, Dirve AGX Pagasus, etc… And I’ve never experienced a problem like this.
Dear @cheolwoong.eom,
I could open the report. Could you confirm if the cudaMemcpyAsync() calls launched in default stream in code? Did you set cudaDeviceScheduleBlockingSync flag in code?