Please provide the following information when creating a topic:
Hardware Platform (GPU model and numbers) : brev.dev launchable on CRUSOE
System Memory : 128GB ( unconfirmed )
Ubuntu Version : unknown
NVIDIA GPU Driver Version (valid for GPU only) : unknown
Issue Type : Question
While testing out the summerization api, it does not seem to follow completely the documentation provided. I believe some api params are not expected by the api.
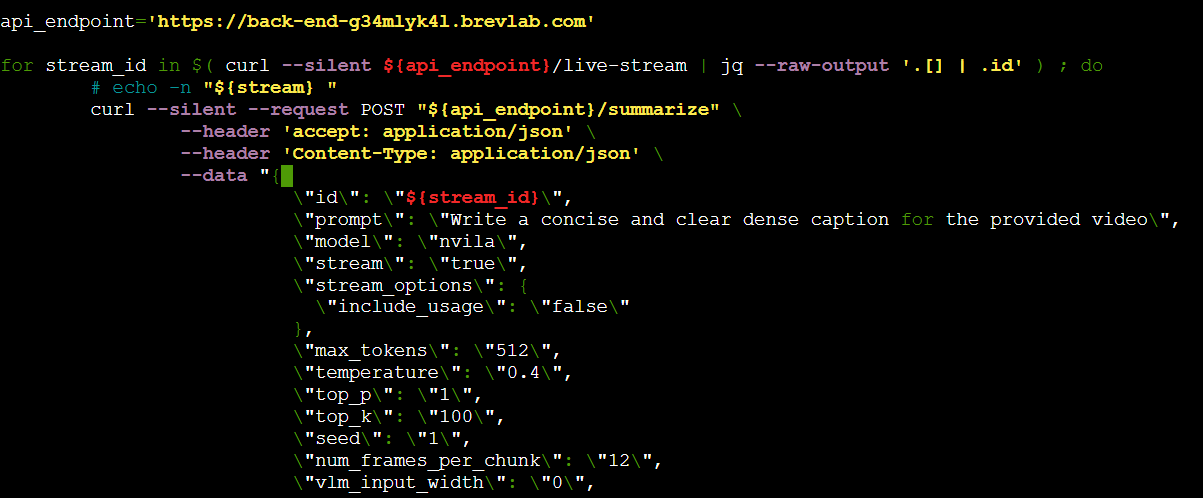
The following is the params provided in the API documentation,
I believe it was failing because of the values in rag_type, rag_batch_size, etc.
This is what worked for us,
{
“id”: “5e223c04-c32d-4cfb-a6be-227ec5aa5f98”,
“prompt”: “Write a concise and clear dense caption for the provided video”,
“model”: “nvila”,
“stream”: true,
“stream_options”: {
“include_usage”: true
},
“max_tokens”: 512,
“temperature”: 0.4,
“top_p”: 1,
“top_k”: 100,
“seed”: 1,
“num_frames_per_chunk”: 10,
“vlm_input_width”: 0,
“vlm_input_height”: 0,
“chunk_duration”: 60,
“summary_duration”: 60,
“caption_summarization_prompt”: “Prompt for caption summarization”,
“summarize”: true,
“enable_chat”: false
}
Verified with the code from the via-engine container>
After initiating the summarization for live stream via API, its response is a stream.
Is there a way to just trigger the summarization for live stream without the response as a stream. We could use the chat completion API to query the vector database for the summaries.
There is a limit of 256 live stream summarization currently possible. How can I increase this limit?
We were able to successfully add 500 streams, but only 256 streams were able to be actively summarized by the earlier code. We looked into gradio UI to verify the active streams, and it only showed 256 active streams eventhough there were 500 streams going through the vss engine, which we confirmed with the tmp/assets folder (it had 500 uniques). The summarization performance started droping after 256 active streams too. But gradio ui kept showing only 256 active streams when we refresh active stream list. It failed to summarize for the rest of the 500 streams we added.
We later on, went through the vlm_pipeline.py file, and found this code, and it gave us the impression, there is a default limit set.
There is no update from you for a period, assuming this is not an issue anymore. Hence we are closing this topic. If need further support, please open a new one. Thanks