I am having an error in TLT 3.0 in mounting to docker. I hope you can help me on this manner.
I changed the tlt_mounts.json. I checked if the path exists using echo:
! echo $SPECS_DIR/detectnet_v2_tfrecords_kitti_trainval.txt
! echo $DATA_DOWNLOAD_DIR
! echo $SPECS_DIR
However it is still not working

All the env after tlt detectnet_v2 evaluate should the env inside the docker.
You can you login the docker to check if the path or env is correct.
docker run --runtime=nvidia -it -v
<yourfolder>:/workspace/tlt-experiments nvcr.io/nvidia/tlt-streamanalytics:v3.0-dp-py3 /bin/bash
ls $SPECS_DIR/detectnet_v2_tfrecords_kitti_trainval.txt
1 Like
Yes I fixed this. However, I am still having errors since when I list the available pretrained facenet model. It shows an empty list. So maybe, that’s where the error is coming from.

I tried to install it manually from the ngc models. I put it in the right file and changed the model_config path. However, it is still not detecting it
I downloaded the model directly from ngc the face detect model with IR.
However, it shows the following error.

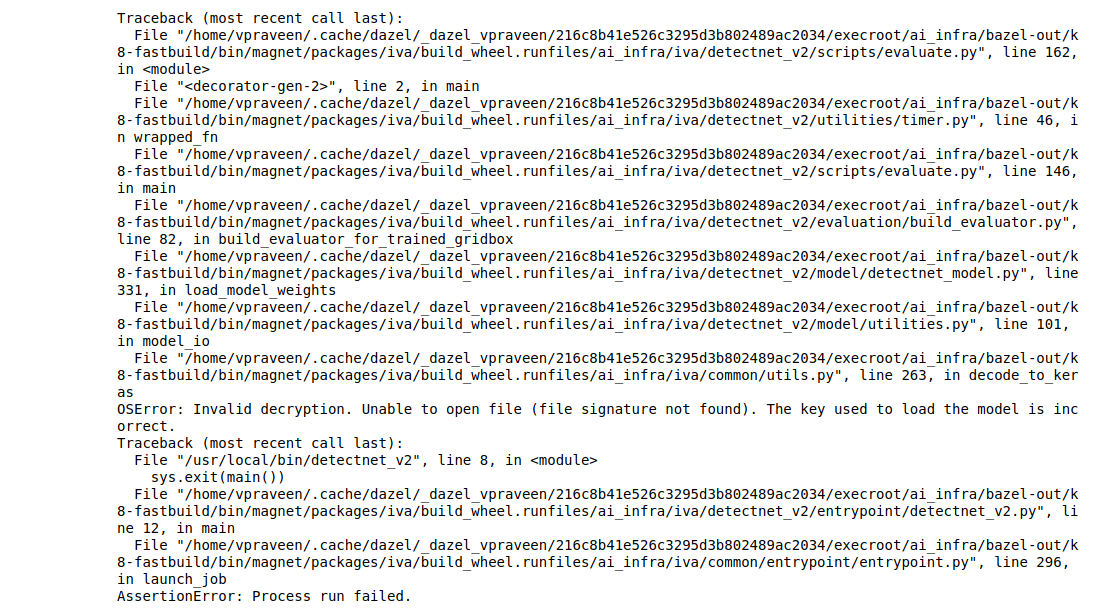
Can you download the face detect IR model from its model card https://ngc.nvidia.com/catalog/models/nvidia:tlt_facedetectir/files ?
And its key is tlt_encode
See
The
unprunedandprunedmodels are encrypted and will only operate with the following key:
- Model load key:
tlt_encodePlease make sure to use this as the key for all TLT commands that require a model load key.
More info is in FaceDetect-IR — Transfer Learning Toolkit 3.0 documentation

Can you share your training spec file?


You want to train a 736x416 detectnet_v3 model.
According to Transfer Learning Toolkit — Transfer Learning Toolkit 3.0 documentation
Please check if your images/labels are resized to 736x416 offline.
Reference: Tensor reshape error when evaluating a Detectnet_v2 model

Since you set the facedetectIR tlt model as the pretrained model, please resize your images/labels to 384x240 offline.
And set 380x240 in your training spec file.
https://ngc.nvidia.com/catalog/models/nvidia:tlt_facedetectir
Input
Gray Image whose values in RGB channels are the same. 384 X 240 X 3 (W x H x C) Channel Ordering of the Input: NCHW, where N = Batch Size, C = number of channels (3), H = Height of images (240), W = Width of the images (384)
Thank you Morganh for your support.
Concerning the load_key. I set it to tlt_encode. However I am still having issues even though I used the facedetect model not the IR.


What do you mean by “I used the facedetect model not the IR” ?
I am working on the facenet model (face detect) provided by the transfer learning toolkit.
For the pretrained model, there are 2 version either with IR or without from ngc.
So using the pretrained model without IR give me the OSError: Unable to open file. And using the pretrained model with IR give me the dimensions error. I will resize the images as you said. I will resize them offline 384x240 images and see if it will work.
However meanwhile, I am trying with the pretrained model without IR.
For https://ngc.nvidia.com/catalog/models/nvidia:tlt_facenet, according to its overview,
its key is
nvidia_tltInput
Grayscale Image whose values in RGB channels are the same. 736 X 416 X 3
For https://ngc.nvidia.com/catalog/models/nvidia:tlt_facedetectir, according to its overview,
its key is
tlt_encodeInput
Gray Image whose values in RGB channels are the same. 384 X 240 X 3 (W x H x C) Channel Ordering of the Input: NCHW, where N = Batch Size, C = number of channels (3), H = Height of images (240), W = Width of the images (384)
1 Like
Ok thank you for your reply.
I just want to make sure if the dataset of the face detect is the same as the face detect with IR but resized.
Thank you so much !
It shouldn’t be since the label is different.
“This model accepts 384x240x3 dimension input tensors and outputs 24x15x4 bbox coordinate tensor and 24x15x1 class confidence tensor.”
Any remaining issue?


