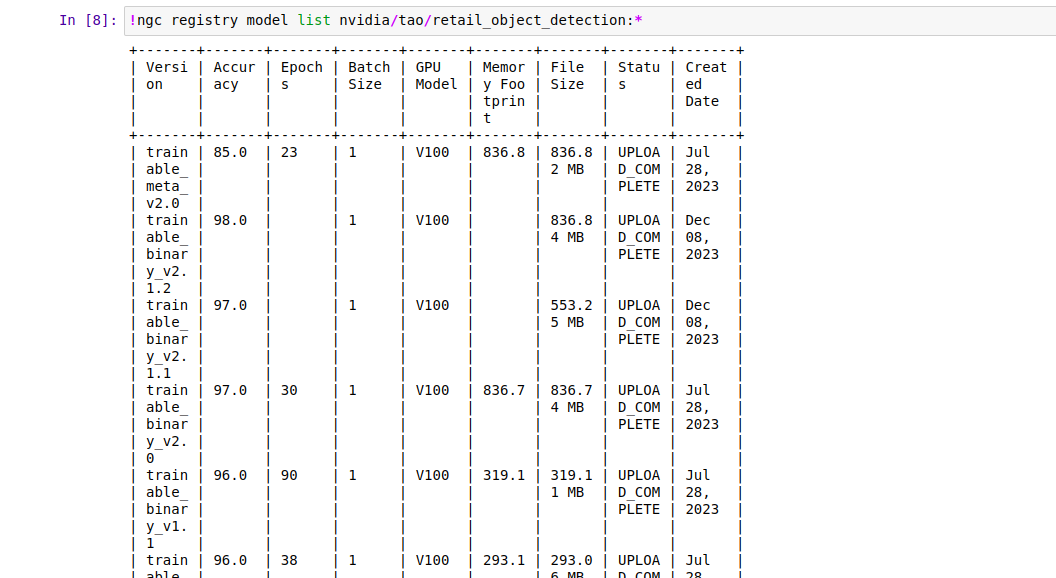
I’m currently getting this error
/usr/local/lib/python3.10/dist-packages/pytorch_lightning/callbacks/model_checkpoint.py:604: UserWarning: Checkpoint directory /home/doruk/doruk/getting_started_v5.3.0/notebooks/tao_launcher_starter_kit/retail_object_detection/retail_object_detection/results/train exists and is not empty.
rank_zero_warn(f"Checkpoint directory {dirpath} exists and is not empty.")
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
----------------------------------------------------
0 | model | DINOModel | 48.3 M
1 | matcher | HungarianMatcher | 0
2 | criterion | SetCriterion | 0
3 | box_processors | PostProcess | 0
----------------------------------------------------
12.2 M Trainable params
36.1 M Non-trainable params
48.3 M Total params
193.014 Total estimated model params size (MB)
Sanity Checking DataLoader 0: 0%| | 0/2 [00:00<?, ?it/s]/usr/local/lib/python3.10/dist-packages/torch/utils/checkpoint.py:459: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
/usr/local/lib/python3.10/dist-packages/torch/utils/checkpoint.py:91: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
/usr/local/lib/python3.10/dist-packages/torch/functional.py:507: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at /opt/pytorch/pytorch/aten/src/ATen/native/TensorShape.cpp:3549.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
Error executing job with overrides: ['results_dir=/home/doruk/doruk/getting_started_v5.3.0/notebooks/tao_launcher_starter_kit/retail_object_detection/retail_object_detection/results/']
Traceback (most recent call last):
File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/trainer/call.py", line 38, in _call_and_handle_interrupt
return trainer_fn(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/trainer/trainer.py", line 645, in _fit_impl
self._run(model, ckpt_path=self.ckpt_path)
File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/trainer/trainer.py", line 1098, in _run
results = self._run_stage()
File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/trainer/trainer.py", line 1177, in _run_stage
self._run_train()
File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/trainer/trainer.py", line 1190, in _run_train
self._run_sanity_check()
File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/trainer/trainer.py", line 1262, in _run_sanity_check
val_loop.run()
File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/loops/loop.py", line 199, in run
self.advance(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/loops/dataloader/evaluation_loop.py", line 152, in advance
dl_outputs = self.epoch_loop.run(self._data_fetcher, dl_max_batches, kwargs)
File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/loops/loop.py", line 199, in run
self.advance(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/loops/epoch/evaluation_epoch_loop.py", line 137, in advance
output = self._evaluation_step(**kwargs)
File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/loops/epoch/evaluation_epoch_loop.py", line 234, in _evaluation_step
output = self.trainer._call_strategy_hook(hook_name, *kwargs.values())
File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/trainer/trainer.py", line 1480, in _call_strategy_hook
output = fn(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/strategies/strategy.py", line 390, in validation_step
return self.model.validation_step(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/nvidia_tao_pytorch/cv/dino/model/pl_dino_model.py", line 256, in validation_step
loss_dict = self.criterion(outputs, targets)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1510, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1519, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/nvidia_tao_pytorch/cv/dino/model/criterion.py", line 173, in forward
indices = self.matcher(outputs_without_aux, targets)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1510, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1519, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/nvidia_tao_pytorch/cv/dino/model/matcher.py", line 86, in forward
cost_bbox = torch.cdist(out_bbox, tgt_bbox, p=1)
File "/usr/local/lib/python3.10/dist-packages/torch/functional.py", line 1330, in cdist
return _VF.cdist(x1, x2, p, None) # type: ignore[attr-defined]
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.10/dist-packages/nvidia_tao_pytorch/cv/dino/scripts/train.py", line 222, in main
raise e
File "/usr/local/lib/python3.10/dist-packages/nvidia_tao_pytorch/cv/dino/scripts/train.py", line 204, in main
run_experiment(experiment_config=cfg,
File "/usr/local/lib/python3.10/dist-packages/nvidia_tao_pytorch/cv/dino/scripts/train.py", line 188, in run_experiment
trainer.fit(pt_model, dm, ckpt_path=resume_ckpt or None)
File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/trainer/trainer.py", line 603, in fit
call._call_and_handle_interrupt(
File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/trainer/call.py", line 63, in _call_and_handle_interrupt
trainer._teardown()
File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/trainer/trainer.py", line 1161, in _teardown
self.strategy.teardown()
File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/strategies/strategy.py", line 496, in teardown
self.lightning_module.cpu()
File "/usr/local/lib/python3.10/dist-packages/lightning_lite/utilities/device_dtype_mixin.py", line 78, in cpu
return super().cpu()
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 959, in cpu
return self._apply(lambda t: t.cpu())
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 801, in _apply
module._apply(fn)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 801, in _apply
module._apply(fn)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 801, in _apply
module._apply(fn)
[Previous line repeated 5 more times]
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 824, in _apply
param_applied = fn(param)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 959, in <lambda>
return self._apply(lambda t: t.cpu())
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
Set the environment variable HYDRA_FULL_ERROR=1 for a complete stack trace.
/opt/pytorch/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [6,0,0], thread: [33,0,0] Assertion `-sizes[i] <= index && index < sizes[i] && "index out of bounds"` failed.
/opt/pytorch/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [6,0,0], thread: [37,0,0] Assertion `-sizes[i] <= index && index < sizes[i] && "index out of bounds"` failed.
/opt/pytorch/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [6,0,0], thread: [41,0,0] Assertion `-sizes[i] <= index && index < sizes[i] && "index out of bounds"` failed.
/opt/pytorch/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [6,0,0], thread: [45,0,0] Assertion `-sizes[i] <= index && index < sizes[i] && "index out of bounds"` failed.
/opt/pytorch/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [6,0,0], thread: [49,0,0] Assertion `-sizes[i] <= index && index < sizes[i] && "index out of bounds"` failed.
/opt/pytorch/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [6,0,0], thread: [53,0,0] Assertion `-sizes[i] <= index && index < sizes[i] && "index out of bounds"` failed.
/opt/pytorch/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [6,0,0], thread: [57,0,0] Assertion `-sizes[i] <= index && index < sizes[i] && "index out of bounds"` failed.
/opt/pytorch/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [6,0,0], thread: [61,0,0] Assertion `-sizes[i] <= index && index < sizes[i] && "index out of bounds"` failed.
/opt/pytorch/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [8,0,0], thread: [65,0,0] Assertion `-sizes[i] <= index && index < sizes[i] && "index out of bounds"` failed.
/opt/pytorch/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [8,0,0], thread: [69,0,0] Assertion `-sizes[i] <= index && index < sizes[i] && "index out of bounds"` failed.
/opt/pytorch/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [8,0,0], thread: [73,0,0] Assertion `-sizes[i] <= index && index < sizes[i] && "index out of bounds"` failed.
/opt/pytorch/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [8,0,0], thread: [77,0,0] Assertion `-sizes[i] <= index && index < sizes[i] && "index out of bounds"` failed.
/opt/pytorch/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [8,0,0], thread: [81,0,0] Assertion `-sizes[i] <= index && index < sizes[i] && "index out of bounds"` failed.
/opt/pytorch/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [8,0,0], thread: [85,0,0] Assertion `-sizes[i] <= index && index < sizes[i] && "index out of bounds"` failed.
/opt/pytorch/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [8,0,0], thread: [89,0,0] Assertion `-sizes[i] <= index && index < sizes[i] && "index out of bounds"` failed.
/opt/pytorch/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [8,0,0], thread: [93,0,0] Assertion `-sizes[i] <= index && index < sizes[i] && "index out of bounds"` failed.
/opt/pytorch/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [5,0,0], thread: [97,0,0] Assertion `-sizes[i] <= index && index < sizes[i] && "index out of bounds"` failed.
The error continues like this