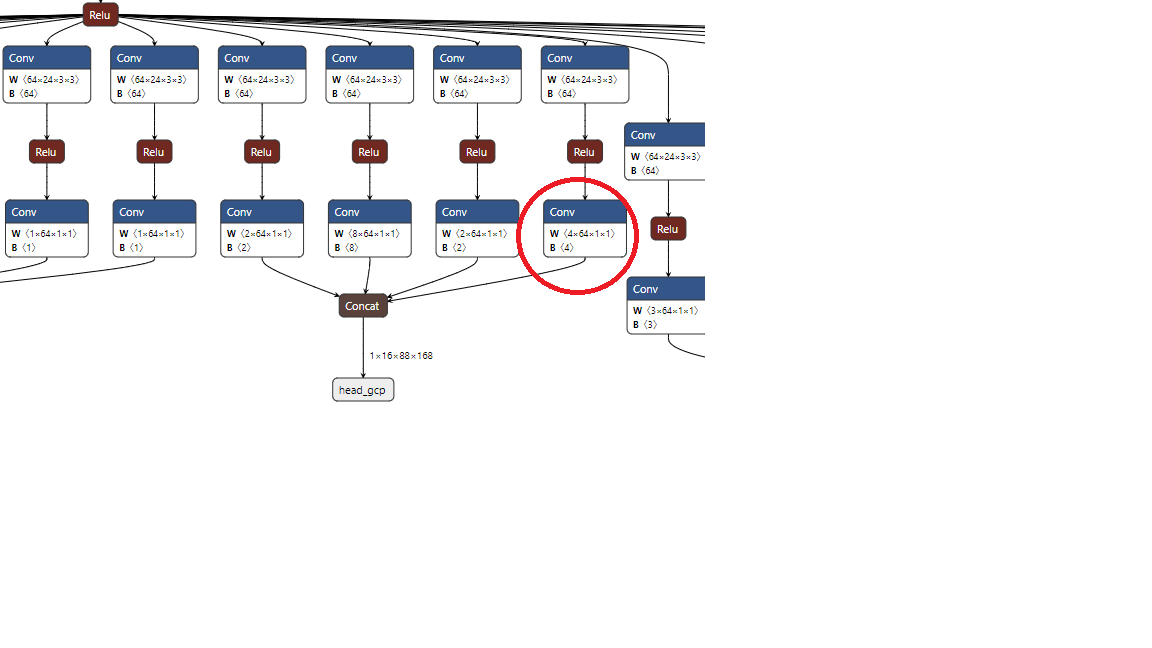
I tried the approach. It still crashed . At the time of crash, the tegrastats shows the mem usage very low, only around 8GB.
I set the workspace to 2600, 2700, 26000, 27000, all the same results. I rebooted the orin box after each try.
BTW your unit is MB, so 26 GB should be 26000, not 2600. Anyway I tried both them all.
I attached the results for both 2600 and 26000, exactly the same error.
======= workspace:2600 ============================================
11-17-2022 14:22:29 RAM 8116/30536MB (lfb 4915x4MB) SWAP 0/15268MB (cached 0MB) CPU [100%@2201,0%@2201,0%@2201,0%@2201,3%@729,24%@729,22%@729,18%@729,60%@2201,2%@2201,0%@2201,0%@2201] EMC_FREQ 0% GR3D_FREQ 0% CV0@-256C CPU@49.5C Tboard@37C SOC2@45.093C Tdiode@39C SOC0@45.562C CV1@-256C GPU@44.375C tj@49.5C SOC1@44.218C CV2@-256C
11-17-2022 14:22:30 RAM 8116/30536MB (lfb 4915x4MB) SWAP 0/15268MB (cached 0MB) CPU [100%@2201,0%@2201,0%@2201,0%@2201,4%@729,19%@729,25%@729,19%@729,55%@2201,8%@2201,0%@2201,0%@2201] EMC_FREQ 0% GR3D_FREQ 0% CV0@-256C CPU@50.125C Tboard@37C SOC2@44.968C Tdiode@39.25C SOC0@45.562C CV1@-256C GPU@44.031C tj@50.125C SOC1@44.187C CV2@-256C
11-17-2022 14:22:31 RAM 8116/30536MB (lfb 4915x4MB) SWAP 0/15268MB (cached 0MB) CPU [100%@2201,0%@2201,0%@2201,0%@2201,7%@2201,22%@2201,20%@2201,50%@2201,9%@729,2%@729,0%@729,0%@729] EMC_FREQ 0% GR3D_FREQ 0% CV0@-256C CPU@50.343C Tboard@37C SOC2@45.093C Tdiode@39C SOC0@45.531C CV1@-256C GPU@44.062C tj@50.343C SOC1@44.218C CV2@-256C
11-17-2022 14:22:32 RAM 6142/30536MB (lfb 5180x4MB) SWAP 0/15268MB (cached 0MB) CPU [75%@2201,0%@2201,0%@2201,18%@2201,7%@729,14%@729,23%@729,11%@729,0%@729,0%@729,0%@729,0%@729] EMC_FREQ 0% GR3D_FREQ 5% CV0@-256C CPU@49.875C Tboard@37C SOC2@44.812C Tdiode@39C SOC0@45.625C CV1@-256C GPU@44.125C tj@49.281C SOC1@44.218C CV2@-256C
11-17-2022 14:22:33 RAM 4898/30536MB (lfb 5408x4MB) SWAP 0/15268MB (cached 0MB) CPU [0%@729,0%@729,0%@729,6%@729,0%@729,0%@729,0%@729,0%@729,0%@729,0%@729,0%@729,0%@729] EMC_FREQ 0% GR3D_FREQ 0% CV0@-256C CPU@48.5C Tboard@37C SOC2@44.437C Tdiode@39C SOC0@45.718C CV1@-256C GPU@-256C tj@48.906C SOC1@44.218C CV2@-256C
=== trtexec log ===
[11/17/2022-14:22:31] [W] [TRT] [0xaaab3ff24180]:151 :ScratchObject in storeCachedObject: at optimizer/gpu/cudnn/convolutionBuilder.cpp: 170 idx: 735118 time: 1.28e-07
[11/17/2022-14:22:31] [W] [TRT] [0xaaaaf570aef0]:4 :: weight zero-point in internalAllocate: at runtime/common/weightsPtr.cpp: 102 idx: 155 time: 1.6e-07
[11/17/2022-14:22:31] [W] [TRT] [0xaaab3fe4c9c0]:151 :ScratchObject in storeCachedObject: at optimizer/gpu/cudnn/convolutionBuilder.cpp: 170 idx: 563346 time: 9.6e-08
[11/17/2022-14:22:31] [W] [TRT] [0xaaab41d09900]:151 :ScratchObject in storeCachedObject: at optimizer/gpu/cudnn/convolutionBuilder.cpp: 170 idx: 735130 time: 2.56e-07
[11/17/2022-14:22:31] [W] [TRT] [0xaaab41cf9ff0]:151 :ScratchObject in storeCachedObject: at optimizer/gpu/cudnn/convolutionBuilder.cpp: 170 idx: 735142 time: 6.4e-08
[11/17/2022-14:22:31] [W] [TRT] -------------- The current device memory allocations dump as below --------------
[11/17/2022-14:22:31] [W] [TRT] [0]:89088 :CASK device reserved buffer in initCaskDeviceBuffer: at /_src/build/aarch64-gnu/release/runtime/gpu/cask/caskUtils.h: 459 idx: 244073 time: 0.0101787
[11/17/2022-14:22:31] [W] [TRT] Requested amount of GPU memory (89088 bytes) could not be allocated. There may not be enough free memory for allocation to succeed.
[11/17/2022-14:22:31] [W] [TRT] Skipping tactic 21 due to insufficient memory on requested size of 89088 detected for tactic 0xff4d370e229c1e8e.
[11/17/2022-14:22:31] [E] Error[4]: [optimizer.cpp::computeCosts::3625] Error Code 4: Internal Error (Could not find any implementation for node node_of_772 due to insufficient workspace. See verbose log for requested sizes.)
[11/17/2022-14:22:31] [E] Error[2]: [builder.cpp::buildSerializedNetwork::636] Error Code 2: Internal Error (Assertion engine != nullptr failed. )
[11/17/2022-14:22:31] [E] Engine could not be created from network
[11/17/2022-14:22:31] [E] Building engine failed
[11/17/2022-14:22:31] [E] Failed to create engine from model or file.
[11/17/2022-14:22:31] [E] Engine set up failed
&&&& FAILED TensorRT.trtexec [TensorRT v8401] # /usr/src/tensorrt/bin/trtexec --onnx=c3dv2.3.k4.onnx --saveEngine=c3d_best.engine --best --allowGPUFallback --memPoolSize=workspace:2600
======workspace:26000 ============================
=== at/after crash, mem diff is only 3G+ ===
11-17-2022 14:06:13 RAM 8131/30536MB (lfb 4884x4MB) SWAP 0/15268MB (cached 0MB) CPU [100%@2201,0%@2201,0%@2201,0%@2201,26%@729,2%@729,22%@729,18%@729,9%@2201,48%@2201,3%@2201,0%@2201] EMC_FREQ 0% GR3D_FREQ 0% CV0@-256C CPU@49.531C Tboard@37C SOC2@44.906C Tdiode@38.75C SOC0@45.718C CV1@-256C GPU@44.156C tj@49.75C SOC1@44.187C CV2@-256C
11-17-2022 14:06:14 RAM 8130/30536MB (lfb 4884x4MB) SWAP 0/15268MB (cached 0MB) CPU [96%@2201,0%@2201,0%@2201,0%@2201,19%@729,10%@729,10%@729,19%@729,0%@729,48%@729,5%@729,0%@729] EMC_FREQ 0% GR3D_FREQ 0% CV0@-256C CPU@49.218C Tboard@37C SOC2@44.687C Tdiode@39C SOC0@45.656C CV1@-256C GPU@44.187C tj@49.218C SOC1@44.218C CV2@-256C
11-17-2022 14:06:15 RAM 4905/30536MB (lfb 5358x4MB) SWAP 0/15268MB (cached 0MB) CPU [8%@729,0%@729,0%@729,26%@729,0%@729,0%@729,0%@729,0%@729,0%@729,0%@729,0%@729,0%@729] EMC_FREQ 0% GR3D_FREQ 0% CV0@-256C CPU@48.531C Tboard@37C SOC2@44.468C Tdiode@39C SOC0@45.437C CV1@-256C GPU@-256C tj@48.812C SOC1@44.281C CV2@-256C
11-17-2022 14:06:16 RAM 4905/30536MB (lfb 5358x4MB) SWAP 0/15268MB (cached 0MB) CPU [0%@729,0%@729,0%@729,0%@729,0%@729,0%@729,0%@729,0%@729,0%@729,0%@729,0%@729,0%@729] EMC_FREQ 0% GR3D_FREQ 0% CV0@-256C CPU@48.562C Tboard@37C SOC2@44.343C Tdiode@39C SOC0@45.375C CV1@-256C GPU@-256C tj@48.562C SOC1@44.281C CV2@-256C
=== trtexec log ===
11/17/2022-14:06:14] [W] [TRT] [0xaaab5c6c46d0]:151 :ScratchObject in storeCachedObject: at optimizer/gpu/cudnn/convolutionBuilder.cpp: 170 idx: 735130 time: 2.56e-07
[11/17/2022-14:06:14] [W] [TRT] [0xaaab5b03e980]:151 :ScratchObject in storeCachedObject: at optimizer/gpu/cudnn/convolutionBuilder.cpp: 170 idx: 735139 time: 1.28e-07
[11/17/2022-14:06:14] [W] [TRT] [0xaaab0f29c220]:4 :: weight zero-point in internalAllocate: at runtime/common/weightsPtr.cpp: 102 idx: 727 time: 2.56e-07
[11/17/2022-14:06:14] [W] [TRT] [0xaaab56e3e410]:151 :ScratchObject in storeCachedObject: at optimizer/gpu/cudnn/convolutionBuilder.cpp: 170 idx: 735142 time: 6.4e-08
[11/17/2022-14:06:14] [W] [TRT] [0xaaab5afc46b0]:151 :ScratchObject in storeCachedObject: at optimizer/gpu/cudnn/convolutionBuilder.cpp: 170 idx: 499319 time: 1.92e-07
[11/17/2022-14:06:14] [W] [TRT] -------------- The current device memory allocations dump as below --------------
[11/17/2022-14:06:14] [W] [TRT] [0]:89088 :CASK device reserved buffer in initCaskDeviceBuffer: at /_src/build/aarch64-gnu/release/runtime/gpu/cask/caskUtils.h: 459 idx: 244093 time: 0.0098853
[11/17/2022-14:06:14] [W] [TRT] Requested amount of GPU memory (89088 bytes) could not be allocated. There may not be enough free memory for allocation to succeed.
[11/17/2022-14:06:14] [W] [TRT] Skipping tactic 21 due to insufficient memory on requested size of 89088 detected for tactic 0xff4d370e229c1e8e.
[11/17/2022-14:06:14] [E] Error[10]: [optimizer.cpp::computeCosts::3628] Error Code 10: Internal Error (Could not find any implementation for node node_of_772.)
[11/17/2022-14:06:14] [E] Error[2]: [builder.cpp::buildSerializedNetwork::636] Error Code 2: Internal Error (Assertion engine != nullptr failed. )
[11/17/2022-14:06:14] [E] Engine could not be created from network
[11/17/2022-14:06:14] [E] Building engine failed
[11/17/2022-14:06:14] [E] Failed to create engine from model or file.
[11/17/2022-14:06:14] [E] Engine set up failed
&&&& FAILED TensorRT.trtexec [TensorRT v8401] # /usr/src/tensorrt/bin/trtexec --onnx=c3dv2.3.k4.onnx --saveEngine=c3d_best.engine --best --allowGPUFallback --memPoolSize=workspace:26000