Dear all,
I’m trying to solve an insistent problem: my Ubuntu 18.04.4 LTS is randomly freezing when (apparently) using my graphics card (RTX 2080 SUPER). Kernel logs don’t show anything useful (syslog, kern, and xorg attached).
When the freezing occurs, I can’t use either mouse or keyboard. Pressing any key on my keyboard also makes the numlock key goes off, which makes it impossible to safely reboot my system with the ALT + SysRQ method. Disconnecting/reconnecting the USB cables does not solve the problem.
I’ve noted this freezing problem occurs under two circumstances: (i) while training a deep learning model using TensorFlow 1.14 and CUDA, and (ii) while playing DoTA2 (although this DoTA2 freezing is fairly new, it does not occur every time).
I have already tried the following “possible solutions”, but to no avail:
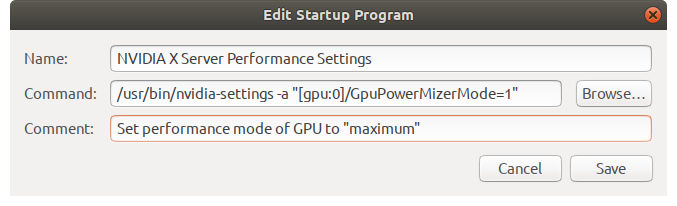
- Setting my fans to full speed/performance mode, thinking it could be an overheating problem (although it was unlikely, given that my PC is new);
- Placing nouveau drivers in /etc/modprobe.d/blacklist.conf;
- Changing a BIOS setting for “suspend to ram disabled”;
- Switching from gdm to lightdm (as recommended in this post);
- Switching from nvidia-driver-440 to nvidia-driver-435 (both proprietary drivers);
- Formatting my PC and reinstalling Ubuntu 18.04.4 LTS.
I don’t know if it’s useful, but I also have Windows 10 on dual boot with Ubuntu 18.04.4 LTS. I’ve formatted my computer yesterday thinking it would solve my problem, so I’m up to anything.
Any help would be appreciated. The nvidia-bug-report.log is also attached to this post.
Hardware & Other Settings:
SO: Ubuntu 18.04.4 LTS (Dual Boot: Windows 10)
Kernel: Linux 5.3.0-53-generic
Processor: Intel Core i9-9900KF 3.60GHz (5.0GHz Turbo)
Graphics: Asus Rog Strix GeForce RTX 2080 SUPER/PCIe/SSE2 8GB GDDR6 256Bit
GL Version: 4.5.0 NVIDIA 440.59
Motherboard: ASRock Z390 Extreme 4 Chipset Z390 Intel LGA 1151 ATX DDR4
Memory: DDR4 Corsair Vengeance RGB Pro (4x8GB) 3600MHz
Water Cooler: Corsair H115i Pro RGB 280mm
Power Supply: XFX 650W XTR Series ATX/EPS Full Modular 80PLUS GOLD, P1-650B-BEFX
Storage: SSD Corsair Force MP510 960GB M.2 2280 NVMe and HD Seagate Barracuda 1TB (only used as extra storage space, mounted on /mnt/data)
Attached Files:
nvidia-bug-report.log (1.4 MB)
xorg.log (146.8 KB)