#include <cuda_runtime.h>
#include <iostream>
__global__ void kernel(int* data, int value, int iterations) {
int idx = threadIdx.x;
for (int i = 0; i < iterations; ++i) {
data[idx] += value;
}
}
int main() {
const int numElements = 10 * 1024 * 1024;
const int iterations = 1 << 20;
const int numRounds = 10;
int* devData1, * devData2;
int* hostData1, * hostData2;
cudaMallocHost((void**)&hostData1, numElements * sizeof(int));
cudaMallocHost((void**)&hostData2, numElements * sizeof(int));
cudaMalloc((void**)&devData1, numElements * sizeof(int));
cudaMalloc((void**)&devData2, numElements * sizeof(int));
cudaStream_t stream1, stream2;
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
kernel << <1, 1024, 0, stream1 >> > (devData1, 1, iterations);
cudaStreamSynchronize(stream1);
cudaMemcpyAsync(hostData1, devData1, numElements * sizeof(int), cudaMemcpyDeviceToHost, stream1);
kernel << <1, 1024, 0, stream2 >> > (devData2, 2, iterations);
cudaStreamSynchronize(stream2);
cudaMemcpyAsync(hostData2, devData2, numElements * sizeof(int), cudaMemcpyDeviceToHost, stream2);
std::cout << "Test completed." << std::endl;
return 0;
}
win10
vs2022
cuda 12.6
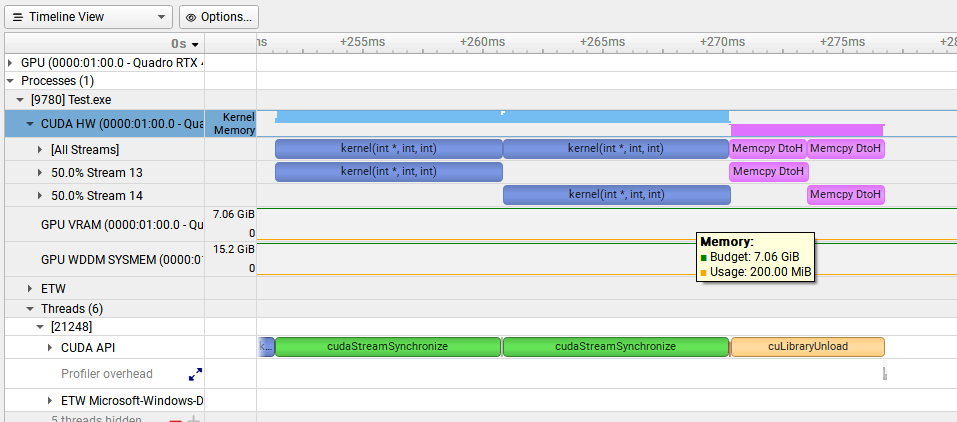
The above demo code, hope stream1 in copy, stream2 can execute kernel to achieve overlap, but the test results do not achieve overlap. What is the reason?