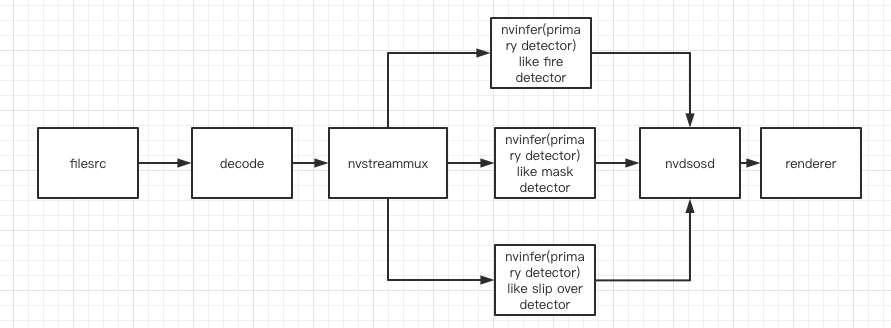
Hi!
Now I will deploy the model to my Jetson TX2 by deepstream through triton inference server.
I am using a Jetson TX2 with deep-stream 5-0.
- got engine file
followed the steps of GitHub - Tianxiaomo/pytorch-YOLOv4: PyTorch ,ONNX and TensorRT implementation of YOLOv4,
python demo_darknet2onnx.py /workspace/pytorch-YOLOv4/cfg/yolov4.cfg /workspace/pytorch-YOLOv4/yolov4.weights /workspace/pytorch-YOLOv4/data/dog.jpg 1
/usr/src/tensorrt/bin/trtexec --onnx=yolov4_1_3_608_608_static.onnx --explicitBatch --saveEngine=yolov4_1_3_608_608_static.engine --workspace=2048 --fp16
- config triton info
source1_primary_yoloV4_original.txt (3.1 KB)
config_infer_primary_yoloV4_original.txt (2.4 KB)
config.pbtxt (568 Bytes) - NvDsInferParseCustomYoloV4
git clone https://github.com/NVIDIA-AI-IOT/yolov4_deepstream.git
/yolov4_deepstream/deepstream_yolov4/nvdsinfer_custom_impl_Yolo
- got error as following:
Opening in BLOCKING MODE
Opening in BLOCKING MODE
NvMMLiteOpen : Block : BlockType = 261
NVMEDIA: Reading vendor.tegra.display-size : status: 6
NvMMLiteBlockCreate : Block : BlockType = 261
** INFO: <bus_callback:167>: Pipeline running
ERROR: TRTIS: TrtServerRequest failed to create inference request providerV2, trtis_err_str:INVALID_ARG, err_msg:unexpected shape for input ‘input’ for model ‘yolov4_original’. Expected [1,3,608,608], got [3,608,608]
ERROR: TRTIS failed to create request for model: yolov4_original version:-1
ERROR: TRT-IS run failed to create request for model: yolov4_original
ERROR: TRT-IS failed to run inference on model yolov4_original, nvinfer error:NVDSINFER_TRTIS_ERROR
0:00:14.451512879 20883 0x7e886e5530 WARN nvinferserver gstnvinferserver.cpp:519:gst_nvinfer_server_push_buffer:<primary_gie> error: inference failed with unique-id:1
ERROR from primary_gie: inference failed with unique-id:1
Debug info: /dvs/git/dirty/git-master_linux/deepstream/sdk/src/gst-plugins/gst-nvinferserver/gstnvinferserver.cpp(519): gst_nvinfer_server_push_buffer (): /GstPipeline:pipeline/GstBin:primary_gie_bin/GstNvInferServer:primary_gie
ERROR: TRTIS: TrtServerRequest failed to create inference request providerV2, trtis_err_str:INVALID_ARG, err_msg:unexpected shape for input ‘input’ for model ‘yolov4_original’. Expected [1,3,608,608], got [3,608,608]
ERROR: TRTIS failed to create request for model: yolov4_original version:-1
ERROR: TRT-IS run failed to create request for model: yolov4_original
ERROR: TRT-IS failed to run inference on model yolov4_original, nvinfer error:NVDSINFER_TRTIS_ERROR
0:00:14.451512879 20883 0x7e886e5530 WARN nvinferserver gstnvinferserver.cpp:519:gst_nvinfer_server_push_buffer:<primary_gie> error: inference failed with unique-id:1
ERROR from primary_gie: inference failed with unique-id:1
Debug info: /dvs/git/dirty/git-master_linux/deepstream/sdk/src/gst-plugins/gst-nvinferserver/gstnvinferserver.cpp(519): gst_nvinfer_server_push_buffer (): /GstPipeline:pipeline/GstBin:primary_gie_bin/GstNvInferServer:primary_gie
ERROR: TRTIS: TrtServerRequest failed to create inference request providerV2, trtis_err_str:INVALID_ARG, err_msg:unexpected shape for input ‘input’ for model ‘yolov4_original’. Expected [1,3,608,608], got [3,608,608]
ERROR: TRTIS failed to create request for model: yolov4_original version:-1
ERROR: TRT-IS run failed to create request for model: yolov4_original
ERROR: TRT-IS failed to run inference on model yolov4_original, nvinfer error:NVDSINFER_TRTIS_ERROR
0:00:14.453875925 20883 0x7e886e5530 WARN nvinferserver gstnvinferserver.cpp:519:gst_nvinfer_server_push_buffer:<primary_gie> error: inference failed with unique-id:1
ERROR from primary_gie: inference failed with unique-id:1
Debug info: /dvs/git/dirty/git-master_linux/deepstream/sdk/src/gst-plugins/gst-nvinferserver/gstnvinferserver.cpp(519): gst_nvinfer_server_push_buffer (): /GstPipeline:pipeline/GstBin:primary_gie_bin/GstNvInferServer:primary_gie
ERROR: TRTIS: TrtServerRequest failed to create inference request providerV2, trtis_err_str:INVALID_ARG, err_msg:unexpected shape for input ‘input’ for model ‘yolov4_original’. Expected [1,3,608,608], got [3,608,608]
ERROR: TRTIS failed to create request for model: yolov4_original version:-1
ERROR: TRT-IS run failed to create request for model: yolov4_original