Description
I will transfer my ONNX model to Tensorrt, After completing a series of procedures, I obtained a very strange and unexpected result that was far from what I had expected.
I suspect there might be something wrong with my program, which is causing the engine not to function properly.
I suspect it might be a problem with the Tensorrt inference part, but I haven’t been able to identify the cause.
This is the output result of my program, It is increasing:
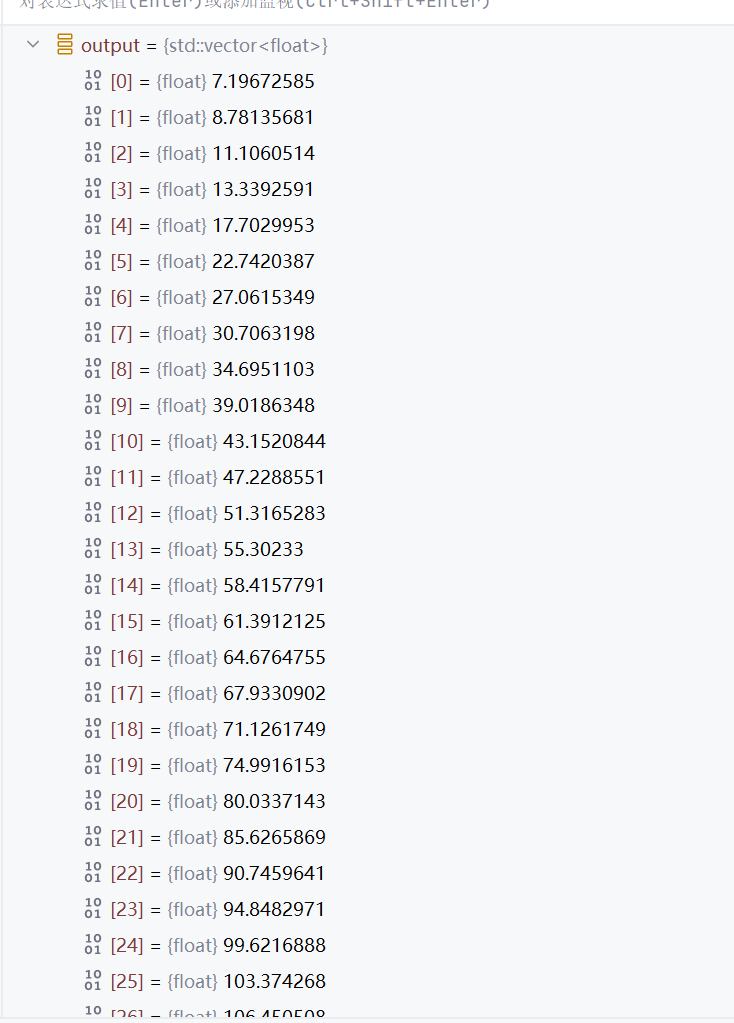
My module is 2 classes, It should be like this:
[x, y, w, h, c1, c2] * 78200

Environment
TensorRT Version: 8.5.2.2
GPU Type: Jetson Xavier NX
Jetpack Version: 5.1.2
CUDA Version: 11.4.315
CUDNN Version: 8.6.0.166
The following is my main program:
#include <opencv2/opencv.hpp>
#include <string>
#include <chrono>
#include <iostream>
#include "Yolo.h"
#include "Camera.h"
#include "config.h"
#include "Tools.h"
std::string engineFile = "/home/nvidia/Desktop/6.3.engine";
int main()
{
Yolo yolo(engineFile);
Camera camera(0);
std::vector<float> input(inputSize, 0.0f);
std::vector<float> output(outputSize, 0.0f);
cv::Mat frame = camera.get_frame();
input = preprocessImage(frame);
if (!yolo.infer(input, output))
std::cout << "yolo.infer error" << std::endl;
for (int i = 0; i < 20; i++)
std::cout << output[i] << std::endl;
return 0;
}
Yolo.cpp
//
// Created by JIN on 25-5-21.
//
#include "Yolo.h"
#include <NvInferRuntime.h>
#include <fstream>
#include <iostream>
#include "Tools.h"
#include "config.h"
Yolo::Yolo(const std::string& path)
{
try
{
// 1. 加载 engine 数据
engineData = loadEngineFile(path);
if (engineData.empty())
throw std::runtime_error("Failed to load engine data.");
// 2. 创建 runtime
runtime = nvinfer1::createInferRuntime(logger);
if (!runtime)
throw std::runtime_error("Failed to create TensorRT runtime.");
// 3. 反序列化 engine
engine = runtime->deserializeCudaEngine(engineData.data(), engineData.size());
if (!engine)
throw std::runtime_error("Failed to deserialize engine.");
// 4. 创建执行上下文
context = engine->createExecutionContext();
if (!context)
throw std::runtime_error("Failed to create execution context.");
// 5. 创建 CUDA stream
cudaError_t err = cudaStreamCreate(&stream);
if (err != cudaSuccess)
throw std::runtime_error("Failed to create CUDA stream: " + std::string(cudaGetErrorString(err)));
// 6. 分配 GPU 内存
err = cudaMallocAsync(&inputDevice, inputSize * sizeof(float), stream);
if (err != cudaSuccess)
throw std::runtime_error("Failed to allocate input device memory.");
err = cudaMallocAsync(&outputDevice, outputSize * sizeof(float), stream);
if (err != cudaSuccess)
throw std::runtime_error("Failed to allocate output device memory.");
// 7. 设置 Tensor 地址
if (!context->setTensorAddress(inputName, inputDevice) ||
!context->setTensorAddress(outputName, outputDevice))
throw std::runtime_error("Failed to set tensor addresses.");
}
catch (const std::exception& ex)
{
std::cerr << "Yolo constructor failed: " << ex.what() << std::endl;
cleanup(); // 清理已分配的资源
throw; // 重新抛出异常
}
}
Yolo::~Yolo()
{
cleanup();
}
bool Yolo::infer(const std::vector<float>& inputHost, std::vector<float>& outputHost) const
{
// 输入大小检查(防止越界)
if (inputHost.size() != inputSize) {
std::cerr << "[infer] Input size mismatch: expected " << inputSize << ", got " << inputHost.size() << std::endl;
return false;
}
// 1. 拷贝输入数据到 GPU
cudaError_t err = cudaMemcpyAsync(inputDevice, inputHost.data(), inputSize * sizeof(float),
cudaMemcpyHostToDevice, stream);
if (err != cudaSuccess) {
std::cerr << "[infer] cudaMemcpyAsync (input) failed: " << cudaGetErrorString(err) << std::endl;
return false;
}
// 2. 推理执行
if (!context || !context->enqueueV3(stream)) {
std::cerr << "[infer] enqueueV3 failed!" << std::endl;
return false;
}
// 3. 同步 stream
err = cudaStreamSynchronize(stream);
if (err != cudaSuccess) {
std::cerr << "[infer] cudaStreamSynchronize failed: " << cudaGetErrorString(err) << std::endl;
return false;
}
// 4. 拷贝输出数据到 Host
outputHost.resize(outputSize); // resize 是安全的,会释放旧内存
err = cudaMemcpy(outputHost.data(), outputDevice, outputSize * sizeof(float),
cudaMemcpyDeviceToHost);
if (err != cudaSuccess) {
std::cerr << "[infer] cudaMemcpy (output) failed: " << cudaGetErrorString(err) << std::endl;
return false;
}
return true;
}
void Yolo::cleanup() const
{
if (inputDevice) cudaFree(inputDevice);
if (outputDevice) cudaFree(outputDevice);
if (stream) cudaStreamDestroy(stream);
delete context;
delete engine;
delete runtime;
}
config.h
#ifndef CONFIG_H
#define CONFIG_H
inline constexpr int imgWidth = 736;
inline constexpr int imgHeight = 1280;
inline constexpr int inputSize = 1 * 3 * imgHeight * imgWidth;
inline constexpr int outputSize = 1 * 6 * 78200;
inline constexpr const char* inputName = "images";
inline constexpr const char* outputName = "output0";
#endif //CONFIG_H
Tool.cpp
//
// Created by JIN on 25-6-3.
//
#include "Tools.h"
#include <fstream>
#include "config.h"
// 读取engine文件到内存buffer
std::vector<char> loadEngineFile(const std::string& filepath)
{
std::ifstream file(filepath, std::ios::binary | std::ios::ate);
if (!file)
throw std::runtime_error("Failed to open engine file");
std::streamsize size = file.tellg();
file.seekg(0, std::ios::beg);
std::vector<char> buffer(size);
if (!file.read(buffer.data(), size))
throw std::runtime_error("Failed to read engine file");
return buffer;
}
std::vector<float> preprocessImage(const cv::Mat& frame)
{
if (frame.empty()) {
throw std::runtime_error("Input frame is empty.");
}
// 1. Resize to model input size (1280x736)
cv::Mat resized;
cv::resize(frame, resized, cv::Size(imgWidth, imgHeight));
// 2. Convert BGR to RGB
cv::Mat rgb;
cv::cvtColor(resized, rgb, cv::COLOR_BGR2RGB);
// 3. Convert to float and normalize to [0,1]
rgb.convertTo(rgb, CV_32FC3, 1.0 / 255.0);
// 4. Split channels (to get HWC -> CHW layout)
std::vector<cv::Mat> channels(3);
cv::split(rgb, channels);
int imageSize = imgWidth * imgHeight;
std::vector<float> tensor(3 * imageSize); // CHW format
// 5. Copy each channel data to tensor buffer
for (int i = 0; i < 3; ++i) {
memcpy(tensor.data() + i * imageSize, channels[i].ptr<float>(), imageSize * sizeof(float));
}
return tensor;
}
I sincerely hope that anyone can help me. Thank you very much.