And we were able to get the result of batch decoding for 5 UHDs (4K Image 3840 x 2160) in 5 ms, from cuda driver 515.65.01 and cuda 11.7.
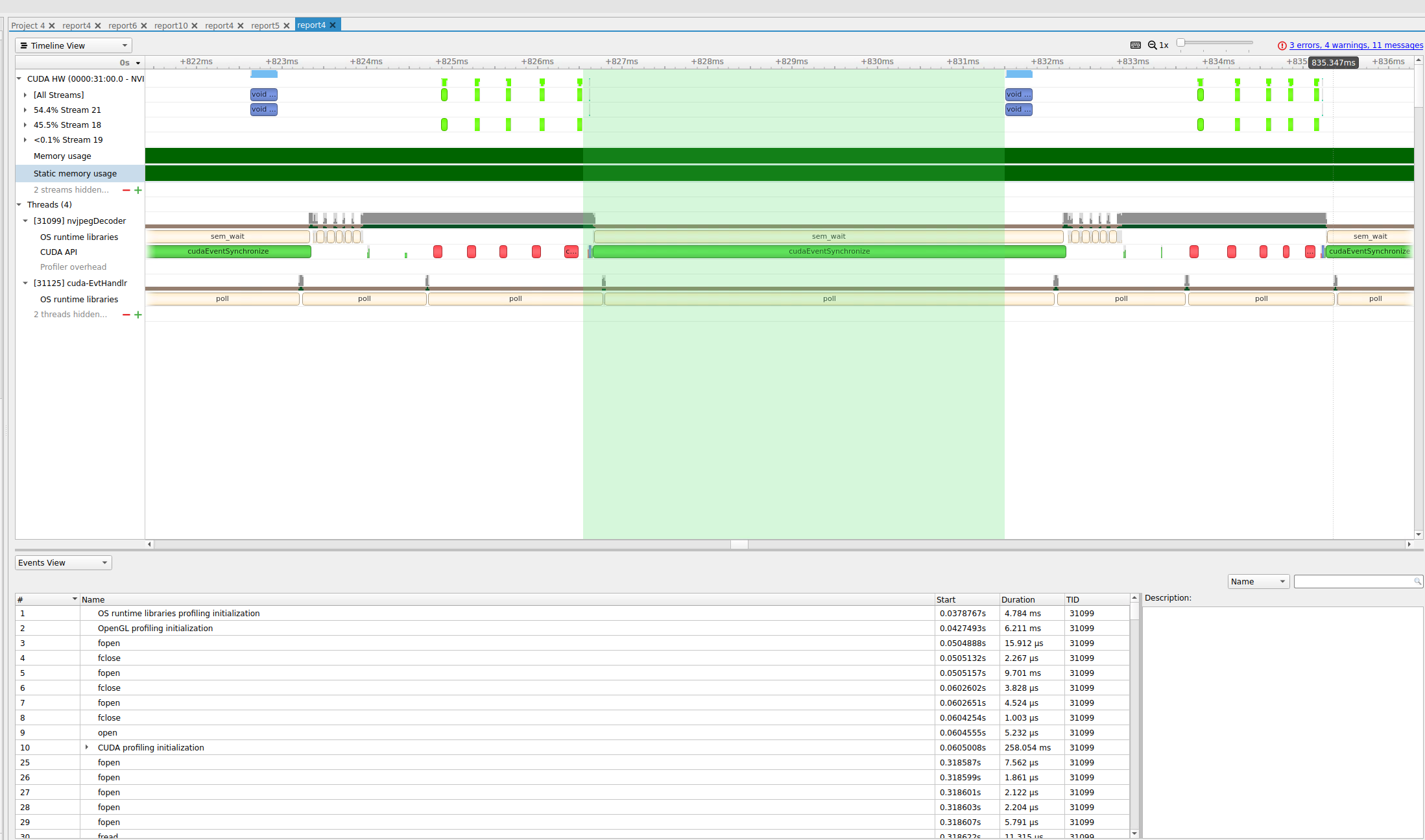
A quick look at the profiling result, we were able to find that after uploading the 5 batch JPEGs to the hardware JPEG decoder, it waited for 5 ms before the actual nvjpeg::batchedYCbCr2RGB_kernelv2 function call.
I am wondering what exactly is kernel doing between these 5ms? This 5ms is limiting the decoding capabilities because when I do 1 JPEG decoding it will also take 5ms.
Hi Robert, thanks for providing the information.
This 5 ms time interval happens after JPEG has completed Host To Device, indicated by the green box in the nsys profiler.
Does this mean the 5 ms is the initialization overhead from GPU kernels?
I was pointing out some general ideas. If I were investigating such things I would certainly test to see how repeatable the observation is. If it was primarily associated with the first invocation, and was different on subsequent invocations, that might be a clue.
I’m not at liberty to explain in detail the contents of any of our non-public libraries.
If you feel this is a performance issue/concern you can file a bug.
However, when we do profiling, we found the reason behind this number is a little bit tricky: we can only reproduce this number by decoding a batch of 5 images for 200 cycles ( 1000 images), which takes around ~5 ms for each batch, and total of 1000 ms. When we do a batch of 1 image for 1000 cycles, it also takes around ~5ms for each batch, but a total of 5000 ms.
We are aware that the A100 NVJPEG hardware decoder has a 5 core decode engine so it is best to do decode for 5 JPEGs in a batch.
But I am curious what cuda kernel is doing for each batch, especially after HToD but right before batchedYCbCr2RGB_kernelv2. It looks to me that this gap is actually limiting the batch decoding speed.
It wouldn’t surprise me at all that a performance claim made with the statement of a batch size of 128 is not necessarily reproducible with a batch size of 1. This is certainly not the only example of that.
I have claimed that my test setup using batch 5, has reproduced the same result from that blog, which is using batch 128, as you have pointed out.
The reason batch 128 can produce almost the same result as batch 5 is because the hardware has 5 cores to do the job, so batch 128 will be executed in 5 x 25 + 3 x 1 in the kernel. This means the if you call nvjpegDecodeBatched with 128 images, cuda kernel will help to divide it by 25 sub-batch for 5 images, and 1 sub-batch of 3 images and decode them sequentially in 5 decoder cores.
I am not surprise either that batch 128 and batch 1 does not produce the same result. But I want to understand more into the details.
Let me rephrase my question: what exactly is the CUDA kernel doing in the blank area from the nsys profiler, see the attached image. Batch 1/5/128, all of them, have the same waiting behavior.
This is within the confines of a particular jpeg decode function call, i.e. in the library routine. I’m not at liberty to describe what our non-public library routines do in any detail.
A library routine is not a “kernel” in the typical CUDA usage sense or in the sense of the jpeg decoder library. It is a sequence of host code, that may do memory copies, kernel launches, as well as nearly any other host code activity you can imagine, in the process of performing the requested function. A call into the jpeg decode library is likely to do a number of things and not be purely constrained to a CUDA kernel. It may indeed launch one or more kernels, but it is likely doing other things as well. I’m not at liberty to describe all that in any detail.
In the gap that you are indicating, if the profiler does not indicate any kernel running, then it is likely other host code activity (within the library routine) that is taking place there.
If you think this is an important performance limiter, and/or if you would like to see additional documentation in this area, you can file a bug requesting it to be addressed. I don’t have anything else to suggest or any other information to provide.
On A100, the jpeg hardware decode engine isn’t a CUDA engine, nor is it driven by a CUDA kernel. So when the nvjpeg hardware decoder is running, I wouldn’t expect to see CUDA kernel activity in nsight systems associated with the nvjpeg hardware decoder. It may be that there is H->D transfer of data, followed by some activity in the nvjpeg hardware decode engine that is simply showing up as a gap in nsight systems, followed by CUDA kernel activity, that may be doing some final processing steps via CUDA kernels, to complete the jpeg decode process. That is really just a guess, but it could possibly be an explanation for the profiler output.
The sem_wait could then be an internal signal used to signal that the hardware jpeg decode process is complete, so that the final CUDA kernel post-processing kernel(s) can be launched.
You can purchase NVIDIA customer support for your A100 installation by purchasing a NVIDIA AI for Enterprise license for the machine. Typically you would do this by working through the vendor that you purchased the machine from. Even after machine purchase, you should be able to add a NVIDIA AI Enterprise license through that vendor.