Sorry I meant Triton client and not TAO client.
Below is the ongoing of my workflow:
# evaluate the model after pruning and retraining
!tao classification evaluate -e $TAO_SPECS_DIR/vgg19/config.txt\
-k $KEY
#running the inference on all images included in Female folder of the validation dataset and generating result.csv file
!tao classification inference -m $TAO_EXPERIMENT_DIR/vgg19/weights/vgg_pruned_trained.tlt \
-d $TAO_DATA_DIR/val/Female/ \
-k $KEY \
-cm $TAO_EXPERIMENT_DIR/vgg19/classmap.json \
-e $TAO_SPECS_DIR/vgg19/config.txt
# export model and TensorRT engine
!tao classification export -m $TAO_EXPERIMENT_DIR/vgg19/weights/vgg_pruned_trained.tlt \
-o $TAO_EXPERIMENT_DIR/export/gender_model.etlt \
--engine_file $TAO_EXPERIMENT_DIR/export/gender_model.engine \
-k $KEY \
--classmap_json $TAO_EXPERIMENT_DIR/vgg19/classmap.json \
--gen_ds_config
# create directory for model and place under the Ripository of Triton models
!mkdir -p models/gender_classification_model/1
# copy gender_model.engine from model export to the model repository
!cp $LOCAL_EXPERIMENT_DIR/export/gender_model.engine models/gender_classification_model/1/model.plan
#creating the configuration file for the model and write into config.pbtxt
configuration = """
name: "gender_classification_model"
platform: "tensorrt_plan"
input: [
{
name: "input_1"
data_type: TYPE_FP32
format: FORMAT_NCHW
dims: [ 3, 224, 224 ]
}
]
output: {
name: "predictions/Softmax"
data_type: TYPE_FP32
dims: [ 2, 1, 1 ]
}
"""
with open('models/gender_classification_model/config.pbtxt', 'w') as file:
file.write(configuration)
# testing the model on triton server
!curl -v triton:8000/v2/models/gender_classification_model
#pre_processing image before sending to Triton for inference
from PIL import Image
def preprocess_image(file_path):
image=Image.open(file_path).resize((224, 224))
image_ary=np.asarray(image).astype(np.float32)
image_ary[:, :, 0]=(image_ary[:, :, 0]-103.939)*1
image_ary[:, :, 1]=(image_ary[:, :, 1]-116.779)*1
image_ary[:, :, 2]=(image_ary[:, :, 2]-123.68)*1
image_ary=np.transpose(image_ary, [2, 0, 1])
return image_ary
import tritonclient.http as tritonhttpclient
VERBOSE=False
input_name='input_1'
input_shape=(3, 224, 224)
input_dtype='FP32'
output_name='predictions/Softmax'
model_name='gender_classification_model'
url='triton:8000'
model_version='1'
with open(os.path.join(os.environ['LOCAL_EXPERIMENT_DIR'], 'export', 'labels.txt'), 'r') as f:
labels=f.readlines()
labels={v: k.strip() for v, k in enumerate(labels)}
labels
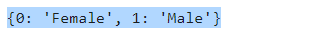
# Running inference for a single image
sample_image_ary=preprocess_image('tao_project/data/val/Female/B1073.jpg')
triton_client=tritonhttpclient.InferenceServerClient(url=url, verbose=VERBOSE)
model_metadata=triton_client.get_model_metadata(model_name=model_name, model_version=model_version)
model_config=triton_client.get_model_config(model_name=model_name, model_version=model_version)
inference_input=tritonhttpclient.InferInput(input_name, input_shape, input_dtype)
inference_input.set_data_from_numpy(sample_image_ary)
output=tritonhttpclient.InferRequestedOutput(output_name)
response=triton_client.infer(model_name,
model_version=model_version,
inputs=[inference_input],
outputs=[output])
predictions=response.as_numpy(output_name)
predictions

# Loading tao inference result csv file into df dataframe
colnames=['img_path', 'tao_inference', 'tao_score']
df=pd.read_csv('tao_project/data/val/Female/result.csv', names=colnames, header=None)
df.head()

#determining the Accuracy for female class - from result.csv
k=0
for idx, row in df.iterrows():
string = row['tao_inference']
if string=='Female':
k = k +1
Accuracy = k/df.shape[0]
print(Accuracy)
# Querying the inference on the triton server and storing results on triton_inference column
# Writing the results into a new csv file result_consolidated.csv
for idx, row in df.iterrows():
string = row['img_path']
new_string = string.replace("/workspace/tao-experiments", "tao_project" )
image_ary=preprocess_image(new_string)
inference_input.set_data_from_numpy(image_ary)
# time the process
start=time.time()
response=triton_client.infer(model_name,
model_version=model_version,
inputs=[inference_input],
outputs=[output])
predictions=response.as_numpy(output_name)
df.loc[idx, 'triton_prediction']=labels[np.argmax(predictions)].strip()
df.head()
df.to_csv('tao_project/data/val/Female/result_consolidated.csv')
# Determining the accuracy for the female class as inferenced by the triton server
j=0
for idx, row in df.iterrows():
string = row['triton_prediction']
if string=='Female':
j = j +1
Accuracy = j/df.shape[0]
print(Accuracy)
The inference has dropped from 0.94 to 0.80 just after exporting the .tlt model to the .engine model.
Am I missing any arguments in the tao export command or any other step?






