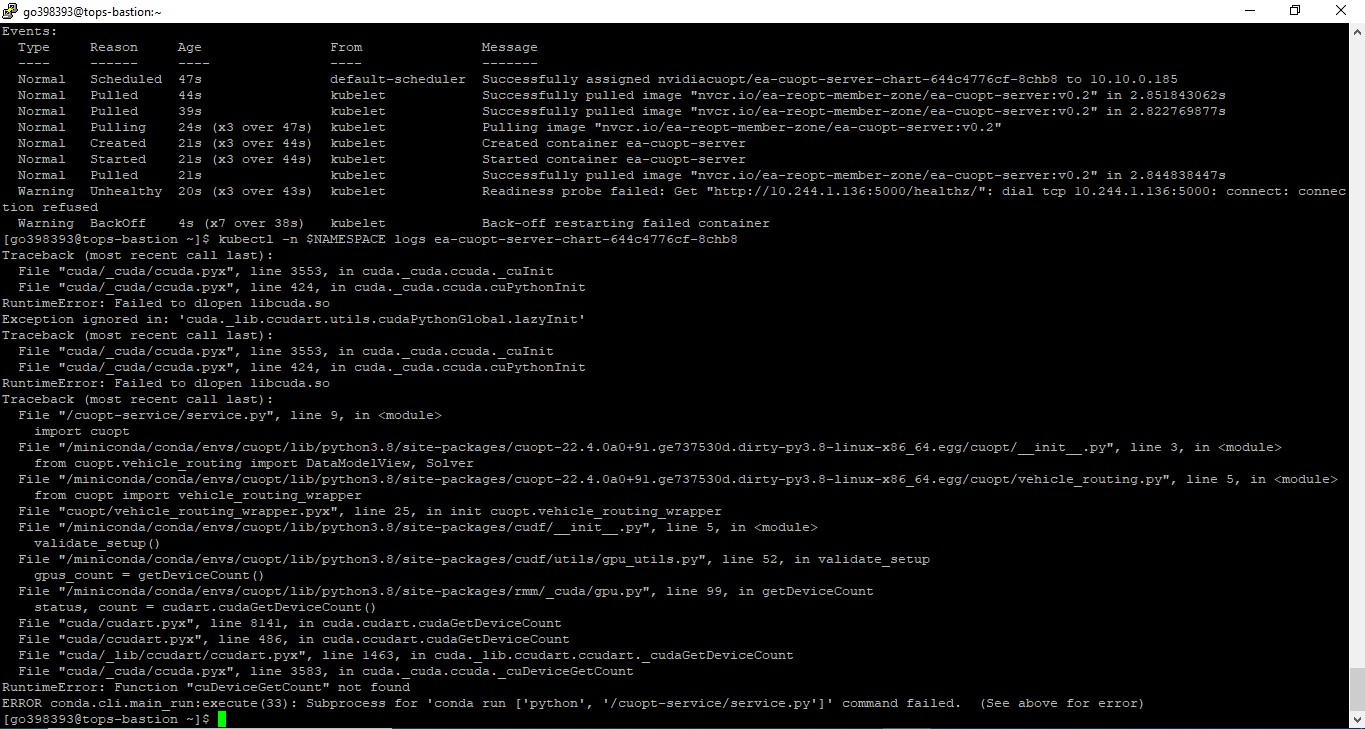
Hi Team, I am trying to deploy cuopt in OCI through helm charts. But i am facing runtime error as part of the deployment. Please find the attached screenshot for reference. Any inputs on this?
Hey, I had few questions regarding this,
- Looking at the logs, it seems container is not able to access GPU resources, have you tried to get a simple nvidia container and run it?
- can you please test whether you can run a sample nvidia container and see whether it is able to find GPUs, you can find an example at the end in this link Install Kubernetes — NVIDIA Cloud Native Technologies documentation
And you can also try to dry run container without trying to fetch cuOpt and check if nvidia GPUs are available,
- Add command from following set of commands in
ea-cuopt-server/templates/deployment.yamlwhich you downloaded
containers:
- name: {{ .Chart.Name }}
image: "{{ .Values.registry }}/{{ .Values.nvcuopt.image }}:{{ .Values.nvcuopt.version }}"
command: ["python", "-m", "http.server"]
- Uninstall existing one and install this new one
- Install the updated helm chart
- kubectl -n $NAMESPACE get all
- kubectl exec -it -n $NAMESPACE pod_name /bin/bash
- nvidia-smi
Hi, have you had a chance to try the above steps to diagnose? It seems like maybe the cluster is not successfully GPU-enabled, as @ramakrishnap suggested. Running nvidia-smi would help determine that.
Hi Team, we are working on the solution provided to me. I shall keep you posted on the result.
Thank you.
Hello @gokarna.pavuluri,
Have you solved the issue? I can create an OCI cluster to reproduce and troubleshoot in parallel if we are still looking for a solution.