Note: I have TensorRT engine of the above ONNX model which works in TensorRT framework with PyCUDA. The same engine file (with NHWC layout) can’t run on Deepstream pipeline due to NCHW memory layout requirement of Deepstream. I tried to convert the engine file to NCHW with no luck.
It would be easier if I can reuse my inference code using PyCUDA inside Deepstream Pipeline.
Do you have any reference document for using PYCUDA with Deepstream?
I saw this but it is not of much help
There is “network-input-order” parameter with nvinfer configuration. network-input-order, you don’t need to convert your model from NCHW to NHWC. You also need to input “infer-dims” parameter to give the correct input dimensions of your model with gst-nvinfer. Please read the document carefully.
gst-nvinfer is TensorRT based which is CUDA accelerated already.
Hi Fiona,
Thanks for your response.
I’ve seen the plugin “nvinfer” but using that plugin for our custom model will require implementing custom inference method. Since we have PyCUDA based inference script for our custom model, I was wondering if I could reuse that script for a quick check in Deepstream.
Seems you need consecutive several frames as the model input, right?
Please refer to deepstream-3d-action-recognition sample in /opt/nvidia/deepstream/deepstream/sources/apps/sample_apps/deepstream-3d-action-recognition, this is also a model with consecutive frames inputs.
ok, I’ll read the docs and try to understand the details you mentioned.
Also, second question is,
Even after setting the “network-input-order” and “infer-dims”, I’m seeing the error “RGB/BGR input format specified but network input channels is not 3”.
This means, Deepstream Doesn’t automatically support NHWC layout. I need to to add custom function to convert input frame from NCHW to NHWC right?
And if you could provide an example to do so, it would be great.
Your model is multiple input layers model. The default gst-nvinfer just accept single input layer model. So please change your model to single input layer model and refer to the sample of deepstream-3d-action-recognition sample in /opt/nvidia/deepstream/deepstream/sources/apps/sample_apps/deepstream-3d-action-recognition, this is also a model with consecutive frames inputs.
Can you elaborate the details about your model? The input layer is the image in HWC format. What are the input layers “i_encoder_0”, “i_encoder_1”, …? How did you generate the inputs to them?
Yes, the first input is the video frame.
The other inputs(i_encoder_0 ,…, i_encoder_4) are initialized with zeros and then on the next iteration, the previous frame’s encoder outputs(o_encoder_0, …, o_encoder_4) are assigned to each of the inputs(i_encoder_0 ,…, i_encoder_4) of the current frame respectively.
For me as a beginner, its challenging to integrate this model to Deepstream Pipeline
Even after setting this parameter to 1 (NHWC), I’m getting the same error as before:
nvinfer gstnvinfer.cpp:640:gst_nvinfer_logger:<primary-inference> NvDsInferContext[UID 1]: Error in NvDsInferContextImpl::preparePreprocess() <nvdsinfer_context_impl.cpp:971> [UID = 1]: RGB/BGR input format specified but network input channels is not 3
The parameter ‘network-input-order’ seems to be ignored even though ‘input-tensor-meta’ is not enabled.
Any suggestions on how to proceed?
gst-nvinfer does not support multiple input layers. Please convert your model to single input layer model. Or you have to modify the gst-nvinfer plugin source code to add the functions of generating the data for all input layers.
What are the input and how did you get them and process them?
def allocate_buffers(trt_engine, pipelining=False):
"""
:param trt_engine: trt_engine
:param pipelining: if True output_buffers are duplicated for pipeling
:return: the list of allocated input_buffers and output_buffers + the list of bindings
:Description:
From the input trt_engine, input/ouput buffers are allocated and the bindings defined
if pipeling is enable and tmp output buffers are allocated
"""
input_buffers = []
output_buffers = []
output_buffers_tmp = [] # For pipelining
bindings = []
for binding in trt_engine:
print("Binding: ", binding)
size = trt.volume(trt_engine.get_binding_shape(binding))
dtype = trt.nptype(trt_engine.get_binding_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(device_mem))
# Append to the appropriate list.
if trt_engine.binding_is_input(binding):
input_buffers.append(HostDeviceMem(host_mem, device_mem))
print('input engine.get_binding_dtype(binding)', trt_engine.get_binding_dtype(binding))
print('input engine.get_binding_shape(binding)', trt_engine.get_binding_shape(binding))
else:
output_buffers.append(HostDeviceMem(host_mem, device_mem))
print('output engine.get_binding_dtype(binding)', trt_engine.get_binding_dtype(binding))
print('output engine.get_binding_shape(binding)', trt_engine.get_binding_shape(binding))
if pipelining:
output_buffers_tmp.append(np.empty(trt_engine.get_binding_shape(binding), dtype=dtype))
print("bindings", bindings)
return input_buffers, output_buffers, bindings, output_buffers_tmp
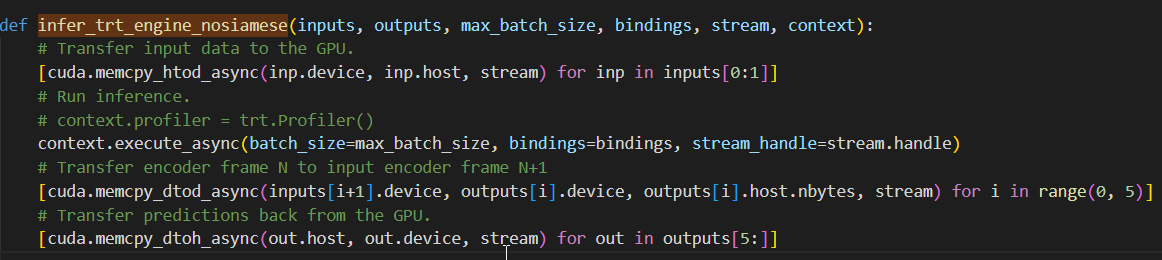
def infer_trt_engine_nosiamese(inputs, outputs, max_batch_size, bindings, stream, context):
# Transfer input data to the GPU.
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs[0:1]]
# Run inference.
# context.profiler = trt.Profiler()
context.execute_async(batch_size=max_batch_size, bindings=bindings, stream_handle=stream.handle)
# Transfer encoder frame N to input encoder frame N+1
[cuda.memcpy_dtod_async(inputs[i+1].device, outputs[i].device, outputs[i].host.nbytes, stream) for i in range(0, 5)]
# Transfer predictions back from the GPU.
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs[5:]]
There is no update from you for a period, assuming this is not an issue anymore. Hence we are closing this topic. If need further support, please open a new one. Thanks