Please, is there really a dedicated hardware accelerator for Stereo Vision in Xavier SoC? Or GPU or the programmable Vision processor must be used to achieve a reasonable FPS?
Hi JanTV1, upcoming support for hardware-accelerated stereo disparity depth mapping will be included for Xavier in the next JetPack release - please stay tuned. For now, you can use GPU to process stereo disparity.
thank you for your answer!
Based on my understanding, the JetPack is a software package. My question is maybe more HW related.
We are in a decision process of selecting a SoC vendor for a next project and the Stereo IP block may be critical as the other HW resources (GPU/VP) would be used for other compute intensive tasks.
I understand if this information isn’t public today. Do you recommend to contact a sales person for these questions?
JetPack includes the software libraries that interface to the hardware, like the GPU, DLA’s, video encoder/decoder, CSI/ISP engine, ect. In the case of the Vision Accelerator hardware on Xavier, a library will be added to the next JetPack release which interfaces to it as well, and includes support for hardware-accelerated stereo disparity depth mapping.
I’m sorry, but it still doesn’t answer my question. Please, let forget about the software libraries or drivers. I understand that point. My question is hardware related.
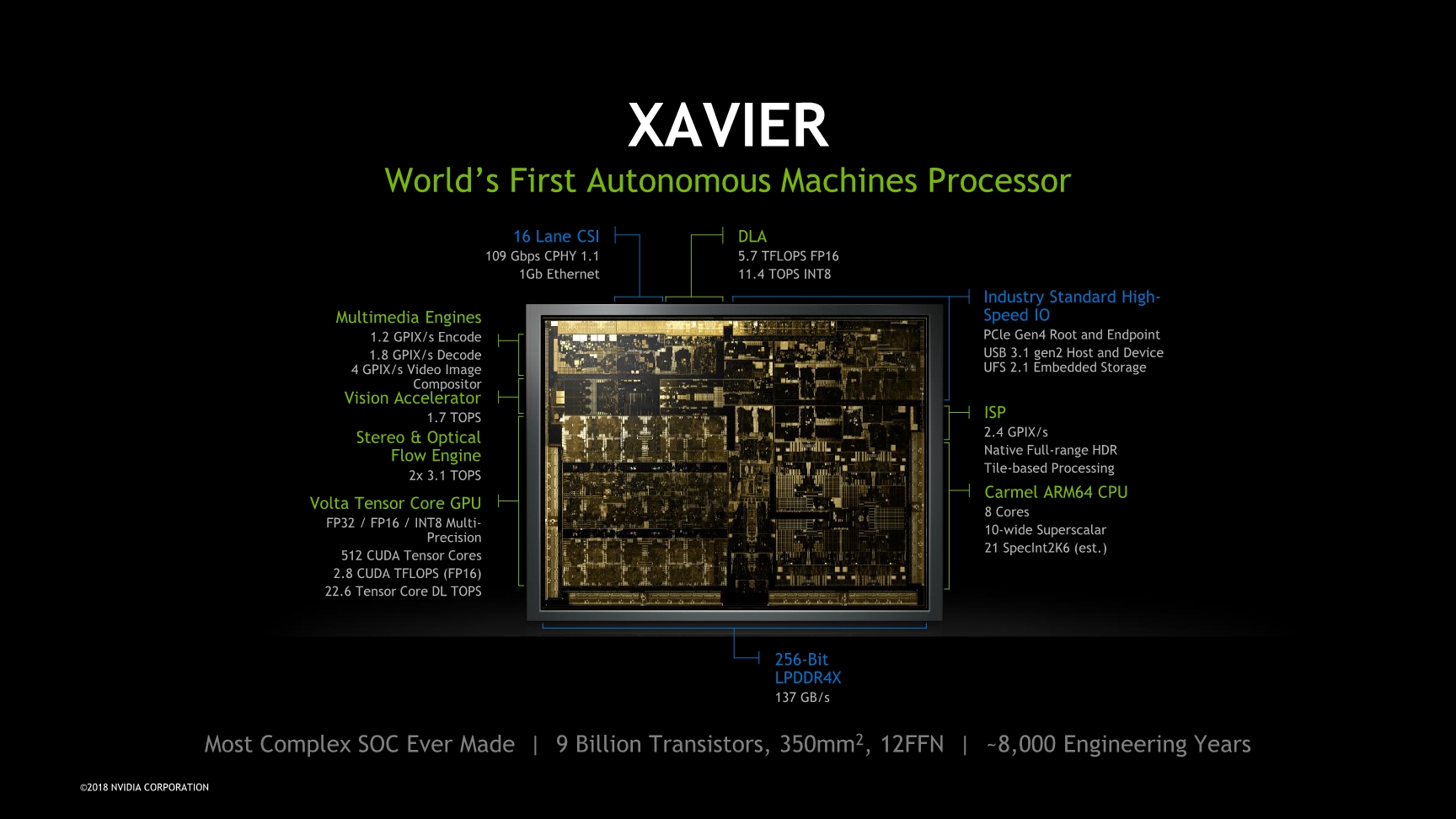
Vision Accelerator (sometimes referred as PSA) with mentioned performance 1.7 TOPS.
Stereo and Optical flow engine (sometimes referred as SOFE) with mentioned performance 2x3.1TOPS.
In my question, I don’t ask about the “PSA - Vision Accelerator” (although I believe Stereo vision algorithm can be implemented with this accelerator as well and we can call it “hardware accelerated”).
I’m asking about the “SOFE - Stereo and Optical flow engine”. Based on that picture, my understanding is that the SOFE is some hardwired/fixed functional accelerator dedicated for Stereo vision and Optical flow ONLY. So PSA and SOFE are two different HW IPs.
So, is there really IP like that in Xavier AGX SoC?
These have not been explicitly advertised as separate HW units in Jetson AGX Xavier, and they would all fall under the guise of vision accelerators which are not exposed directly to the user but through the software APIs. In the upcoming software libraries, the appropriate hardware engine would be used automatically depending on the algorithm, so you wouldn’t need to worry about it.
Thank you for your answer, Dusty_nv. I understand.
Please, I have an additional question regarding the software API.
Which software library will be used to program these vision accelerators? I’m wondering if users can use some lower-level API (something like CUDA) to optimize their algorithms or there will be a higher level API only (like OpenVX)?
Can I theoretically implement an arbitrary algorithm for these vision accelerators (for example if I want to use my own stereo vision algorithm and not the predefined one)?
I’m sorry for too many questions, I just would like to know if the new accelerators can be used as a replacement of GPUs (or to offload GPU) as a fully programmable architecture or it will be dedicated for a few tasks only.
{kind=link}
![https://images.anandtech.com/doci/13584/1.12_NVIDIA_XavierHotchips2018Final_8144.jpg[/url]](https://images.anandtech.com/doci/13584/1.12_NVIDIA_XavierHotchips2018Final_8144.jpg%5B/url%5D){kind=link}