Hi,
You can find it from trt_inference.cpp.
/home/nvidia/tegra_multimedia_api/samples/common/algorithm/trt/trt_inference.cpp
Hi,
You can find it from trt_inference.cpp.
/home/nvidia/tegra_multimedia_api/samples/common/algorithm/trt/trt_inference.cpp
Hi,
I haven’t any variable in my Nano called gieMoelStream/caffeToGIEModel, please see attachment
I know serialize and deserialize can save much time, but i don’t know how to use it in detail
Over 5 minutes are costed to deploy our DenseNet121, please give a applicable solution ASAP
Hi,
/home/nvidia/tegra_multimedia_api/samples/common/algorithm/trt/trt_inference.cpp
There are some examples in file trt_inference.cpp.
Hi Alan,
I have tried as the sample shows, but it encounters errors, after building the engine, segmentation fault comes, please help to check the serialize and deserialize flow as attached picture shows
Hi, hi-bigcat
Pls try to follow the code below. It shows how to use the TRT inference API. It contains all the workflow to work with tensorRT.
GoogleNet samples working with TRT API:
/home/nvidia/tegra_multimedia_api/samples/backend/v4l2_backend_main.cpp
Another sample working with decoder and TRT API:
/home/nvidia/tegra_multimedia_api/samples/04_video_dec_trt/video_dec_trt_main.cpp
Hi,
I have checked these two file, but haven’t found serialize and deserialize steps.
I have followed the steps you shows to me earlier in trt_inference.cpp and build the tensorRT engine with serialize step and deserialize step , but as said in my previous reply, after the engine is build, segmentation fault comes, and want you help to check whether the flow has some mistakes. I have tried many things and still can not solve it
Currently, this issue has block us move forward, we need solve it immediately.
Hi,
Here is a sample for OpenCV source with serializer/deserializer:
#include <cuda_runtime.h>
#include <iostream>
#include <sstream>
#include <fstream>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include "NvInfer.h"
#include "NvCaffeParser.h"
#define INPUT_BLOB "data"
#define OUTPUT_BLOB "fc6"
class Logger : public nvinfer1::ILogger
{
void log(Severity severity, const char* msg) override
{
if( severity != Severity::kINFO )
std::cout << msg << std::endl;
}
} gLogger;
int main(int argc, char** argv)
{
if( argc < 5 )
{
std::cout << "Usage: " << argv[0] << " [prototxt] [caffemodel] [PLAN] [image]" << std::endl;
exit(-1);
}
std::ifstream cache( argv[3] );
std::stringstream modelStream;
modelStream.seekg(0, modelStream.beg);
// caffe -> PLAN
if( !cache )
{
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(gLogger);
nvinfer1::INetworkDefinition* network = builder->createNetwork();
nvcaffeparser1::ICaffeParser* parser = nvcaffeparser1::createCaffeParser();
const nvcaffeparser1::IBlobNameToTensor* blobNameToTensor = parser->parse(argv[1], argv[2], *network, nvinfer1::DataType::kFLOAT);
nvinfer1::ITensor* output = blobNameToTensor->find(OUTPUT_BLOB);
network->markOutput(*output);
builder->setMaxBatchSize(1);
builder->setMaxWorkspaceSize((16 << 20));
nvinfer1::ICudaEngine* engine = builder->buildCudaEngine(*network);
nvinfer1::IHostMemory* serializer = engine->serialize();
modelStream.write((const char*)serializer->data(), serializer->size());
std::ofstream output_obj;
output_obj.open(argv[3]);
output_obj << modelStream.rdbuf();
output_obj.close();
network->destroy();
parser->destroy();
engine->destroy();
builder->destroy();
modelStream.seekg(0, modelStream.beg);
}
else
{
modelStream << cache.rdbuf();
cache.close();
}
// PLAN -> engine
modelStream.seekg(0, std::ios::end);
const int size = modelStream.tellg();
modelStream.seekg(0, std::ios::beg);
void* mem = malloc(size);
modelStream.read((char*)mem, size);
nvinfer1::IRuntime* infer = nvinfer1::createInferRuntime(gLogger);
nvinfer1::ICudaEngine* engine = infer->deserializeCudaEngine(mem, size, NULL);
nvinfer1::IExecutionContext* context = engine->createExecutionContext();
free(mem);
// buffers
float* input_data;
float* output_data;
nvinfer1::Dims inputDims = engine->getBindingDimensions(engine->getBindingIndex( INPUT_BLOB));
nvinfer1::Dims outputDims = engine->getBindingDimensions(engine->getBindingIndex(OUTPUT_BLOB));
cudaMallocManaged( &input_data, inputDims.d[0]* inputDims.d[1]* inputDims.d[2]*sizeof(float));
cudaMallocManaged(&output_data, outputDims.d[0]*outputDims.d[1]*outputDims.d[2]*sizeof(float));
std::cout << INPUT_BLOB <<": ("<< inputDims.d[0] <<","<< inputDims.d[1] <<","<< inputDims.d[2] <<")"<<std::endl;
std::cout <<OUTPUT_BLOB <<": ("<<outputDims.d[0] <<","<<outputDims.d[1] <<","<<outputDims.d[2] <<")"<<std::endl;
// inference
const clock_t begin_time = clock();
for( size_t iter=0; iter<100; iter++ )
{
// you can change here to different images, video, ...
cv::Mat image;
image = cv::imread(argv[4]);
cv::Mat resized;
cv::resize(image, resized, cv::Size(inputDims.d[2], inputDims.d[1]));
// U8+HWC -> float+CHW
size_t plane = inputDims.d[1]*inputDims.d[2];
for( size_t idx=0; idx<inputDims.d[1]*inputDims.d[2]; idx++ )
{
input_data[0*plane+idx] = float(resized.data[3*idx+0])-128;
input_data[1*plane+idx] = float(resized.data[3*idx+1])-128;
input_data[2*plane+idx] = float(resized.data[3*idx+2])-128;
}
cudaDeviceSynchronize();
void* buffers[] = { input_data, output_data };
context->execute(1, buffers);
cudaDeviceSynchronize();
for( size_t i=0; i<outputDims.d[0]; i++ )
{
if( output_data[i] > 0.01f )
std::cout << "iter=" << iter << " index=" << i << ": " << output_data[i] << std::endl;
}
}
std::cout << "Inference time: " << float( clock()-begin_time)/CLOCKS_PER_SEC/100 << " per image" << std::endl;
return 0;
}
Please compile it and execute with this command:
$ nvcc -o main -std=c++11 -lnvinfer -lnvparsers -lopencv_core -lopencv_imgproc -lopencv_imgcodecs topic_1049958.cpp
$ ./main [prototxt] [caffemodel] [PLAN] [image]
* 1st Run
* From 2nd Run
You may need to update the prep-rocessing steps here based on your training environment:
for( size_t idx=0; idx<inputDims.d[1]*inputDims.d[2]; idx++ )
{
input_data[0*plane+idx] = float(resized.data[3*idx+0])-128;
input_data[1*plane+idx] = float(resized.data[3*idx+1])-128;
input_data[2*plane+idx] = float(resized.data[3*idx+2])-128;
}
Nano can reach 0.095443 per image for Densenet-121.
Including READ image → Inference → Parse Output.
Thanks.
Hi Aasta,
It’s a clear sample, I am re-developing our case according to this sample.
Can you explain the ARGV[3], namely PLAN, really means? and give us a real instance of the PLAN ?
Thanks very much
Hi,
It is a TensorRT serialized filename.
For the 1st run, we serialize TensorRT engine to the filename.
From 2nd run, we deserialize TensorRT engine from the filename.
Thanks.
Hi AastaLLL,
I have tried following your sample, but still have errors just after serialize finished like attached pictures show, attach part of codes here for checking(try.cpp).
Please help to check, and hope to solve it today
try.cpp (5.09 KB)
Hi,
What is your error message.
It looks like the error occurs in std::cout.
Hi,
I have re-attached the pictures with error information, please check it in previous reply
Hi,
Could you check if you are running out of stack space?
The error address looks like a stack address.
Do you run multiple models at the same time?
If yes, are they using a different app or just threading?
If you are using threading, this looks like a similar issue and recommended to check the solution first:
[url]Segmentation fault with ray 0.6.0 and PyTorch 0.4.1 and 1.0.0 · Issue #3520 · ray-project/ray · GitHub
Thanks.
Hi,
I am just running one models.
The thing is that without using serializing and deserializing the application with the model can be run successfully costing about 5 minutes, while with using serializing and deserializing, the application stops just at the end of serializing.
So I am wondering whether the serializing step is right in my application on the Nano board
Hi,
Have you tried the source in comment #27?
Does it also meet the same issue?
It looks like the error occurs from stack overflow.
Maybe some data structure can be optimized inside your source.
Thanks.
Hi,
I just follow the sample in comment #27, but the buffer operations cannot be directly followed as the sample, since we need modify many functions, so i use other buffer operations as other samples show in Nano.
So, has serializing/de-serializing ever been run successfully in Nano in other projects?
Hi,
Comment #27 works well on our environment and so as other users.
This issue is stack overflow so you will need to check your implementation.
It looks like you haven’t tried our implementation.
A possible workaround is to use our code to save the PLAN directly.
So you just need a deserializer in your application.
Thanks.
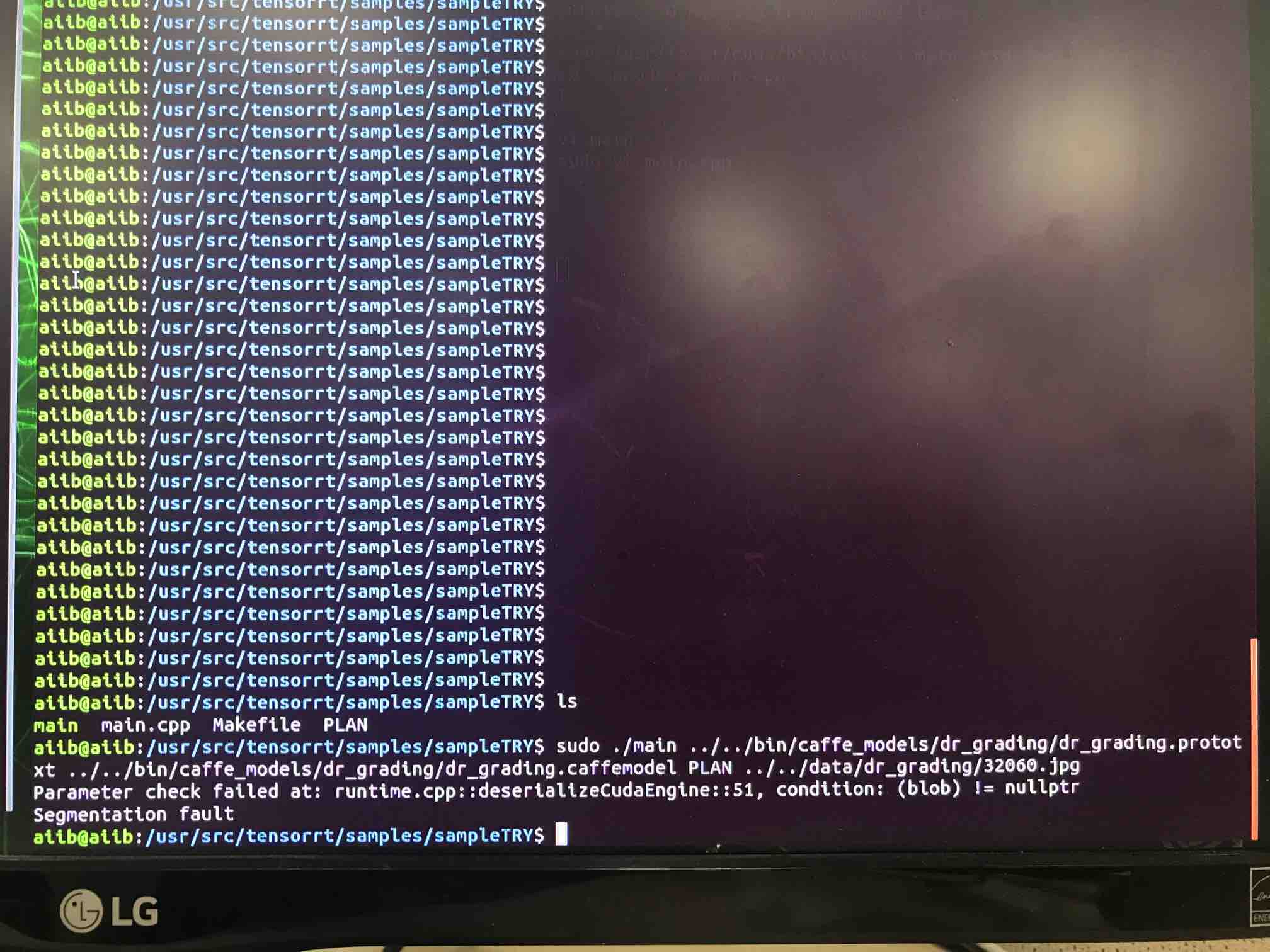
Hi,
It looks like your PLAN file is broken. Maybe you can check the status of memory/storage?
To give a further suggestion, could you attach the dr_grading.prototxt/dr_grading.caffemodel/PLAN file with us?
Thanks.
Hi,
Could you give us a PLAN file for reference now?
I just create an empty file and rename it to PLAN.
The caffemodle cannot be shared now, hope you can understand