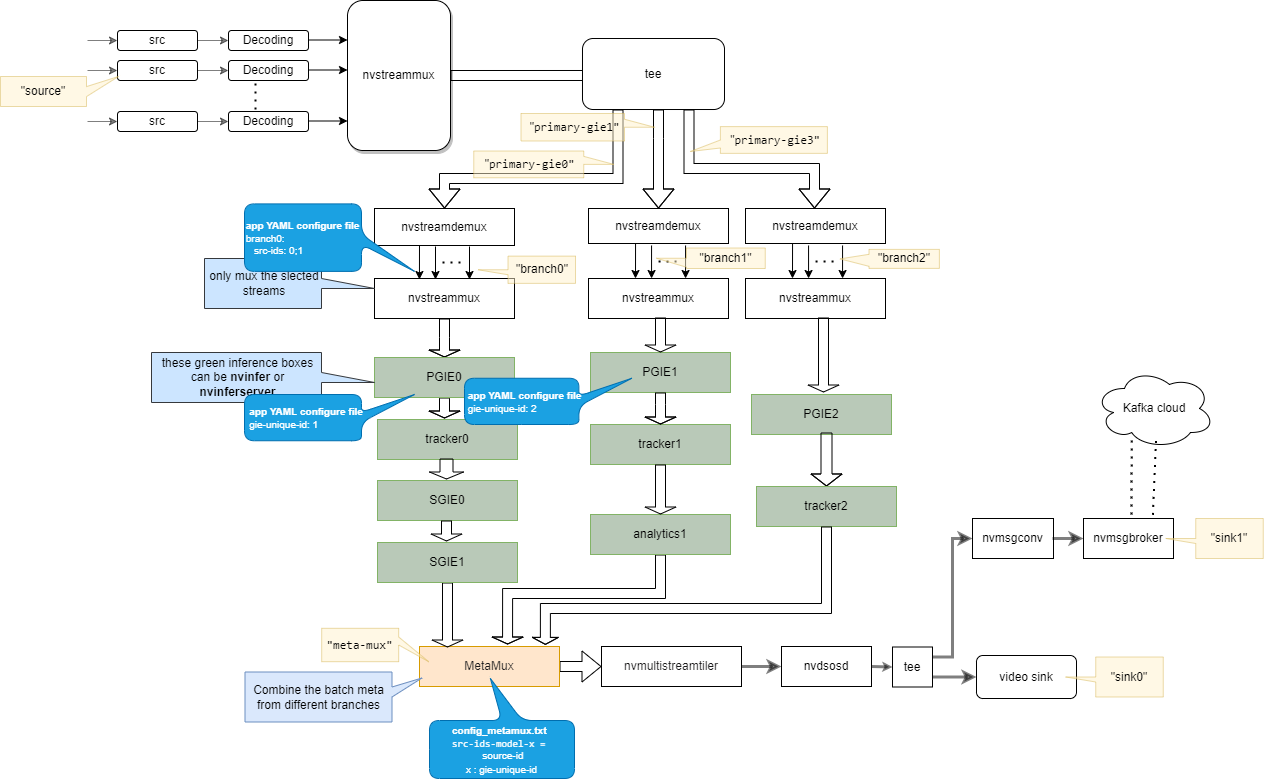
When I refer to deepstream_parallel_inference_app, I see that the app only support multiple models inference with nvinfer(TensorRT) or nvinferserver(Triton) in parallel. So, I have idea to inference multiple models with nvinfer and nvinferaudio in parallel. I want to use gst-nvdsmetamux (MetaMux in the below image) to mux output meta from audio model and video model, Is it possible? I know that NvDsAudioFrameMeta used to store metadata of audio and NvDsFrameMeta used to store metadata of video.
Thank you very much.
• Hardware Platform (Jetson / GPU) Jetson NX Xavier
• DeepStream Version 6.3
• JetPack Version (valid for Jetson only) 5.1.2
• TensorRT Version 8.5
• Issue Type (questions, new requirements, bugs) questions