Hi
We use nano demo kit and running cude but find HDMI output was flicker.
our test setp:
1. install phoronix-test-suite_9.4
2. Open terminal and use “export TOTAL_LOOP_TIME=99999999999999999999”
3. Run “phoronix-test-suite stress-run pts/cuda-mini-nbody”
Follow your steps to run stress, but got below errors:
$ phoronix-test-suite stress-run pts/cuda-mini-nbody
STRESS-RUN ENVIRONMENT VARIABLES:
PTS_CONCURRENT_TEST_RUNS: Set the PTS_CONCURRENT_TEST_RUNS environment variable to specify how many tests should be run concurrently during the stress-run process. If not specified, defaults to 2.
TOTAL_LOOP_TIME set; running tests for 99999999999999999999 minutes
[PROBLEM] pts/cuda-mini-nbody-1.1.1 is not installed.
We don’t have experience of using cuda-mini-nbody on Jetson platforms.
Please share how can we install it. Thanks!
PTS_CONCURRENT_TEST_RUNS: Set the PTS_CONCURRENT_TEST_RUNS environment variable to specify how many tests should be run concurrently during the stress-run process. If not specified, defaults to 2.
TOTAL_LOOP_TIME set; running tests for 99999999999999999999 minutes
CUDA Mini-Nbody 2015-11-10:
pts/cuda-mini-nbody-1.1.1
Graphics Test Configuration
1: Original
2: SOA Data Layout
3: Flush Denormals To Zero
4: Cache Blocking
5: Loop Unrolling
6: Test All Options
** Multiple items can be selected, delimit by a comma. **
I select item 6 (Test All Options), running about 1 hour, I don’t see HDMI flicker issue.
Are you enable max performance mode before running?
$ sudo nvpmodel -m 0 ;
$ sudo jetson_clocks
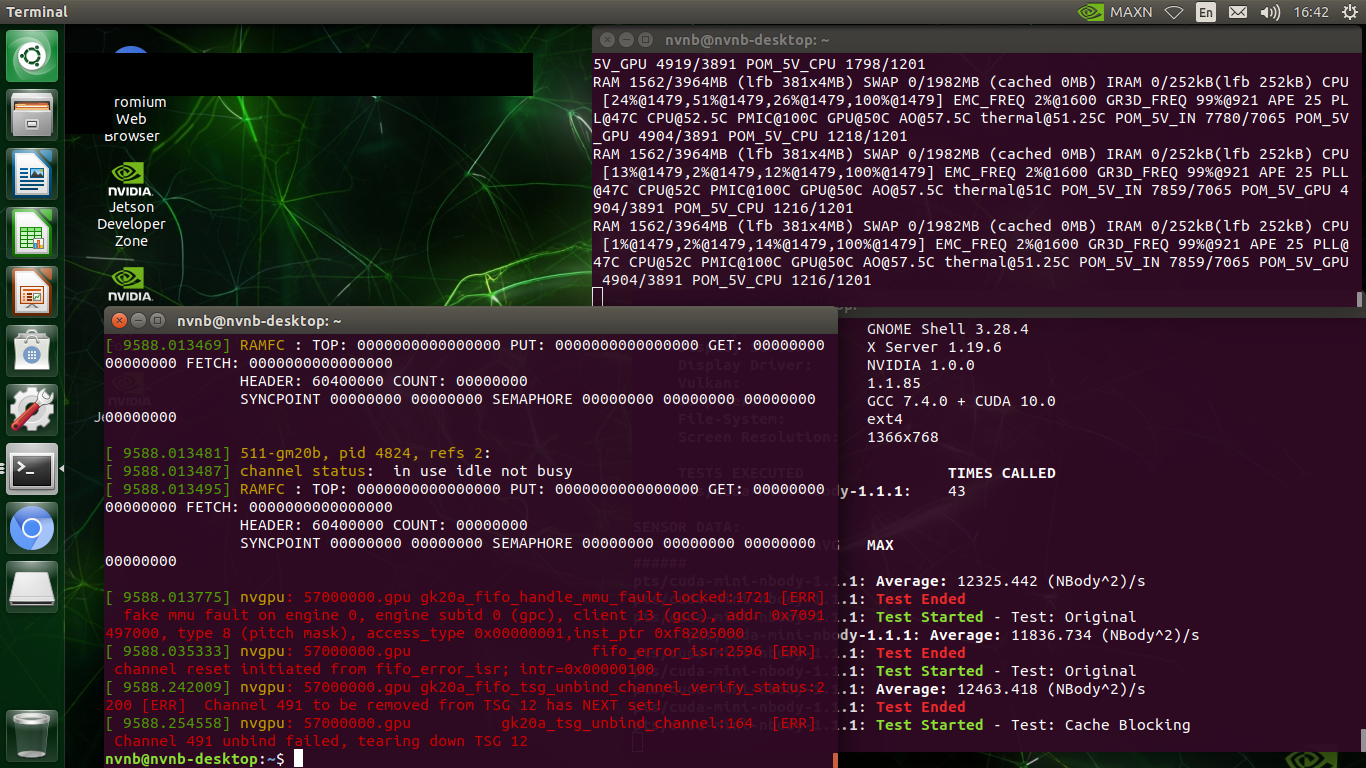
Please share your tegrastats when you run this test.
Also, which release are you using? Do you use sdcard image or sdkmanager?
Can you reproduce this issue on more than 2 jetson nano modules?
Please share your tegrastats when you run this test.
–>update test reilt .
Also, which release are you using?
–>We use Jatpack 4.3(R32.3.1)
Do you use sdcard image or sdkmanager?
–>We tested SDcard version on demo kit and use our carried board (use eMMC Nano) and same issue was happen.
Can you reproduce this issue on more than 2 jetson nano modules?
–>We had test three nano module and find same issue.
We can see the black line on your screenshot. But could you share the tegrastats as a file instead of a picture?
Please always share the log as text file instead of picture unless you cannot share it as text.
Also, does this always need to run 1~2 days to see the issue?
This week , we had run again of Nano demo kit(SD card version) on CUDE loading.
The flicker was happen and system was hand up (ex: keyboard and mouser not working) , We had unplug power adapter and plug in to open system .
Our test config.:
1. use MAXIM performanace.
2. use 25 temp .
3. run CUDE loading.
4. use Nano demo kit on SD card version.
Use 25 temperature mean room temperature.
Run CUDE loading =install phoronix-test-suite and keep "phoronix-test-suite stress-run pts/cuda-mini-nbody" to ruuning .
Hi HuiW,
Thanks for sharing the log. We are trying to reproduce this issue again.
According to the video file in your mail, I notice you are using the terminal on screen but our test was on remote access with ssh. The tegrastats lines showing up on your screen is causing more gpu rendering in your case than ours. I guess that is the reason we didn’t reproduce error.
To make this bug more clear, it is a rendering issue when gpu is under stress test (99%).
We had try to run CPU load and same issue happen.
CPU loading command: 1.export TOTAL_LOOP_TIME=99999999999999999999
2. phoronix-test-suite stress-run pts/stress-ng