I’ve implemented parallel scheduling logic in my custom AI compiler that identifies parallelizable IR sections and assigns them to different CUDA streams for concurrent execution. While I do observe kernel overlap, the nsys timeline shows kernels aren’t tightly packed with visible idle gaps, and some short-duration kernels that should run in parallel are actually executing serially.
(Kernel Execution Status Excerpt)
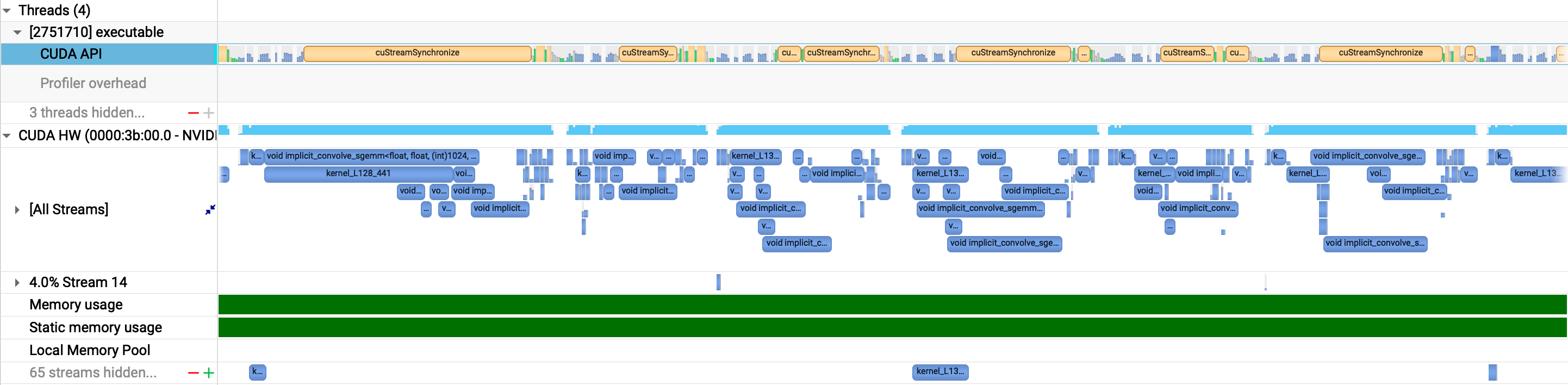
(Kernel Execution Status Within a Certain Parallel Group)

My implementation uses multiple streams for parallel execution groups, with kernels typically having sub-millisecond execution times. I’ve already implemented stream pool and handle pool logic to avoid repeatedly creating and destroying streams and handles during kernel execution, but scheduling gaps still persist.
Concerning performance: Based on my actual testing, the execution efficiency of my custom compiler with parallel scheduling is still lower than PyTorch’s single default stream execution, which suggests fundamental issues with my scheduling approach.(Although my approach is inherently worse than PyTorch in terms of individual kernel execution time, with an average difference of 1-2x, I believe I should be able to offset this gap through parallel execution and should even be able to perform better than it.)
I have three main questions:
First, how can I make kernels within the same parallel group or across different parallel groups execute with tighter coupling? I’m looking for techniques to minimize the gaps between kernel executions and achieve more seamless transitions.
Second, since I’m calling cuDNN and cuBLAS library functions for some operators, these highly optimized libraries generate many short-duration small kernels as observed in nsys. Is there any way to perform kernel fusion on these predefined cuDNN/cuBLAS API functions, or achieve operator fusion at this level?
Third, is there any approach to optimize cuDNN and cuBLAS API execution efficiency without relying on runtime profiling? I understand that cuDNN’s convolution APIs use algorithm auto-tuning that requires actual execution to determine the optimal algorithm at runtime. This runtime algorithm selection process introduces overhead that interferes with parallel scheduling efficiency. Are there ways to pre-determine or cache optimal algorithms to avoid this runtime overhead?
Of course, if there are other possible issues that could cause the situation described above, I welcome your suggestions as well.
I would greatly appreciate any insights and suggestions from the community to help solve these challenges.