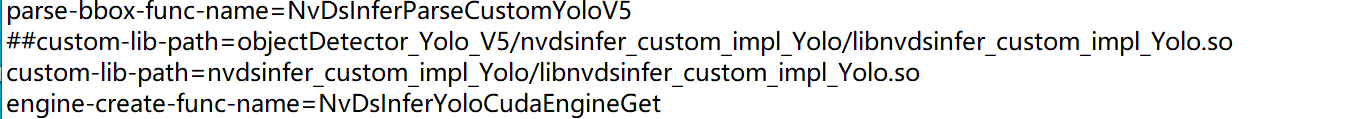Please provide complete information as applicable to your setup.
**• Hardware Platform (Jetson / GPU)**Jetson NX
• DeepStream Version5.0
**• JetPack Version (valid for Jetson only)**4.4
• TensorRT Version7.1.0
• NVIDIA GPU Driver Version (valid for GPU only)
• Issue Type( questions, new requirements, bugs)
How to use DLA in the deepstream-yolov5 configuration file.
What do I need to add to the configuration file to use DLA?
• How to reproduce the issue ? (This is for bugs. Including which sample app is using, the configuration files content, the command line used and other details for reproducing)
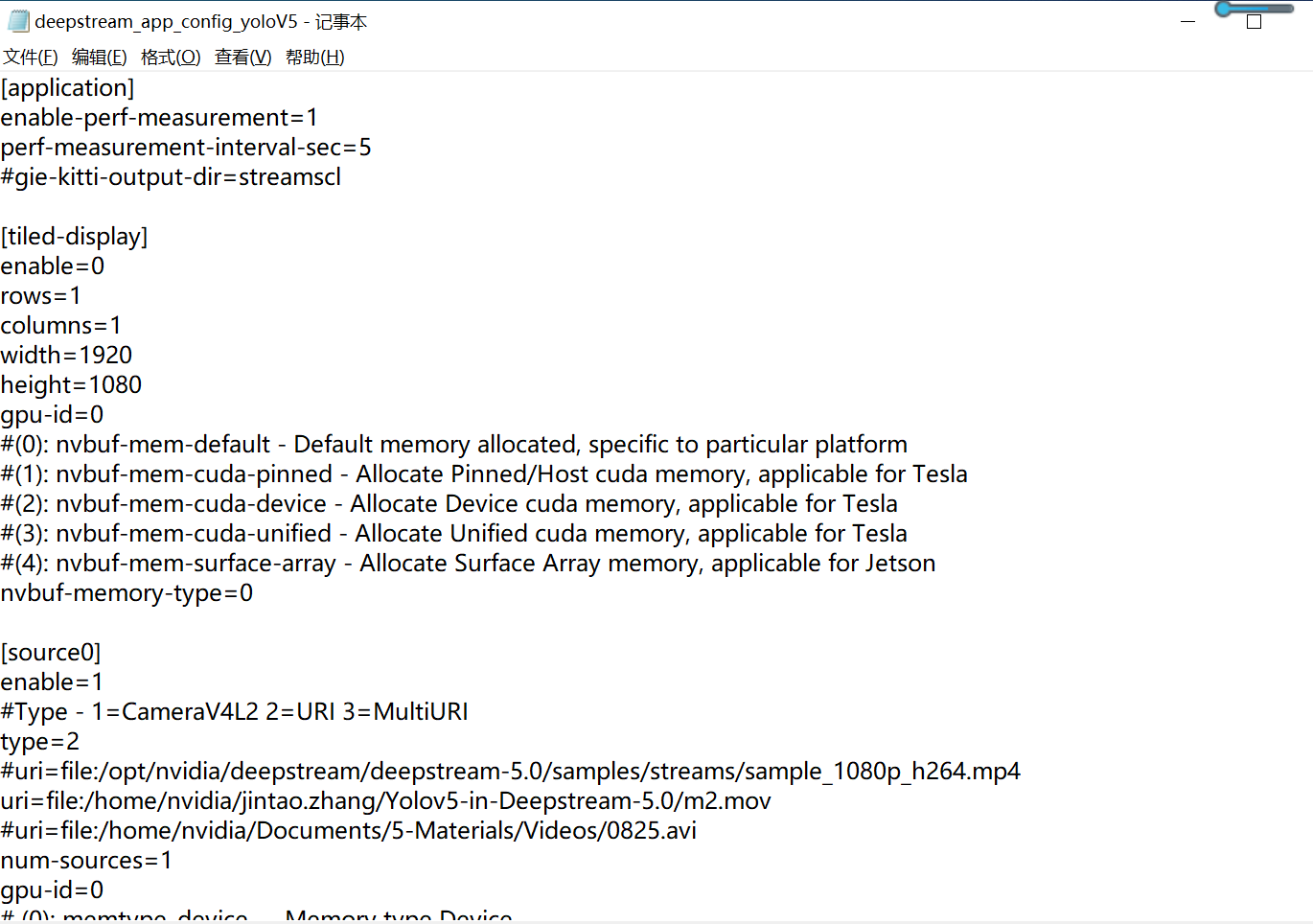
LD_PRELOAD=./libmyplugins.so deepstream-app -c deepstream_app_config_yoloV5.txt
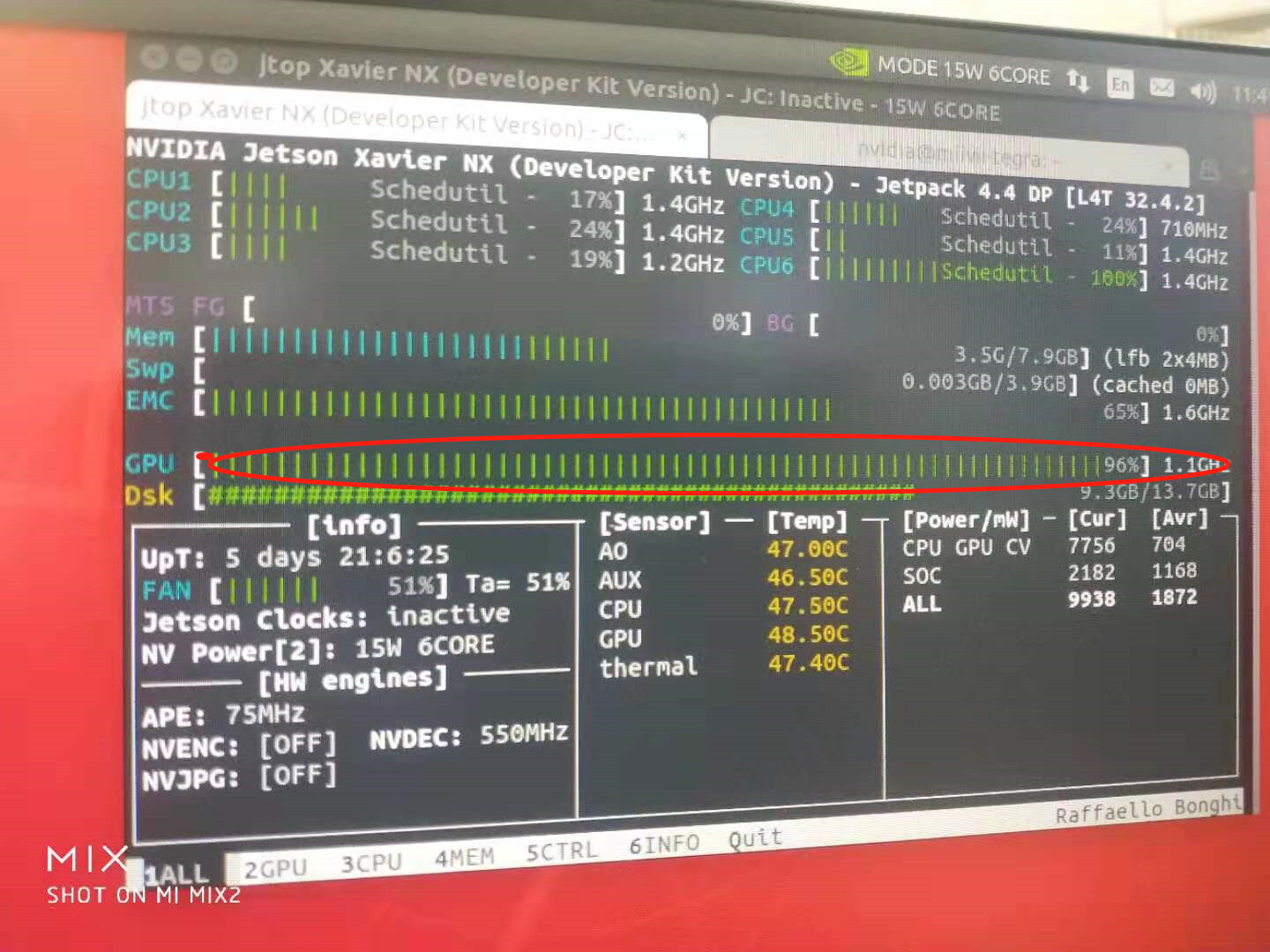
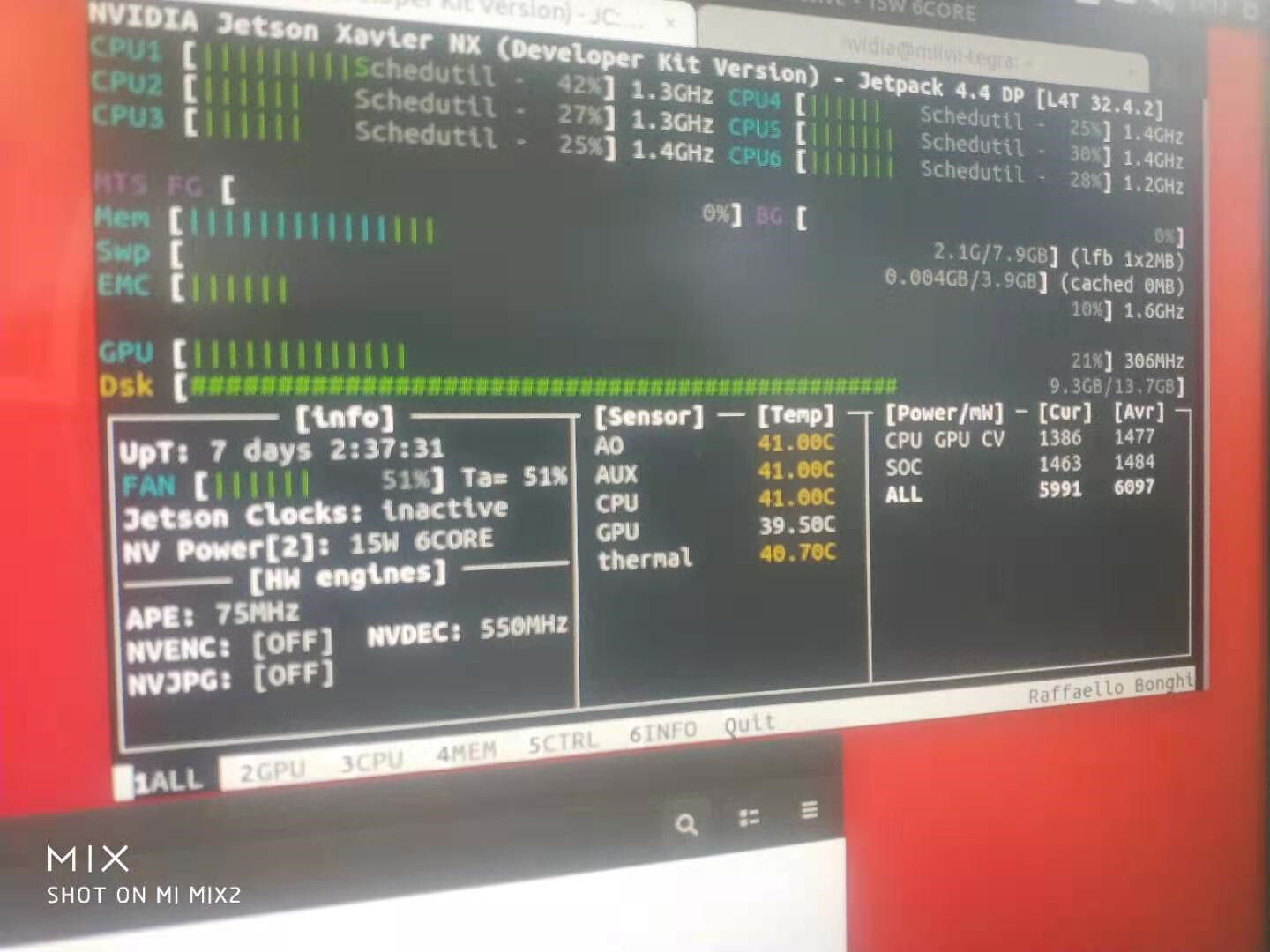
GPU utilization is still close to 100% after I run.
• Requirement details( This is for new requirement. Including the module name-for which plugin or for which sample application, the function description)
Hi,
Please add the below configure to enable DLA inference:
enable-dla=1
use-dla-core=0
But please noted that you would need to remove the serialized engine file first.
Or Deepstream will reuse it instead of recreating.
Thanks.
There are two configuration files in total. I added the configuration in config_infer_primary_yoloV5.txt (as shown in the figure above), but DLA is not running. When I added the configuration in deepstream_app_dla_config_yoloV5.txt, it reports error. Do you mean I need to delete the original yolov5m.engine and regenerate the yolov5m.engine?
I added
enable-dla=1
use-dla-core=0
to the configuration file and regenerated the .engine file, but it is still running on the GPU.
Hi,
Do you generate the yolov5m.engine with DLA?
This can be found in the Deepstream console log.
If you are not sure about this, would you mind attaching the log with us?
Thanks.
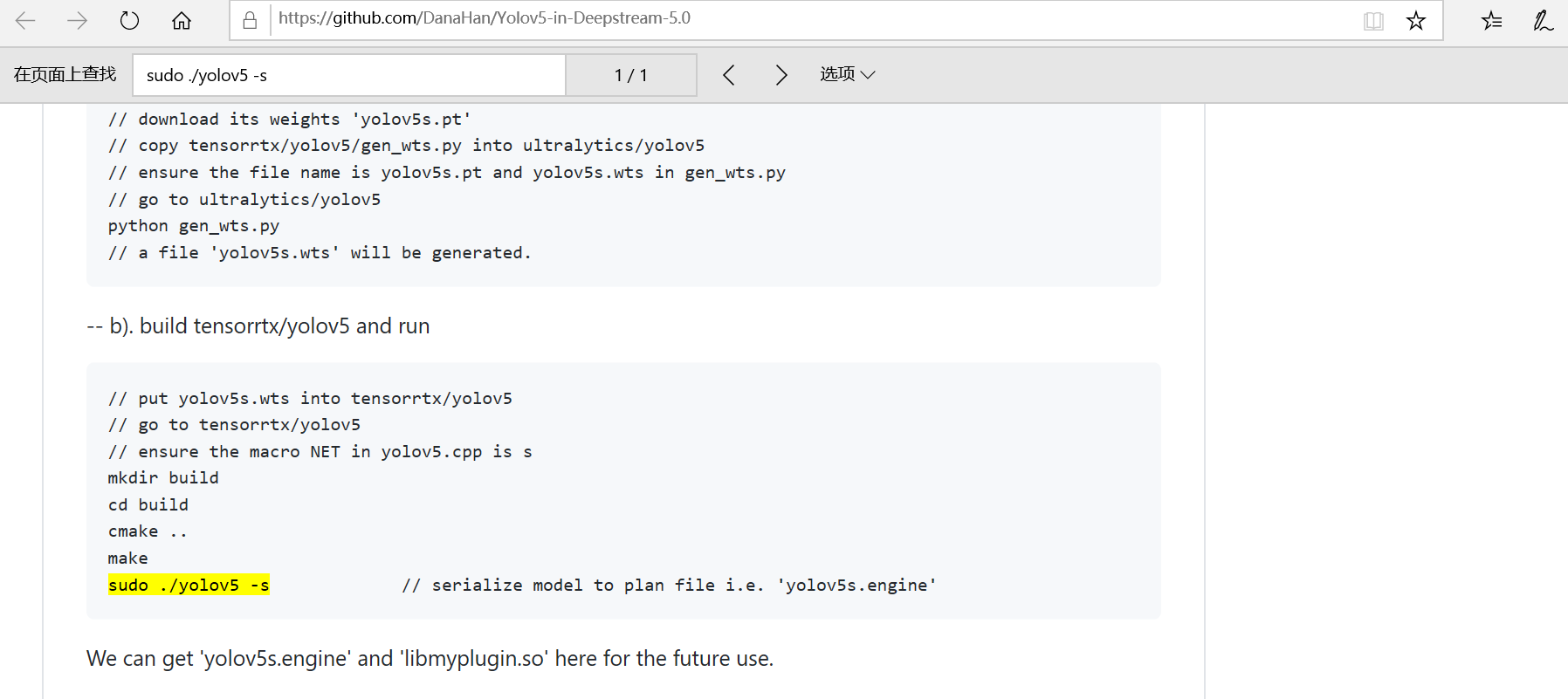
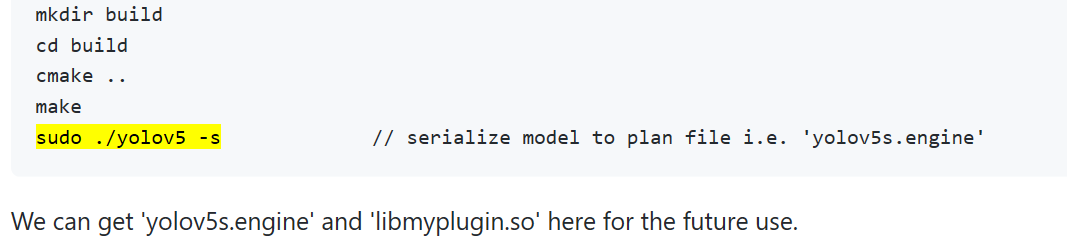
Hi,I use the command of the official website tutorial to generate .ENGINE as follows:
Below are the instructions used to generate .engine.
Hi,
It seems that you have your customized plugin.
To add the plugin library into Deepstream, please update the path to the custom-lib-path.
For example: config_infer_primary_yoloV3.txt
[property]
...
custom-lib-path=nvdsinfer_custom_impl_Yolo/libnvdsinfer_custom_impl_Yolo.so
engine-create-func-name=NvDsInferYoloCudaEngineGet
...
Thanks.
Thanks, I have update the path to the
custom-lib-path, but it still filled, it still used GPU not DLA.
The following is the file path of my custom yolov5 model.
Hi,
May I know how do you check the inference is using GPU rather than DLA?
If you verify this with tegrastats, it is not accurate since other components can also raise the utilization.
Would you mind using nsight system to monitor the pipeline?
Thanks.
When I use deepstream to run, the GPU occupancy suddenly changes from 0% to 97,98%. So it still runs on GPU.
Hi,
Could you turn it on and off to confirm if the GPU is occupied by primary-gie or not?
[primary-gie]
enable=0
If the yolov5 detector occupies most GPU resources, please share the detailed source and model with us to reproduce.
Thanks.
I think it may indeed be because of primary-gie.
Hi,
Would you mind sharing your configure file and model for us to check?
Thanks.
The following is the configure file. The model file belongs to our company’s secrets. Sorry I can’t give it to you, but it is also a model produced by training using the official yolov5 GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite.
config_infer_primary_yoloV5.txt (2.3 KB) deepstream_app_dla_config_yoloV5.txt (2.5 KB)
Hi,
Thanks for your sharing.
Suppose we can reproduce this issue with the official YOLOv5. It this correct?
Thanks.
Hi
Yes, It is right.
Thanks.
Hello,
For the official yolov5s.pt file, the same problem still occurs. The .pt file generated by our training is also a .pt file, so I think the model should be no problem. Compared with the official model, our model only has a different weight value.
Hi,
Sorry for the late update.
Please noted that TensorRT chooses the inference algorithms at building time.
This mechanism indicates that if an engine is optimized for GPU, you can’t change it for DLA afterward.
Based on the above configure, the serialized engine is generated by an external GitHub rather than Deepstream itself.
So please check if the GitHub generates a DLA-based TensorRT engine or not first.
Thanks.