GPU: Quadro RTX 4000
CUDA: 11.7
For simple test case like:
__global__ void test(float *a, float *b, float *c, const int n) {
unsigned int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n) {
c[idx] = a[idx] + b[idx];
}
}
Memory Chart:
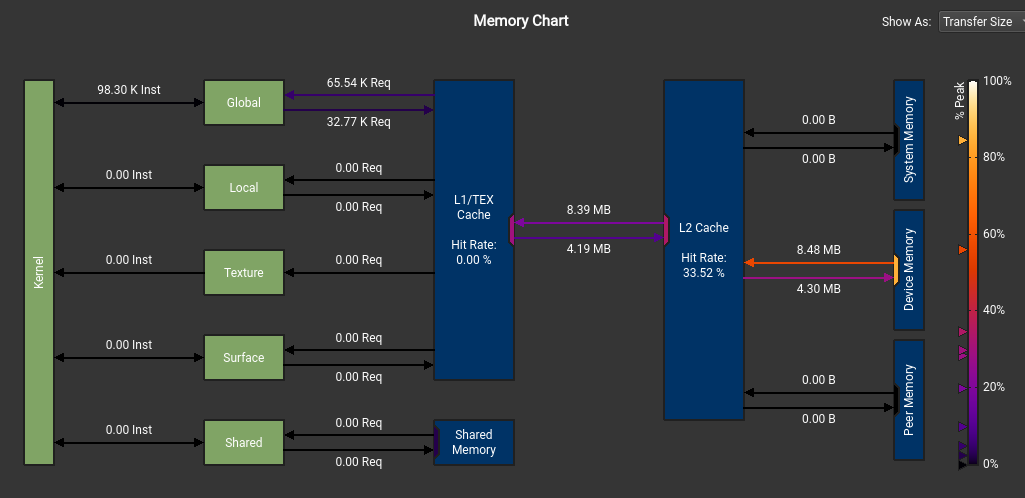
Why L2 hit is not 0%? What type of data had been cached? Who decides this part of data was to be cached?
Thank you.