I am trying to build libnvinfer plugin version 8.0.1 for using with JetPack 4.6 on Nano. I tried to follow the steps written here:
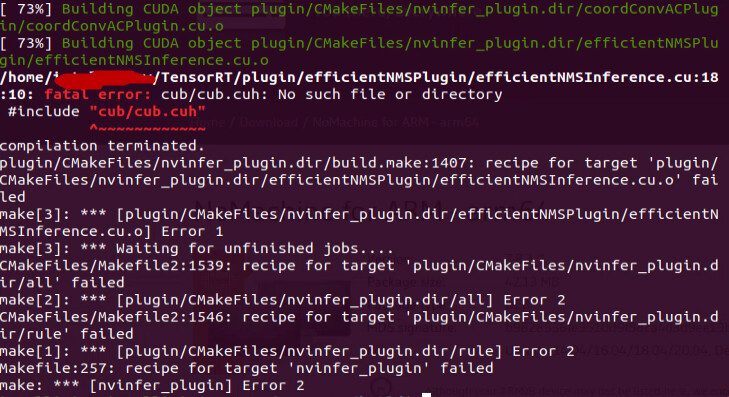
I could successfully build and install CMake following step1. But when I tried to follow step 2, upon issuing the command “$ make nvinfer_plugin -j$(nproc)” I get the following error:
I am having all sorts of trouble. Nothing is really working for me. I tried the same for older jetpack when I build plugin version 7.1.3. Everything went smoothly. Now with 8.0.1 I neither can build it on x86 nor on Jetson Nano.
Ok, I am now trying from scratch. I have freshly install ubuntu 18.04.
Installed Cuda toolkit 11.3 (cuda-repo-ubuntu1804-11-3-local_11.3.0-465.19.01-1_amd64.deb) which came with Nvidia driver version 465 following the steps described in CUDA Toolkit 11.3 Downloads | NVIDIA Developer
Then I install Tensor RT version 8.0.1 (TensorRT 8.0.1 GA for Ubuntu 18.04 and CUDA 11.3 DEB local repo package] (Log in | NVIDIA Developer)
After that I tried to build TensorRT OSS plugin from source code (deepstream_tao_apps/TRT-OSS/x86 at master · NVIDIA-AI-IOT/deepstream_tao_apps · GitHub). As described in this link, I first compiled and install CMAKE 3.19.4. and then tried to build TensorRT OSS Plugin (6.0 GA TRT 8.0.1 release/8.0). However, I am having trouble when I execute $ $HOME/install/bin/cmake .. -DTRT_LIB_DIR=/usr/lib/x86_64-linux-gnu/ -DCMAKE_C_COMPILER=/usr/bin/gcc -DTRT_BIN_DIR=pwd/out
Below is the output in the terminal:
Building for TensorRT version: 8.0.1, library version: 8
– The CXX compiler identification is GNU 7.5.0
– The CUDA compiler identification is NVIDIA 11.3.58
– Detecting CXX compiler ABI info
– Detecting CXX compiler ABI info - done
– Check for working CXX compiler: /usr/bin/g++ - skipped
– Detecting CXX compile features
– Detecting CXX compile features - done
– Detecting CUDA compiler ABI info
– Detecting CUDA compiler ABI info - done
– Check for working CUDA compiler: /usr/local/cuda/bin/nvcc - skipped
– Detecting CUDA compile features
– Detecting CUDA compile features - done
– Targeting TRT Platform: x86_64
– CUDA version set to 11.3.1
– cuDNN version set to 8.2
– Protobuf version set to 3.0.0
– Looking for C++ include pthread.h
– Looking for C++ include pthread.h - found
– Performing Test CMAKE_HAVE_LIBC_PTHREAD
– Performing Test CMAKE_HAVE_LIBC_PTHREAD - Failed
– Looking for pthread_create in pthreads
– Looking for pthread_create in pthreads - not found
– Looking for pthread_create in pthread
– Looking for pthread_create in pthread - found
– Found Threads: TRUE
– Found PkgConfig: /usr/bin/pkg-config (found version “0.29.1”)
– Checking for one of the modules ‘zlib’
CMake Error at /home/ashiq/install/share/cmake-3.19/Modules/FindPkgConfig.cmake:805 (message):
None of the required ‘zlib’ found
Call Stack (most recent call first):
third_party/zlib.cmake:18 (pkg_search_module)
CMakeLists.txt:98 (include)
– Found CUDA: /usr/local/cuda (found suitable version “11.3.1”, minimum required is “11.3.1”)
– Using libprotobuf /home/ashiq/TensorRT/build/third_party.protobuf/lib/libprotobuf.a
– ========================= Importing and creating target nvinfer ==========================
– Looking for library nvinfer
– Library that was found /usr/lib/x86_64-linux-gnu/libnvinfer.so
– ==========================================================================================
– ========================= Importing and creating target nvuffparser ==========================
– Looking for library nvparsers
– Library that was found /usr/lib/x86_64-linux-gnu/libnvparsers.so
– ==========================================================================================
– GPU_ARCHS is not defined. Generating CUDA code for default SMs: 35;53;61;70;75;80
– Protobuf proto/trtcaffe.proto → proto/trtcaffe.pb.cc proto/trtcaffe.pb.h
– /home/ashiq/TensorRT/build/parsers/caffe
– The C compiler identification is GNU 7.5.0
– Detecting C compiler ABI info
– Detecting C compiler ABI info - done
– Check for working C compiler: /usr/bin/gcc - skipped
– Detecting C compile features
– Detecting C compile features - done
– Build type not set - defaulting to Release
Generated: /home/ashiq/TensorRT/build/parsers/onnx/third_party/onnx/onnx/onnx_onnx2trt_onnx-ml.proto
Generated: /home/ashiq/TensorRT/build/parsers/onnx/third_party/onnx/onnx/onnx-operators_onnx2trt_onnx-ml.proto
Generated: /home/ashiq/TensorRT/build/parsers/onnx/third_party/onnx/onnx/onnx-data_onnx2trt_onnx.proto
– ******** Summary ********
– CMake version : 3.19.4
– CMake command : /home/ashiq/install/bin/cmake
– System : Linux
– C++ compiler : /usr/bin/g++
– C++ compiler version : 7.5.0
– CXX flags : -Wno-deprecated-declarations -DBUILD_SYSTEM=cmake_oss -Wall -Wno-deprecated-declarations -Wno-unused-function -Wnon-virtual-dtor
– Build type : Release
– Compile definitions : _PROTOBUF_INSTALL_DIR=/home/ashiq/TensorRT/build;ONNX_NAMESPACE=onnx2trt_onnx
– CMAKE_PREFIX_PATH :
– CMAKE_INSTALL_PREFIX : /usr/lib/x86_64-linux-gnu/..
– CMAKE_MODULE_PATH :
– ONNX version : 1.8.0
– ONNX NAMESPACE : onnx2trt_onnx
– ONNX_BUILD_TESTS : OFF
– ONNX_BUILD_BENCHMARKS : OFF
– ONNX_USE_LITE_PROTO : OFF
– ONNXIFI_DUMMY_BACKEND : OFF
– ONNXIFI_ENABLE_EXT : OFF
– Protobuf compiler :
– Protobuf includes :
– Protobuf libraries :
– BUILD_ONNX_PYTHON : OFF
– Found TensorRT headers at /home/ashiq/TensorRT/include
– Find TensorRT libs at /usr/lib/x86_64-linux-gnu/libnvinfer.so;/usr/lib/x86_64-linux-gnu/libnvinfer_plugin.so
– Found TENSORRT: /home/ashiq/TensorRT/include
– Adding new sample: sample_algorithm_selector
– - Parsers Used: caffe
– - InferPlugin Used: OFF
– - Licensing: samples
– Adding new sample: sample_char_rnn
– - Parsers Used: uff;caffe;onnx
– - InferPlugin Used: OFF
– - Licensing: samples
– Adding new sample: sample_dynamic_reshape
– - Parsers Used: onnx
– - InferPlugin Used: OFF
– - Licensing: samples
– Adding new sample: sample_fasterRCNN
– - Parsers Used: caffe
– - InferPlugin Used: ON
– - Licensing: samples
– Adding new sample: sample_googlenet
– - Parsers Used: caffe
– - InferPlugin Used: OFF
– - Licensing: samples
– Adding new sample: sample_int8
– - Parsers Used: caffe
– - InferPlugin Used: ON
– - Licensing: samples
– Adding new sample: sample_int8_api
– - Parsers Used: onnx
– - InferPlugin Used: OFF
– - Licensing: samples
– Adding new sample: sample_mlp
– - Parsers Used: caffe
– - InferPlugin Used: OFF
– - Licensing: samples
– Adding new sample: sample_mnist
– - Parsers Used: caffe
– - InferPlugin Used: OFF
– - Licensing: samples
– Adding new sample: sample_mnist_api
– - Parsers Used: caffe
– - InferPlugin Used: OFF
– - Licensing: samples
– Adding new sample: sample_nmt
– - Parsers Used: none
– - InferPlugin Used: OFF
– - Licensing: samples
– Adding new sample: sample_onnx_mnist
– - Parsers Used: onnx
– - InferPlugin Used: OFF
– - Licensing: samples
– Adding new sample: sample_reformat_free_io
– - Parsers Used: caffe
– - InferPlugin Used: OFF
– - Licensing: samples
– Adding new sample: sample_ssd
– - Parsers Used: caffe
– - InferPlugin Used: ON
– - Licensing: samples
– Adding new sample: sample_uff_fasterRCNN
– - Parsers Used: uff
– - InferPlugin Used: ON
– - Licensing: samples
– Adding new sample: sample_uff_maskRCNN
– - Parsers Used: uff
– - InferPlugin Used: ON
– - Licensing: samples
– Adding new sample: sample_uff_mnist
– - Parsers Used: uff
– - InferPlugin Used: OFF
– - Licensing: samples
– Adding new sample: sample_uff_plugin_v2_ext
– - Parsers Used: uff
– - InferPlugin Used: OFF
– - Licensing: samples
– Adding new sample: sample_uff_ssd
– - Parsers Used: uff
– - InferPlugin Used: ON
– - Licensing: samples
– Adding new sample: sample_onnx_mnist_coord_conv_ac
– - Parsers Used: onnx
– - InferPlugin Used: ON
– - Licensing: samples
– Adding new sample: trtexec
– - Parsers Used: caffe;uff;onnx
– - InferPlugin Used: OFF
– - Licensing: samples
– Configuring incomplete, errors occurred!
See also “/home/ashiq/TensorRT/build/CMakeFiles/CMakeOutput.log”.
See also “/home/ashiq/TensorRT/build/CMakeFiles/CMakeError.log”.
And here is the CMakeError.log
Performing C++ SOURCE FILE Test CMAKE_HAVE_LIBC_PTHREAD failed with the following output:
Change Dir: /home/ashiq/TensorRT/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_285cc/fast && /usr/bin/make -f CMakeFiles/cmTC_285cc.dir/build.make CMakeFiles/cmTC_285cc.dir/build
make[1]: Entering directory ‘/home/ashiq/TensorRT/build/CMakeFiles/CMakeTmp’
Building CXX object CMakeFiles/cmTC_285cc.dir/src.cxx.o
/usr/bin/g++ -DCMAKE_HAVE_LIBC_PTHREAD -Wno-deprecated-declarations -DBUILD_SYSTEM=cmake_oss -std=c++11 -o CMakeFiles/cmTC_285cc.dir/src.cxx.o -c /home/ashiq/TensorRT/build/CMakeFiles/CMakeTmp/src.cxx
Linking CXX executable cmTC_285cc
/home/ashiq/install/bin/cmake -E cmake_link_script CMakeFiles/cmTC_285cc.dir/link.txt --verbose=1
/usr/bin/g++ -Wno-deprecated-declarations -DBUILD_SYSTEM=cmake_oss CMakeFiles/cmTC_285cc.dir/src.cxx.o -o cmTC_285cc
CMakeFiles/cmTC_285cc.dir/src.cxx.o: In function main': src.cxx:(.text+0x3e): undefined reference to pthread_create’
src.cxx:(.text+0x4a): undefined reference to pthread_detach' src.cxx:(.text+0x56): undefined reference to pthread_cancel’
src.cxx:(.text+0x67): undefined reference to pthread_join' src.cxx:(.text+0x7b): undefined reference to pthread_atfork’
collect2: error: ld returned 1 exit status
CMakeFiles/cmTC_285cc.dir/build.make:105: recipe for target ‘cmTC_285cc’ failed
make[1]: *** [cmTC_285cc] Error 1
make[1]: Leaving directory ‘/home/ashiq/TensorRT/build/CMakeFiles/CMakeTmp’
Makefile:140: recipe for target ‘cmTC_285cc/fast’ failed
make: *** [cmTC_285cc/fast] Error 2
Determining if the function pthread_create exists in the pthreads failed with the following output:
Change Dir: /home/ashiq/TensorRT/build/CMakeFiles/CMakeTmp
Just did. Same result. My ARCH is 61. I did not use it in the first place because it was already set as default. Anyway, rerunning it with “-DGPU_ARCHS=61” did not make any difference.
@Morganh , Thanks for your reply. I finally could build “libnvinfer_plugin.so.8.0.1” in x86 and build the “yolo4_1_3_416_416_static.onnx” for tiny YOLO V4. After that I added “BatchedNMSPlugin” node into the ONNX model following step 2 of section 2.3 described in GitHub - NVIDIA-AI-IOT/yolov4_deepstream in my host x86 machine. This produced the “yolo4_1_3_416_416_static_onnx.nms.onnx” file.
In next step. I copied the “yolo4_1_3_416_416_static_onnx.nms.onnx” file in my Jetson Nano with JP4.6 and trying to execute and build .engine file following step 3.5 (generate Engine of fp16 mode). and I am getting the error below:
(By the way, these are the same steps that I followed when I used “libnvinfer_plugin.so.7.1.3” for earlier version of Jetpack to use YOLO V4 and it worked)